
Convergence: From "The Limit of Equations" to "The Limit of Growth"

In economics courses, most concepts often undergo “mathematical meaning - economic meaning - statistical meaning” three re-understandings. We often see the same thing in different places, but we rarely take the time to fully understand it in one go, for example, three calculation formulas.
This article will summarize the concept of “convergence” as it runs through these three stages (although the connections may seem weak, I still want to go through it all at once).
I. Advanced Mathematics: Limits and Convergence
Limits and convergence are essentially the same thing from the start.
Main reference: Tongji Edition “Advanced Mathematics”1, where convergence is introduced as a description of the state of a limit:
In the limit of a sequence (page 21, Volume I), the sequence $x_n$ converges to $a$, denoted as $\lim_{n \rightarrow \infty}{x_n=a}$.
In the limit of a function (page 33, Volume I), the function converges, denoted as $\small \lim_{n \rightarrow \infty}{f(x_n)}=\lim_{n \rightarrow x_0}{f(x)}$.
In the limit of a series (page 252, Volume II), $\small s=u_1+u_2+u_3+…u_i+…$ an infinite series converges if $\lim_{n \rightarrow \infty}{s_n=s}$, otherwise it diverges.
$$ \text{Convergence Classification} \begin{cases} \text{Content} \begin{cases} \text{Absolute Convergence} \ \text{Conditional Convergence} \end{cases} \ \text{Form} \begin{cases} \text{Pointwise Convergence} \ \text{Uniform Convergence} \end{cases} \end{cases} $$
Where series convergence is further divided into absolute convergence and conditional convergence; pointwise convergence and uniform convergence.
Absolute Convergence: If $\small \sum_{n=1}^{\infty}{|u_n|}$ converges, then $\small \sum_{n=1}^{\infty}{u_n}$ is absolutely convergent.
Conditional Convergence: If $\small \sum_{n=1}^{\infty}{|u_n|}$ does not converge, but $\sum_{n=1}^{\infty}{u_n}$ converges, then $\small \sum_{n=1}^{\infty}{u_n}$ is conditionally convergent.
Pointwise Convergence: $\small \exists{0<x<\delta},\forall\varepsilon>0, |f(x)-A|<\varepsilon$, $\small \exists{0<x<\delta},\forall\varepsilon>0, |f(x)-A|<\varepsilon$
Uniform Convergence: $\small \exists{0<|x_1-x_2|<\delta},\forall\varepsilon>0,|f(x_1)-f(x_2)|<\varepsilon$, $\small \exists{0<|x_1-x_2|<\delta},\forall\varepsilon>0,|f(x_1)-f(x_2)|<\varepsilon$
By the way, convergence radius, which is the range of $x$ values that allow the series $\small u_n(x)$ to converge.
Is there a shortcut for judging convergence or divergence? My advanced mathematics teacher mentioned a “humorous” method, which I also came across on Zhihu:
Look at these two characters, aren’t they both convergent and divergent?
II. Probability Theory: Law of Large Numbers and Central Limit Theorem
What you think of as “chance” is often embedded in “necessity.” Someone necessarily wins the lottery; it’s just that person chance is you.
Reference: Mao Shisong’s “Probability Theory and Mathematical Statistics”2, sequences of random variables have two modes of convergence: convergence in probability and convergence in distribution.
Convergence in Probability: $\bbox[#def,5px,border: 1px solid]{ x\stackrel{P}{\longrightarrow}c }$
For example, when flipping a coin, the initial frequency of heads may deviate greatly from $\frac{1}{2}$, but as the number of flips increases, the frequency approaches the probability. Frequency statistics have become one of the methods to determine probability3.
Various versions of the Law of Large Numbers, $\boxed{ Law of Large Numbers }$ essentially say the same thing: as the number of experiments $n$ increases, the probability of the deviation $\small \frac{S_n}{n}-P$ being greater than a predetermined value $\varepsilon$ decreases.
Whether it’s the Bernoulli (Bernoulli) Law of Large Numbers, Chebyshev’s Law of Large Numbers, Markov’s Law of Large Numbers, or Khinchin’s Law of Large Numbers, they all essentially describe the same thing4.
Convergence in Distribution: $\bbox[#def,5px,border: 1px solid]{ x\stackrel{F}{\longrightarrow}c }$
Strong convergence in distribution is pointwise convergence, while weak convergence removes discontinuities and only considers the continuous distribution of $F(x)$.
Denoted as $ \mathbb{P}(X_n\leqslant a)\to\mathbb{P}(X\leqslant a) $, which is $ \lim_{n\to\infty}F_n (x)=F (x)$.
The $\boxed{ Central Limit Theorem }$ states that under certain conditions5, the distribution function of the sum of independent random variables $Y_n=\sum_{i=1}^{n}{X_i}$ approaches a normal distribution.
Interesting knowledge about function distributions6
- Assume there is a random variable that follows a binomial distribution.
- When it tends to the limit, with the expectation equal to the variance, it becomes a Poisson distribution.
- The intervals between random variables follow an exponential distribution.
- The nth variable corresponds to the gamma distribution in the horizontal coordinate.
III. Economic Significance: Convergence Effect
Money ≠ Numbers, Operations ≠ Problems, Economics ≠ Mathematics
1. Convergence Hypothesis (Convergence)
From the资料 used by the teacher in the “Regional Economics” course 《Advanced Economic Geography》 (He Canfei著).
With the proposal of the Solow model, development economics researchers raised questions:
Since each economy has its own steady state and balanced growth path,
and at the same time, less developed economies grow quickly while advanced economies slow down,
the question is, will the economic growth of all economies converge in the end?
$$ \begin{cases} \beta\text{-convergence} \begin{cases} \text{Absolute Convergence} \ \text{Conditional Convergence} \ \text{Club Convergence} \end{cases} \ \sigma\text{-convergence} \end{cases} $$
$\beta$-convergence:
- $\boxed{\beta\text{ Absolute Convergence}}$ assumes that regardless of the initial conditions of the economy, due to the faster development of the weaker and slower development of the stronger, the economy will eventually converge to the same level. All we need is a little patience.
- $\boxed{\beta\text{ Conditional Convergence}}$ assumes that the growth rate of the economy is influenced by certain structural factors (such as population structure, endowments of factors, growth rates of factors), so different economies converge to different steady states, and the final outcomes of development differ.
- $\boxed{\text{Club Convergence}}$ assumes that within economic groups with initially similar levels of economic development and among richer country groups, there is conditional convergence within each group, but no signs of convergence between the two groups.
$\sigma$-convergence:
- $\boxed{\sigma\text{-convergence}}$ assumes that the standard deviation $\sigma$ between different economies is constantly decreasing.
2. Convergence Speed
It seems like a mathematical concept from real analysis, but I first learned it in Romer’s “Advanced Macroeconomics,” so I’ve categorized it under economics.
I looked it up on Wikipedia (Rate of convergence), which is mainly applied in algorithm optimization and deep learning fields.
If a sequence $x_k$ converges to $L$, the expression $\mu$ is the rate of convergence.
$$ \lim_{k\to\infty}\frac{|x_{k+1}-L|}{|x_k-L|^q}=\mu $$
When $q=1$ in the equation, it is linear convergence, where the convergence speed is the ratio of the numerical difference to the convergence point between times $t$ and $t+1$.
Imagine a race. We measure speed by comparing the distance from the starting point.
Convergence is like anxiously waiting for the school bell. We care about how long it will take to reach the endpoint.
 Absolute Convergence
Barro and Martin (1991)7 proposed the test equation for absolute $\beta$ convergence based on Baumol (1986)8.
$$ \small \frac{1}{T}\left[\log(y_{i,t+T}) - \log(y_{i,t})\right] = \alpha - \frac{(1 - e^{-\beta T})}{T} \log(y_{i,t}) + \varepsilon_i $$
Where $i$ represents the $i$th region, $t$ is the initial period, $t+T$ is the final period, $T$ is the length of the observation period, $y_{i,t}$ is the per capita GDP of region $i$ in period $t$, and $\beta$ represents the convergence speed. If $\beta > 0$, it indicates that the differences in economic development between regions will gradually disappear, eventually reaching the same steady state.
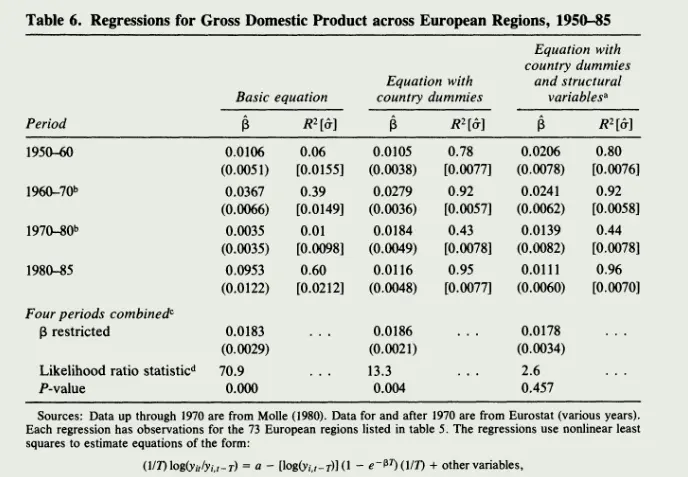
The above formula is derived from the neoclassical growth model (i.e., the Solow model).
Personally, I find that domestic descriptions of convergence regression variance are much clearer and more concise. Here, I refer to Peng Guohua (2005)9’s regression equation:
$$ g = c + \beta \ln y_0 + \varepsilon $$
Where $g$ is the growth rate, $c$ is the constant term, $y_0$ is the actual output, and $\varepsilon$ is the error term. When $\beta < 0$, it indicates that the growth rate $g$ is negatively correlated with the economic level $y_0$, consistent with our assumption that “high-level economies grow slower, while low-level economies grow faster.”
(2) Conditional Convergence
Barro and Martin (1992)10 proposed the test equation for conditional $\beta$ convergence based on the absolute $\beta$ convergence test equation:
$$ \small \frac{1}{T}\left[\log(y_{i,t+T}) - \log(y_{i,t})\right] = \alpha - \frac{(1 - e^{-\beta T})}{T} \log(y_{i,t}) + \lambda X_{i,t} + \varepsilon_{i,t} $$
The conclusions and parameter meanings are the same as those for absolute convergence, as conditional convergence implies that economic growth is related to the structural environment of the economy, hence the inclusion of $X_{i,t}$ as control variables.
The inconvenience of introducing control variables $X_{i,t}$ is that we have to study exogeneity again.
(3) Club Convergence
In groups with similar economic characteristics and similar growth paths, convergence exists within the group, but not between different economic groups. This phenomenon is called club convergence (Durlauf, 1995; Galor, 1996).
$$ \frac{1}{T}\left[\log(y_{i,t+T}) - \log(y_{i,t})\right] = \alpha + \beta \log(y_{i,t}) + \lambda D + \varepsilon_{i,t} $$
The variable meanings are the same as above, except that convergence is indicated only when $\beta < 0$, where $D_{i,t}$ is a dummy variable, i.e., grouping, such as all of East Asia following the same development path, or several cities developing as port cities.
An interesting study I found is modeling based on clustering criteria, such as using the “middle-income trap” as a clustering criterion11.
Du (2017) (who is from Shandong University) introduced a Stata package to perform the econometric convergence test and club clustering algorithm by Phillips and Sul (2007)1213.
The grouping basis idea is roughly as follows:
$$ \lim_{x \rightarrow +\infty} \frac{X_j}{X_i} \rightarrow 1 $$ For detailed mathematical derivations, please click on the hyperlinks to their names.
Regarding club clustering operations in Stata, there are excellent tutorials available on YouTube and GitHub.
I have translated and added details to his do file:
Note: Use
cdto adjust the Stata working environment (already noted in the do file comments)
|
|
2. Empirical Results (Examples)
China’s current empirical results basically satisfy $\sigma$ convergence14 and club convergence (classification is generally regional, such as eastern, central, and western regions)15. The standards of GDP, total factors, and industrial output basically lead to the same conclusions16.
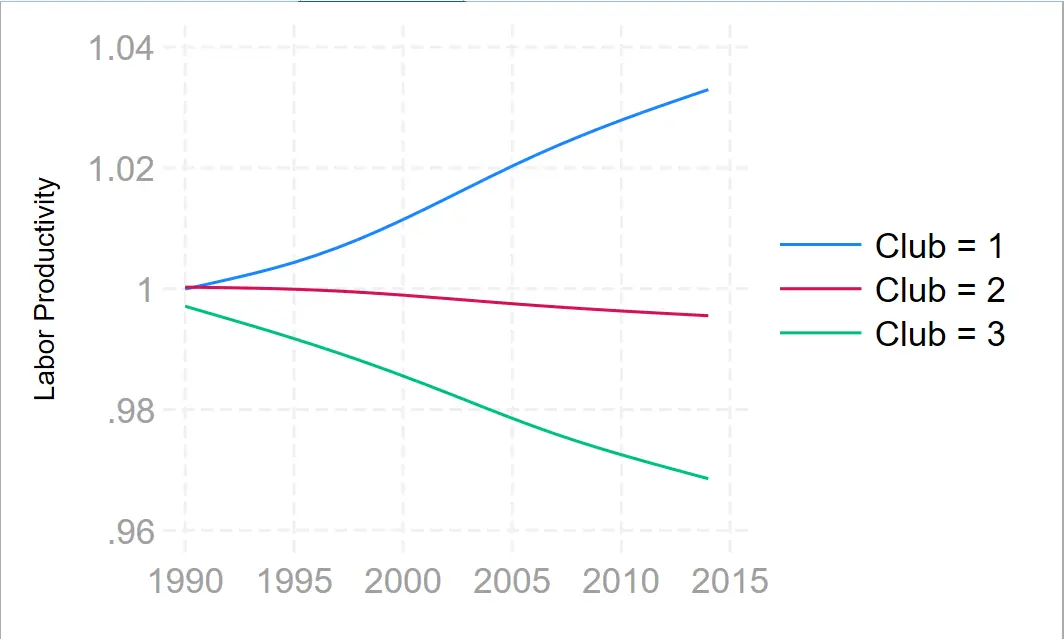
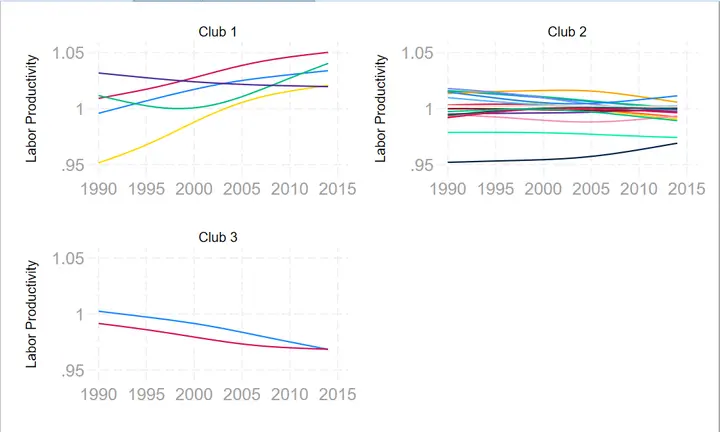
-
Personally, I think Tongji Edition’s calculus part is still quite good, but absolutely do not use its linear algebra part. The definitions, Tongji Edition’s directional derivatives differ from some mathematical analysis textbooks. ↩︎
-
Personally, I think the best domestic statistics textbook, especially in the probability theory section, is captivating. The mathematical statistics section is relatively less interesting. ↩︎
-
Other methods include geometric methods, subjective methods, and algebraic methods. ↩︎
-
If I were to explain each of these laws of large numbers individually, I honestly can’t remember them. ↩︎
-
I have forgotten what specific conditions they are; in machine learning applications, it seems quite difficult to satisfy. ↩︎
-
So I say, the probability theory textbooks for economics and management are not good; if you don’t look at statistics textbooks, you miss out on such a coherent understanding of knowledge points. So these distributions have evolved step by step. If you don’t know this development, you’d think they were sent from nowhere. ↩︎
-
Barro R J, Sala-i-Martin X, Blanchard O J, et al. Convergence across states and regions[J]. Brookings papers on economic activity, 1991: 107-182. ↩︎
-
Baumol, W. J. (1986). Productivity Growth, Convergence, and Welfare: What the Long-Run Data Show. The American Economic Review, 76 (5), 1072–1085. http://www.jstor.org/stable/1816469 ↩︎
-
Peng Guohua. China’s regional income disparity, total factor productivity, and convergence analysis[J]. Economic Research, 2005 (9): 11. DOI: CNKI:SUN: JJYJ. 0.2005-09-003. ↩︎
-
Barro R J, Mankiw N G, Sala-i-Martin X. Capital mobility in neoclassical models of growth[R]. National Bureau of Economic Research, 1992. ↩︎
-
Xu Yonghui, Li Yue, Deng Hongtu. Club convergence and the middle-income trap[J]. Modern Finance (Tianjin University of Finance and Economics Journal), 2022, 42 (11): 48-62. DOI: 10.19559/j.cnki. 12-1387.2022.11.004. ↩︎
-
Du, K. (2017). Econometric convergence test and club clustering using Stata. The Stata Journal, 17 (4), 882-900. ↩︎
-
Phillips, P. C., & Sul, D. (2007). Transition modeling and econometric convergence tests. Econometrica, 75 (6), 1771-1855. ↩︎
-
Lin Yifu, Liu Mingxing. China’s economic growth convergence and income distribution[J]. World Economy, 2003 (08): 3-14+80. ↩︎
-
Shen Kunrong, Ma Jun. China’s economic growth “club convergence” characteristics and cause analysis[J]. Economic Research, 2002 (01): 33-39+94-95. ↩︎
-
Tang Xuebing, Chen Xiushan. Convergence of economic growth in China’s eight major regions and its influencing factors analysis[J]. Journal of Renmin University of China, 2007 (01): 106-113. ↩︎