+++
Title = ’ 标题名'
Slug = ‘链接名’
date = 2024-10-29T18:52:19+08:00
Draft = true
Math= false
OutdatedInfoWarning = false
Lightgallery = true
FeaturedImage="/img/pythonGIS.zh-cn-20250524111143536.webp"
Tags = [“标签”,“ass” ]
Categories= [“Movies”,“test”]
Summary=’ 总结'
+++
类型:tip note bug abstract info success question warning failure danger example quote
VIDEO
裁判文书清洗手册
作者:滑翔闪
这个文档既是目前工作的汇报,也是一些经验的总结。
或许能方便后面的同学更快上手裁判文书的清洗工作。
希望未来的同学能重视工程技巧的优化总结与文档分享。
思考如何优化工程,优化团队协作,让积累和输出成为一种能力 。
世界不但需要输入,也需要输出,知识的分享与传递才是人类文明不断进步的纽带。
关于 AI 工具的推荐:
通义千问 :上下文记忆能力长 ,能让它改善长代码。
GPT :更了解 stata 的函数 。在我处理字符串变量时,通义千问经常用复杂的命令处理,通常还报错,而 GPT 知道很多 stata 的不常用函数,一行代码就可以轻松搞定。
deepseek :国内新秀。语言表达很不错。能很快理解使用者的意思。虽然 GPT 的代码能力更加优秀,但 deepseek 更能听懂要求,建议 deepseek 生产基础代码,gpt 进行优化。
关于裁判文书的网站
不建议去裁判文书网查询案例,反应卡顿,验证频繁
推荐北大法宝 和威科先行 (自带可视化和便捷查询)
💬
备注:裁判文书的清洗需要交替处理中文和数字。本文档会多提一些 python 和 stata 的常用正则表达式。
AI 虽然掌握了很多函数,但它不知道怎么组合。
谋篇布局的算法理解才是我们的最大优势。
提问时要替 AI 理顺代码的算法。
有了 AI 后——知道什么包能实现什么功能,在算法下有什么作用,比掌握细节更重要。
裁判文书资源
原始文本数据 :一堆 txt 文件。每一行是一条裁判文书信息,Txt 文件以 “万”作为文件名,因此下面使用整数部分的数字代表每个 txt 文件。
配套的文档是压缩包、文书字典、变量含义表格。
例子
提示 😍:每个 txt 文件都很大,一般软件打不开。个人推荐使用 EmEditor 软件查看。积极使用 EmEditor 软件查看例子,能让我们更好地了解乱码情况和裁判文书的书写规则,以便改进我们的文本处理代码。
Dta 数据 :前辈们清洗好的 stata 文件。拆分为了 ans 1—ans 83。格式刷 stata 的 .dta格式
例子
一套完整的清洗流程就是:
从原始的 txt 中筛选提取我们需要的信息,最终成为能导入 stata 使用的数据。
txt 文件的处理
Txt 的裁判文书大部分已经处理为了 json格式,python 读取其实较为方便。
其中,大部分裁判文书 txt 文件是下方的 s 系列命名结构:
重要的信息都在第三列,s*系列包含的数据结构当中
重要的信息都在第三列,s*系列包含的数据结构当中
但跑通了一到三份 txt 文件不等于能跑通所有。
⛔
Txt 的裁判文书还存在一些其他格式:
有些 txt 文件格式为 DocInfoVo 开头的。
有些 txt 文件格式为 title 开头的。
有些 txt 文件格式夹杂着 HTML 语言。
有些 txt 文件格式是纯粹的乱码。
有些格式中 s 系列和 DocInfoVo 格式混在一起,导致循环代码被打断。
因此处理时得考虑代码的兼容性和全面性 ,分开写处理代码,然后对这种 txt 文件处理两次。
例子
例子
一些建议
由于循环容易被打断,用 txt 进行处理处理时,建议参考如下逻辑:
1、将乱码的 txt(附在后文)和 s 系列的 txt 分开处理
2、原始文件为 txt,清洗处理后生成新的 cleaned_txt。
3、由于清洗循环命令容易被打断,最好多写一个命令:对比 txt 和 cleaned_txt 的文件名。
4、多写一个步骤:将处理完成的 txt 文档移动到另一个文件夹,修改报错代码后继续循环。
Python 默认读取文件的顺序是 txt 1 txt 10 text 111… 而不是 1、2、3…
乱码文档
不只是 s 系列格式的 txt 文件有:
例子
Python 例子 :提取案件号序列
思路
python 读取 txt 的 json 格式。
提取第三列 CourtInfo 数据。
例子
s 23 变量所有案件号,以此追踪一审二审再审终审 。
例如 (2016)沪0104民初33043号 ,其实就是一个裁判文书案件的身份证号。
正则表达式筛选:按照 (年份)初\终\再 号 的规则提取满足要求的字符串
1
pattern = r "[((]\d {4} [))][^号]*?(?:初|终|再)[^号]*?号"
提取后去除重、排除包含“['X', 'x', 'X', '执', '不动产', '-', '第']”的案件号。
如果继续使用这种方法提取,排除时最好加入 辖 。
这种案号也有辖初、辖再、辖终,但只表示法院在管理权上的划分。
(或许以后还有人能想到用这个特征做研究?👍)
1
exclusions = [ 'X' , 'x' , 'X' , '执' , '不动产' , '-' , '第' ]
排序,优先按照案号中的 (年份) 进行排序。 删除案号数量大于等于 5 的所有行。
一个案子最多是如下的顺序:
初审,不服申请上诉,再审,终审,不服再进行上诉,终审。
可以直接从初审跳到终审,终审后还有最后一次再审机会,再审结束后一般就不会更改了。
个人的排序逻辑:(此处最大的漏洞是我想不到怎么完美识别“再”案号的位置)
生成 m 1——m 4 四个变量 带有初的案号归类到 m 1,带有终的案号归类到 m 3。
带有再的情况:
如果只有初和再,再归类到 m 2
如果只再,我默认放在 m 4
如果同时有终、再,根据相对位置判断再是 m 2 还是 m 4。
后面发现:【辖终】会干扰顺序,所以先将包含辖的案号清除,然后和被其挤到 m 4 的【终】案号交换顺序。
这就是大数据最麻烦的点:
如果前面工作没有完美做好,后面返工成本会越来越高。 最糟糕的是——大数据总是很难穷尽所有乱码可能。
单个 txt 的处理
以下代码只针对 s 系列 命名的文档。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
import pandas as pd
from collections import OrderedDict
import json
import re
import os
# 读取数据
data = pd . read_csv ( "F:/桌面/裁判文书数据库/test/test.txt" , delimiter = ' \t ' )
# 查看前几行数据
print ( data . head ( 3 ))
# 假设 CourtInfo 列中包含 JSON 字符串
json_data = data [ 'CourtInfo' ]
# 解析 JSON 数据
def parse_json ( json_str ):
try :
return json . loads ( json_str )
except json . JSONDecodeError :
return None
# 应用解析函数
parsed_prac_c = json_data . apply ( parse_json )
# 将 JSON 字典转换为 DataFrame,并处理缺失值
json_df = pd . json_normalize ( parsed_prac_c . dropna ( how = 'all' ))
# 查看转换后的 DataFrame
print ( json_df . head ( 20 ))
# 正则表达式模式
pattern = r "[((]\d {4} [))]\s*.*?号"
# 使用findall提取所有匹配项
matches = json_df [ 's23' ] . apply ( lambda x : re . findall ( pattern , x ) if isinstance ( x , str ) else [])
# 查看转换后的 DataFrame
print ( matches . head ( 3 ))
print ( matches )
# 创建新的 DataFrame,将更新后的 's23' 列保存
matches_df = pd . DataFrame ({
's23' : matches
})
# 查看转换后的 DataFrame
print ( matches_df . head ( 10 ))
# print(matches_df)
# 选择要合并的列
selected_data_columns = []
selected_json_df_columns = []
# 合并选择的列
combined_df = pd . concat ([ data [ selected_data_columns ], json_df [ selected_json_df_columns ], matches_df ], axis = 1 )
def clean_text ( text ):
if isinstance ( text , list ):
text = ', ' . join ( text ) # 将列表转换为字符串,元素之间用逗号和空格分隔
if isinstance ( text , str ):
if text == "[]" :
return ''
cleaned_text = text . replace ( '[' , '' ) . replace ( ']' , '' ) . strip ()
return cleaned_text
return ''
# 切割并生成列名
def split_and_rename ( content ):
content = clean_text ( content )
split_content = content . split ( ', ' )
result = { f 'm { i + 1 } ' : split_content [ i ] . strip () for i in range ( len ( split_content )) if split_content [ i ] . strip ()}
return result
# 应用函数
expanded_df = combined_df [ 's23' ] . apply ( split_and_rename ) . apply ( pd . Series )
# 查看结果
# print("Expanded DataFrame:")
# 提取年份的函数
def extract_year ( text ):
match = re . search ( r '[((](\d {4} )[))]' , text )
return int ( match . group ( 1 )) if match else float ( 'inf' )
# 清洗和排序函数
def clean_and_sort ( row ):
# 过滤掉非字符串类型的值
filtered = [ item for item in row if isinstance ( item , str ) and not any ( keyword in item for keyword in exclusions )]
# 去除重复项并保持顺序
unique_items = list ( OrderedDict . fromkeys ( filtered ))
# 按年份排序
sorted_items = sorted ( unique_items , key = lambda x : extract_year ( x ))
return sorted_items
# 需要排除的关键字列表
exclusions = [ 'X' , 'x' , 'X' , '执' , '不动产' , '-' , '第' ]
# 筛选所有 m* 列
m_columns = [ col for col in expanded_df . columns if col . startswith ( 'm' )]
# 对每一行应用清洗和排序函数
def process_row ( row ):
# 获取 m* 列的内容
row_values = [ row [ col ] for col in m_columns ]
# 扁平化列表
flattened = [ item for sublist in row_values for item in ( sublist if isinstance ( sublist , list ) else [ sublist ])]
# 处理并排序
sorted_items = clean_and_sort ( flattened )
return sorted_items
# 应用到数据框的每一行
sorted_results = expanded_df . apply ( process_row , axis = 1 )
# 创建新的数据框
max_length = max ( sorted_results . apply ( len ))
sorted_df = pd . DataFrame ( sorted_results . tolist (), columns = [ f 'm_sorted_ { i + 1 } ' for i in range ( max_length )])
# 打印结果
print ( sorted_df . head ( 10 ))
# 合并到原数据
combined_df2 = pd . concat ([ combined_df , sorted_df ], axis = 1 )
# 查看结果
print ( combined_df . head ( 10 ))
# 检查 'm_sorted_5' 列是否存在,并删除非空行
if 'm_sorted_5' in combined_df2 . columns :
combined_df2_cleaned = combined_df2 [ combined_df2 [ 'm_sorted_5' ] . isna () | ( combined_df2 [ 'm_sorted_5' ] == '' )]
else :
# 如果列不存在,则保留原数据框
combined_df2_cleaned = combined_df2 . copy ()
# 打印结果
print ( combined_df2_cleaned . head ( 10 ))
# 获取所有 m_sorted_* 列的名称
m_sorted_columns = [ col for col in combined_df2_cleaned . columns if col . startswith ( 'm_sorted_' )]
# 过滤出索引大于等于 5 的列
columns_to_drop = [ col for col in m_sorted_columns if int ( col . split ( '_' )[ 2 ]) >= 5 ]
# 删除指定的列
combined_df2_cleaned = combined_df2_cleaned . drop ( columns = columns_to_drop , errors = 'ignore' )
# 打印结果以检查清理后的数据框
print ( combined_df2_cleaned . head ())
combined_df2 . to_csv ( 'F:/桌面/combined_df.txt' , sep = ' \t ' , index = False , quoting = 1 , quotechar = '"' )
批量处理
个人选择的批量处理思路是循环处理一个文件夹下面的所有文档。
循环容易被打断,建议写一个报错记录,和处理完一个文档便移动的命令。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
import pandas as pd
from collections import OrderedDict
import json
import re
import os
# 定义输入和输出文件夹路径
# 定义输入和输出文件夹路径
input_folder_path = "C:/Users/PC/Desktop/hzp_project/二审和一审/数据/"
output_folder_path = "C:/Users/PC/Desktop/hzp_project/二审和一审/清洗结果/"
# 如果输出文件夹不存在,则创建它
if not os . path . exists ( output_folder_path ):
os . makedirs ( output_folder_path )
# 遍历输入文件夹中的所有 .txt 文件
for filename in os . listdir ( input_folder_path ):
if filename . endswith ( '.txt' ):
input_file_path = os . path . join ( input_folder_path , filename )
output_file_path = os . path . join ( output_folder_path , filename )
# 读取数据
data = pd . read_csv ( input_file_path , delimiter = ' \t ' )
# 打印前3行数据以检查
print ( f "Processing file: { filename } " )
print ( data . head ( 3 ))
# 解析JSON字段
json_data = data [ 'CourtInfo' ]
def parse_json ( json_str ):
try :
return json . loads ( json_str )
except json . JSONDecodeError :
return None
parsed_prac_c = json_data . apply ( parse_json )
# 将解析后的JSON转换为DataFrame
json_df = pd . json_normalize ( parsed_prac_c . dropna ( how = 'all' ))
# 打印前20行以检查
print ( json_df . head ( 20 ))
# 定义匹配模式
pattern = r "[((]\d {4} [))]\s*.*?号"
# 查找匹配项
matches = json_df [ 's23' ] . apply ( lambda x : re . findall ( pattern , x ) if isinstance ( x , str ) else [])
# 打印前3行匹配结果以检查
print ( matches . head ( 3 ))
print ( matches )
# 将匹配结果转换为DataFrame
matches_df = pd . DataFrame ({ 's23' : matches })
# 打印前10行匹配结果DataFrame以检查
print ( matches_df . head ( 10 ))
# 选择要保留的数据列
selected_data_columns = []
selected_json_df_columns = []
# 合并原始数据、解析后的JSON数据以及匹配结果
combined_df = pd . concat ([ data [ selected_data_columns ], json_df [ selected_json_df_columns ], matches_df ], axis = 1 )
# 清洗文本函数
def clean_text ( text ):
if isinstance ( text , list ):
text = ', ' . join ( text )
if isinstance ( text , str ):
if text == "[]" :
return ''
cleaned_text = text . replace ( '[' , '' ) . replace ( ']' , '' ) . strip ()
return cleaned_text
return ''
# 分割并重命名函数
def split_and_rename ( content ):
content = clean_text ( content )
split_content = content . split ( ', ' )
result = { f 'm { i + 1 } ' : split_content [ i ] . strip () for i in range ( len ( split_content )) if split_content [ i ] . strip ()}
return result
# 展开匹配结果
expanded_df = combined_df [ 's23' ] . apply ( split_and_rename ) . apply ( pd . Series )
# 提取年份函数
def extract_year ( text ):
match = re . search ( r '[((](\d {4} )[))]' , text )
return int ( match . group ( 1 )) if match else float ( 'inf' )
# 清洗并排序函数
def clean_and_sort ( row ):
filtered = [ item for item in row if isinstance ( item , str ) and not any ( keyword in item for keyword in exclusions )]
unique_items = list ( OrderedDict . fromkeys ( filtered ))
sorted_items = sorted ( unique_items , key = lambda x : extract_year ( x ))
return sorted_items
# 排除关键词列表
exclusions = [ 'X' , 'x' , 'X' , '执' , '不动产' , '-' , '第' ]
# 获取所有m开头的列名
m_columns = [ col for col in expanded_df . columns if col . startswith ( 'm' )]
# 处理每一行
def process_row ( row ):
row_values = [ row [ col ] for col in m_columns ]
flattened = [ item for sublist in row_values for item in ( sublist if isinstance ( sublist , list ) else [ sublist ])]
sorted_items = clean_and_sort ( flattened )
return sorted_items
sorted_results = expanded_df . apply ( process_row , axis = 1 )
# 计算最大长度,并创建新的排序后的DataFrame
max_length = max ( sorted_results . apply ( len ))
sorted_df = pd . DataFrame ( sorted_results . tolist (), columns = [ f 'm_sorted_ { i + 1 } ' for i in range ( max_length )])
# 再次合并数据
combined_df2 = pd . concat ([ combined_df , sorted_df ], axis = 1 )
# 过滤条件
if 'm_sorted_5' in combined_df2 . columns :
combined_df2_cleaned = combined_df2 [ combined_df2 [ 'm_sorted_5' ] . isna () | ( combined_df2 [ 'm_sorted_5' ] == '' )]
else :
combined_df2_cleaned = combined_df2 . copy ()
# 打印清理后的前10行数据以检查
print ( combined_df2_cleaned . head ( 10 ))
# 获取所有m_sorted开头的列名
m_sorted_columns = [ col for col in combined_df2_cleaned . columns if col . startswith ( 'm_sorted_' )]
# 要删除的列名
columns_to_drop = [ col for col in m_sorted_columns if int ( col . split ( '_' )[ 2 ]) >= 5 ]
# 删除不需要的列
combined_df2_cleaned = combined_df2_cleaned . drop ( columns = columns_to_drop , errors = 'ignore' )
# 打印最终前几行数据以检查
print ( combined_df2_cleaned . head ())
# 保存到文件
combined_df2_cleaned . to_csv ( output_file_path , sep = ' \t ' , index = False , quoting = 1 , quotechar = '"' )
print ( "Processing complete." )
Python 例子 :提取法条和移动文件夹
法条数量可以衡量案件复杂度,法条本身也衡量了案件类型。
Txt 文档的 s 47 系列对应着文书的法条,里面是第二层 json 格式:
1
2
3
4
for clause in data :
fgmc = clause . get ( 'fgmc' , '' )
tkx = clause . get ( 'tkx' , '' )
match = re . search ( r '(第.*?条)' , tkx )
['s23', 's25', 's26', 's27'] 的中文字符加总就是裁判文书的正文字数。
“s7”: “案件号”,“s23”: “诉讼记录”,“s24”: “诉控辩”,“s25”: “事实”,“s26”: “理由”,“s27”: “判决结果”。
多个 txt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
import pandas as pd
import json
import re
import os
import glob
import logging
# 配置日志记录
logging . basicConfig ( level = logging . INFO , format = ' %(asctime)s - %(levelname)s - %(message)s ' )
# 明确指定输入文件夹和输出文件夹的路径
input_folder_path = "C:/Users/PC/Desktop/hzp_project/二审和一审/数据/"
output_folder_path = "C:/Users/PC/Desktop/hzp_project/二审和一审/清洗结果/"
log_folder_path = "C:/Users/PC/Desktop/hzp_project/二审和一审/日志/"
# 确保输出文件夹和日志文件夹存在
os . makedirs ( output_folder_path , exist_ok = True )
os . makedirs ( log_folder_path , exist_ok = True )
# 解析 JSON 数据
def parse_json ( json_str ):
try :
if isinstance ( json_str , str ):
return json . loads ( json_str )
elif isinstance ( json_str , list ):
return json_str
else :
logging . warning ( f "未知数据类型: { type ( json_str ) } " )
return None
except json . JSONDecodeError :
logging . warning ( f "JSON 解析失败: { json_str } " )
return None
# 计算中文字符数
def count_chinese_chars ( text ):
if pd . isnull ( text ):
return 0
return len ( re . findall ( r '[\u4e00-\u9fff\u0030-\u0039\u3000-\u303f\uff00-\uffef]' , str ( text )))
# 提取和格式化条款
def extract_clauses ( s47_data ):
formatted_clauses = []
for item in s47_data . dropna ():
data = parse_json ( item )
if data is not None :
clauses = set () # 使用集合去重
for clause in data :
fgmc = clause . get ( 'fgmc' , '' )
tkx = clause . get ( 'tkx' , '' )
match = re . search ( r '(第.*?条)' , tkx )
if match :
clauses . add ( f " { fgmc }{ match . group ( 1 ) } " )
formatted_clauses . append ( list ( clauses )) # 保存每行提取的条款
else :
formatted_clauses . append ([]) # 如果解析失败,则添加空列表
return formatted_clauses
# 处理单个文件
def process_file ( input_file , output_folder , log_folder , total_rows ):
# 初始化一个空的列表来存储错误信息
error_logs = []
def bad_line_handler ( bad_line ):
error_logs . append (( input_file , bad_line . line_num , bad_line . line ))
# 读取数据
try :
data = pd . read_csv ( input_file , delimiter = ' \t ' , on_bad_lines = bad_line_handler , engine = 'python' )
logging . info ( f "Read { len ( data ) } rows from file: { input_file } " )
except Exception as e :
logging . error ( f "Error reading file: { input_file } " )
logging . error ( f "Error message: { e } " )
return
# 过滤掉 CourtInfo 列以 "DocInfoVo" 开头或无法解析为 JSON 的行
data = data [ data [ 'CourtInfo' ] . apply ( lambda x : x . startswith ( '{"s1":' ) if pd . notnull ( x ) else False )]
data = data [ data [ 'CourtInfo' ] . apply ( lambda x : isinstance ( parse_json ( x ), dict ))]
logging . info ( f "Filtered out invalid rows from file: { input_file } " )
# 提取 JSON 数据
json_data = data [ 'CourtInfo' ]
# 应用解析函数
parsed_prac_c = json_data . apply ( parse_json )
logging . info ( f "Parsed JSON data from file: { input_file } " )
# 将 JSON 字典转换为 DataFrame,并处理缺失值
json_df = pd . json_normalize ( parsed_prac_c . dropna ( how = 'all' ))
logging . info ( f "Normalized JSON data from file: { input_file } " )
# 选取特定列
selected_columns = json_df [[ 's7' , 's23' , 's25' , 's26' , 's27' , 's47' ]] . copy () # 使用 .copy() 创建副本
# 计算 s26 列中“条”字的出现次数
selected_columns [ 'count_tiao' ] = selected_columns [ 's26' ] . apply ( lambda x : x . count ( '条' ) if pd . notnull ( x ) else 0 )
logging . info ( f "Calculated 'count_tiao' from file: { input_file } " )
# 计算 s23, s25, s26, s27 列的总字数
selected_columns [ 'total_chars' ] = selected_columns [[ 's23' , 's25' , 's26' , 's27' ]] . apply (
lambda row : sum ( count_chinese_chars ( x ) for x in row ), axis = 1
)
logging . info ( f "Calculated 'total_chars' from file: { input_file } " )
# 提取和格式化条款
unique_clauses = extract_clauses ( selected_columns [ 's47' ])
selected_columns [ 'unique_clauses' ] = unique_clauses # 使用 .loc 进行安全赋值
selected_columns [ 'clause_count' ] = [ len ( clauses ) for clauses in unique_clauses ] # 每行的条款数量
logging . info ( f "Extracted and formatted clauses from file: { input_file } " )
# 生成输出文件名
base_name = os . path . basename ( input_file )
output_file = os . path . join ( output_folder , f "cleaned_ { base_name } " )
# 将结果保存为 txt 文件
selected_columns [[ 's7' , 'count_tiao' , 'total_chars' , 'unique_clauses' , 'clause_count' ]] . to_csv ( output_file , sep = ' \t ' , index = False , quoting = 1 , quotechar = '"' )
logging . info ( f "Processed and saved to: { output_file } " )
# 汇报进度
processed_rows = len ( data )
logging . info ( f "已完成处理文件: { base_name } , 条目数: { processed_rows } / { total_rows } " )
# 保存错误日志
if error_logs :
log_file = os . path . join ( log_folder , f "error_log_ { base_name } .txt" )
with open ( log_file , 'w' , encoding = 'utf-8' ) as f :
for log in error_logs :
f . write ( f "File: { log [ 0 ] } , Line: { log [ 1 ] } , Content: { log [ 2 ] } \n " )
logging . info ( f "Error logs saved to: { log_file } " )
# 遍历输入文件夹中的所有文件
all_files = glob . glob ( os . path . join ( input_folder_path , "*.txt" ))
total_files = len ( all_files )
processed_files = 0
if not all_files :
logging . warning ( "No files found in the input folder." )
else :
for input_file in all_files :
processed_files += 1
# 汇报当前处理的文件进度
logging . info ( f "正在处理文件: { input_file } ( { processed_files } / { total_files } )" )
process_file ( input_file , output_folder_path , log_folder_path , total_files )
移动 txt
因为代码循环非常容易被打断,我建议设置三个文件夹 :
原始文件夹存放原始数据,
结果文件夹存放处理完成的数据,统一改为 cleaned_* 的 txt 名字,
清洗完成的文件夹:把清洗完成的原始数据放到这里,便于循环打断后继续开始,
因此本代码的逻辑就是对照清洗完成的文件夹 和原始文件夹 ,将名字有对应的 txt 文档进行移动。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import os
import shutil
# 定义文件夹路径
source_folder = r 'F:/桌面/测试/清洗结果'
data_folder = r 'F:/桌面/测试/数据'
cleaned_folder = r 'F:/桌面/测试/完成提取'
# 获取源文件夹中的所有.txt文件名(不含路径),并去除前缀 "cleaned_",同时去除所有多余空格并转换为小写
def standardize_filename ( filename ):
return '' . join ( filename . split ()) . lower ()
# 获取源文件夹中的文件名
source_files = [ f for f in os . listdir ( source_folder ) if f . startswith ( 'cleaned_' ) and f . endswith ( '.txt' )]
standardized_source_files = { standardize_filename ( f [ 8 :]): f for f in source_files }
# 获取数据文件夹中的文件名
data_files = [ f for f in os . listdir ( data_folder ) if f . endswith ( '.txt' )]
standardized_data_files = set ( standardize_filename ( f ) for f in data_files )
# 找出数据文件夹中与源文件夹中相同的文件
common_files = standardized_source_files . keys () & standardized_data_files
# 移动相同的文件到清洗完成文件夹
for filename in common_files :
original_filename = standardized_source_files [ filename ]
source_path = os . path . join ( data_folder , original_filename . replace ( 'cleaned_' , '' ))
destination_path = os . path . join ( cleaned_folder , original_filename . replace ( 'cleaned_' , '' ))
# 确保目标文件夹存在
os . makedirs ( os . path . dirname ( destination_path ), exist_ok = True )
shutil . move ( source_path , destination_path )
print ( f "Moved: { source_path } -> { destination_path } " )
print ( "Process completed." )
例子 : 裁判文书索引重新排序
初审案号最早的排在前(m_sorted_1)
终审案号最晚的排在后(m_sorted_3)
再审案件按照“终审前最早、终审后最晚”安排(m_sorted_2, m_sorted_4)
其余案号按时间顺序补充空位(m_sorted_5)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
import pandas as pd
from datetime import datetime
def parse_date ( year_str , month_str ):
"""将年份、月份字符串转换为日期对象,若转换失败返回 None""" try :
year = int ( year_str )
month = int ( month_str ) if month_str and month_str . strip () != "" else 1
return datetime ( year , month , 1 )
except Exception :
return None
def reorder_row ( row ):
# 要一起移动的额外字段列表(除了 m_sorted_i 之外的其它关联变量)
extra_fields = [ 'court' , 'court_name' , 'jud_year' , 'jud_month' , 'win' , 'judge_am' , 'judge_fin' ]
entries = []
# 遍历原有 5 组数据,构造每组条目(只有当 m*_judge_am 和 m*_jud_year 均有值时认为该组有效)
for i in range ( 1 , 6 ):
judge_am = row . get ( f "m { i } _judge_am" )
jud_year = row . get ( f "m { i } _jud_year" )
if pd . isna ( judge_am ) or pd . isna ( jud_year ) or judge_am == "" or jud_year == "" :
continue
case_str = row . get ( f "m_sorted_ { i } " )
if not case_str or pd . isna ( case_str ):
continue
jud_month = row . get ( f "m { i } _jud_month" )
dt = parse_date ( jud_year , jud_month )
# 判断案号类型
if "初" in case_str :
typ = "chu"
elif "终" in case_str :
typ = "zhong"
elif "再" in case_str :
typ = "zai"
else :
typ = "other"
# 收集其它相关字段
fields_data = {}
for field in extra_fields :
col_name = f "m { i } _ { field } "
fields_data [ field ] = row . get ( col_name , "" )
entry = {
"orig_index" : i , # 原来的组号
"case" : case_str , # 案号字符串
"date" : dt , # 转换后的日期(可能为 None)
"type" : typ , # 案号类型:chu / zhong / zai / other
"fields" : fields_data
}
entries . append ( entry )
# 若没有有效条目,则返回所有新组为空
if not entries :
return pd . Series ({ f "m_sorted_ { i } " : "" for i in range ( 1 , 6 )})
# 定位“初”:从所有包含“初”的条目中取日期最早的
chu_entries = [ e for e in entries if e [ "type" ] == "chu" and e [ "date" ] is not None ]
initial_entry = min ( chu_entries , key = lambda e : e [ "date" ]) if chu_entries else None
# 定位“终”:从所有包含“终”的条目中取日期最大的
zhong_entries = [ e for e in entries if e [ "type" ] == "zhong" and e [ "date" ] is not None ]
terminal_entry = max ( zhong_entries , key = lambda e : e [ "date" ]) if zhong_entries else None
# 获取所有“再”的条目
zai_entries = [ e for e in entries if e [ "type" ] == "zai" and e [ "date" ] is not None ]
# 初始化新排序位置字典,表示最终放置在 m_sorted_1~m_sorted_5 中的条目
new_positions = { 1 : None , 2 : None , 3 : None , 4 : None , 5 : None }
# m_sorted_1 始终放“初”案
if initial_entry :
new_positions [ 1 ] = initial_entry
if terminal_entry :
# 如果存在终案,则 m_sorted_3 固定放终案
new_positions [ 3 ] = terminal_entry
# 分组:终案之前的“再”
re_before = [ e for e in zai_entries if e [ "date" ] < terminal_entry [ "date" ]]
# 分组:终案之后的“再”
re_after = [ e for e in zai_entries if e [ "date" ] > terminal_entry [ "date" ]]
# 日期早于终案的“再”中取最早的放入 m_sorted_2 if re_before:
new_positions [ 2 ] = min ( re_before , key = lambda e : e [ "date" ])
# 日期晚于终案的“再”中取最晚的放入 m_sorted_4 if re_after:
new_positions [ 4 ] = max ( re_after , key = lambda e : e [ "date" ])
else :
# 如果不存在终案,即只有“初”与“再”
zai_sorted = sorted ( zai_entries , key = lambda e : e [ "date" ])
if len ( zai_sorted ) == 1 :
new_positions [ 2 ] = zai_sorted [ 0 ]
elif len ( zai_sorted ) >= 2 :
# 最早的放入 m_sorted_2,最晚的放入 m_sorted_4 new_positions[2] = zai_sorted[0]
new_positions [ 4 ] = zai_sorted [ - 1 ]
# 将剩余未分配的条目(包括类型为 other 或未被选中的其他)按日期排序后填入剩余空位(例如 m_sorted_5)
assigned_indices = { e [ "orig_index" ] for e in new_positions . values () if e is not None }
remaining = [ e for e in entries if e [ "orig_index" ] not in assigned_indices ]
remaining_sorted = sorted ( remaining , key = lambda e : e [ "date" ] if e [ "date" ] is not None else datetime . max )
for pos in [ 2 , 5 ]:
if new_positions [ pos ] is None and remaining_sorted :
new_positions [ pos ] = remaining_sorted . pop ( 0 )
# 构造返回的 Series:按新的组号 1~5 写入 m_sorted_i 与对应的关联字段
result = {}
for new_group in range ( 1 , 6 ):
if new_positions [ new_group ]:
entry = new_positions [ new_group ]
result [ f "m_sorted_ { new_group } " ] = entry [ "case" ]
for field in extra_fields :
result [ f "m { new_group } _ { field } " ] = entry [ "fields" ] . get ( field , "" )
else :
result [ f "m_sorted_ { new_group } " ] = ""
for field in extra_fields :
result [ f "m { new_group } _ { field } " ] = ""
return pd . Series ( result )
# 读取数据(注意路径中使用原始字符串防止反斜杠转义问题)
df = pd . read_csv ( r "C:\Users\PC\Desktop\案号排序.txt" , sep = "," , dtype = str )
# 对每一行调用 reorder_row,得到重新排序后的 m* 系列数据
df_new = df . apply ( reorder_row , axis = 1 )
# 将重新排序后的变量更新回原 DataFrame(包括 m_sorted_1~m_sorted_5 及各组的关联字段)
for col in [ f "m_sorted_ { i } " for i in range ( 1 , 6 )]:
df [ col ] = df_new [ col ]
for new_group in range ( 1 , 6 ):
for field in [ 'court' , 'court_name' , 'jud_year' , 'jud_month' , 'win' , 'judge_am' , 'judge_fin' ]:
col_name = f "m { new_group } _ { field } "
df [ col_name ] = df_new [ col_name ]
# 保存结果到新文件
df . to_csv ( r "C:\Users\PC\Desktop\结果_案号排序.txt" , index = False )
dta 数据的匹配
关于案号
裁判文书的案号分为裁定文书、判决文书、其他文书(监督、执行、保证….)
裁定文书是审判程序上的问题,例如这个问题不该xx法院管,移交到xx法院去。
判决文书是实体问题,也就是判决的最终结果。
注意!判决文书和裁判文书是可能共享一个案号的!
同时在这里分享一些个人看到的奇葩裁判文书案号,有一些奇怪的符号可能是别人用过了然后再加符号作为区分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2018()皖02民终1098号
2016湘06民终2392号
((2017)豫0481民再10号
一(2017)粤0605民初10499号
(2015)芙民初字第7479、7601号
(2015)芙民初字第7478.7603号
(2019)粤0305民初1382号-1429号
(2019)鲁1724民初195号- 018)
苏0509民初6820号
loz2016loz赣1030民初220号
一亿二千三百四十五万(2016)粤0605民初14359号
(2018)土地承包经营权转让浙0523民初2386号
2016闽0525民初3798号2016闽0525民初3798号
(空一行行距15磅)(2014)滨港民初字第307号
由于中英文括号的问题,建议可以去除括号,但是不建议采用只保留中文和数字的筛选方式,很多时候短横线神秘字符也有标识作用。
个人匹配的筛选如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
sort case_wid
drop if case_wid == ""
foreach var of varlist case_wid {
* 去除空格变量、括号、其他符号
replace ` var ' = ustrregexra(`var' , "[^\p{L}\p{N}]" , "" )
}
sort case_wid
gen case_length = strlen ( case_wid )
summarize case_length
drop if case_length > 66
drop case_length
标识的去重
Txt 提取完成后,就是转化为 .dta 匹配到 ans*.dta 中。
案号 是理论上的唯一标识,但实际上可能出现重复的情况。
这时候建议使用以下逻辑,先历遍所有变量,生成非空数值总数,去重,在案号的重复行间保留非空数值最多的一行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
* 标记重复的 case_wid , 并计算每组的数量
bysort case_wid : gen dup_count = _N
replace dup_count = . if _n > 1 // 可选 : 只保留第一次出现的计数
* 创建一个包含所有要检查的变量的局部宏
local varlist var1 var2
* 使用循环创建标志变量
foreach var of local varlist {
gen flag_ ` var ' = cond(missing(`var' ), 0 , 1 )
}
* 计算每行中非空值的数量
egen non_missing = rowtotal ( flag * )
* 对每个 case_wid 按非空变量数量降序排序 , 并标记保留的观测值
bysort case_wid ( non_missing ): gen keep = ( _n == _N )
* 清理临时变量
capture drop flag *
* 删除重复值 , 保留非空变量最多的行
drop if ! keep
* 清理辅助变量
drop dup_count non_missing keep
* 保存处理后的文件 , 覆盖原有文件
save "`input_file'" , replace
}
索引值的去重
1
2
3
4
5
6
7
8
9
10
* 对第二个变量,若与第一个变量相同则清空
replace m_sorted_2 = "" if m_sorted_2 == m_sorted_1
* 对第三个变量,若与前面任一变量相同则清空
replace m_sorted_3 = "" if m_sorted_3 == m_sorted_2 | m_sorted_3 == m_sorted_1
* 对第四个变量,若与前面任一变量相同则清空
replace m_sorted_4 = "" if m_sorted_4 == m_sorted_3 | m_sorted_4 == m_sorted_2 | m_sorted_4 == m_sorted_1
* 对第五个变量,若与前面任一变量相同则清空
replace m_sorted_5 = "" if m_sorted_5 == m_sorted_4 | m_sorted_5 == m_sorted_3 | m_sorted_5 == m_sorted_2 | m_sorted_5 == m_sorted_1
文本匹配标识的格式转化
ans*.dta 系列的文本格式都是 strL,含义为长字符串。Stata 的字符串匹配只能选择有具体长度的字符串格式,我们可以通过字符截取来改变变量格式。
🔊 重要:注意,英文字符的占位符和中文字符的占位符是不同的。
例如“民初 730 号”,虽然只是六个字符,但可能实际上占了 15 个位置。
如果我们只截取 6 个长度,变量就会变成乱码。
个人观察到的案号占位符最长大概是 39 个位置,个人为了稳健直接选择的截取 88 个字符符号。
这也意味着: 我们需要在清理掉文本中的奇怪符号以后再转化。
例如有些法院名字是"广西壮族自治区柳州市鱼峰区人民法院"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 截取字符
gen judge_fin2 = substr ( judge_fin , 1 , 45 )
gen court_name2 = substr ( court_name , 1 , 88 )
drop judge_fin court_name
rename judge_fin2 judge_fin
rename court_name2 court_name
# 大于特定字符数量,例如66,的案号清洗为空值
foreach var of varlist s7 m_sorted_1 m_sorted_2 m_sorted_3 m_sorted_4 {
gen case_length = strlen ( ` var ')
summarize case_length
replace ` var ' = "" if case_length > 66
drop case_length
}
匹配命令的选择
多(基础表格)对一时 :merge 命令直接使用。
一(基础表格)対多时 :例如 txt 有一些重复记录,但是不同行的空缺值不同。我们可以使用 merge 的追加匹配 update nogen force,只在这一行有空缺时,将空缺值的变量匹配上去;非空缺的部分则不更改。
1
2
3
4
5
6
7
8
clear
forvalues j = 1/83 {
use "D:\数据合集\原始数据\ans`j'.dta", clear
merge 1:m case_wid_str using "C:\Users\PC\Desktop\hzp_project_re\一审二审数据匹配\排序\面板数据\all.dta", update nogen force
drop if case_wid == ""
duplicates drop case_wid_str , force
save "C:\Users\PC\Desktop\hzp_project_re\一审二审数据匹配\排序\面板数据\ans`j'.dta", replace
}
多对多(基础表格)匹配时:此时使用 merge 不再合适,推荐 joinby
详细可参考 Stata命令:joinby VS merge m:m常见问题
循环匹配命令
当我们写循环匹配命令时,数字可能是间断点,例如 data 1、data 3、data 5、data 7…
可以选择使用 python 直接更改文件名字按顺序排序,但容易破坏命名含义。
这里提供个人写的 stata 自然数循环命令:
当然,其实可以通过扫描文件夹下面的文件名识别所有文件,然后循环,但是如果是存在一些文件需要手动排除可以参考下这个代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
* 定义排除列表
global exclude_list 22 50 54 58 105
* 初始化 valid_files 变量
global valid_files
* 循环遍历文件编号范围,并检查是否在排除列表中
forvalues i = 1/119 {
local is_excluded 0
foreach excl in $exclude_list {
if `i' == `excl' {
local is_excluded 1
break
}
}
if !`is_excluded' {
global valid_files $valid_files `i'
}
}
* 显示有效的文件编号
display "Valid file numbers: $valid_files"
* 循环处理有效的文件编号
foreach i of global valid_files {
*写入自己的循环匹配代码
}
但是如果遇到的完全乱码名字的文件怎么办?在文件名没有空格或者特殊符号的情况下,可以读取文件名存入 local 再加入循环。这个也是更加泛用的代码。
例如以下乱码:
如图
我们可以利用 stata 的 fs 包读取所有名字
然后使用 local 直接储存名字进行循环
循环过程中可以嵌套一层循环,使得新文件按照顺序命名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
* ==============================
* 配置路径
* ==============================
local path "F:\数据合集\刑事案件"
local outpath "F:\数据合集\刑事案件简洁"
cd "`path'"
fs "*.csv" , all
* ==============================
* 手动生成 CSV 文件列表到 local
* ==============================
local files " 080hfjsviunvohos.csv 749baig9gvbblcn.csv 97sytdv97goushd.csv 08cdhas0hvihikd.csv 7839yhcudaboce.csv 98ya08chiahnicn.csv 0s87d0hvcinowbv.csv 788tgd9cayh0c-9.csv 9a7gtdc97g08a0a.csv 1368bcohucg970.csv 797fshonlsnlfu98.csv 9f79sghuvjksbklk.csv 236797rbvlsbvoo.csv 79d7goadbco9hki.csv 9s7fhosivnlsnlnffr.csv 2489ndsujbovbo.csv 79s7dhnofnvlbns.csv a97dyc8udv8+hds9.csv 28638bvbsa7f93.csv 80sdhv08uisnvoh.csv i7sdhvu9hbosdv8.csv 2937hvoushcv8h.csv 89hdoshvoinsnnlj.csv oa7gc7agbkd78ad.csv 4689578yhkjsbd.csv 89s0fjisn7vgiskub.csv oc8ahhc89ha98g.csv 4790r8hvobosh7.csv 8y08h0chaicnil8o.csv os8dvyh089shdvi.csv 4792794bvoshc8.csv 94573hvsoidhv9y.csv s8oyvf08s09vu08.csv 479hu5nnv89007.csv 9473hgnvov9h7s.csv u8ca0hc80ha00a.csv 4927bvogf92h011.csv 97atcg97ga0hc08.csv ughdso8h98989.csv 739g4foh8hv991.csv 97sgvc98dshv08.csv "
* ==============================
* 循环处理每个文件
* ==============================
* 初始化计数器
local i = 1
* 循环处理每个文件
foreach f of local files {
di "Processing file `i': `f'"
* 导入 CSV
import delimited "`f'" , clear varnames ( 1 ) encoding ( utf8 )
* 数据清洗
* 处理部分
* 保存为数字顺序的 DTA 文件
save "`outpath'/`i'.dta" , replace
* 计数器 + 1
local ++ i
}
匹配速度的优化
正常匹配,应该是将 119 个 txt 转化的 dta 匹配,嵌套循环匹配到 ans 1-ans 83 上去。
如果直接嵌套循环匹配,可能需要 4 到 5 天。
匹配耗时过长的原因在于每一次嵌套循环的文件读取时间太长了,而且不同文件之间有重复值。
建议先将 119 个 dta 文件使用 append 命令纵向匹配到一起,然后循环匹配到 ans 1 到 ans 83 上去,这样最多只需要 2 天即可完成全部匹配。
💬 备注:办公室电脑是 stata MP 版本,这个版本的特性是“计算速度根据电脑的核来分配资源”。目前 cpu 有足足 16 核,个人处理过的最大量峰值是 60 g。基本没有问题,只需要耐心等待处理过程中的卡顿。
dta 数据的清洗
常用文本处理函数
去除空格
例如裁判长(法官)变量,会出现以下情况 四川 大学, 四川大学,四 川 大 学。
不同网站的空格符号并不相同,建议使用以下函数:
* 移除所有特殊字符,包括不可见字符、空白和标点符号
1
replace judge_fin = ustrregexra(法官名字变量, "[^\p{L}\p{N}]+", "")
筛选特定字符
如果变量中含有特定字符则保留
1
keep if strpos ( var , "民初" ) > 0
如果有两个变量,例如一个是规范的省份变量 a(四川省,内蒙古自治区),另外一个是不规范的省变量 b(四川,内蒙古)。如果要判断 a 变量是否包含了 b 变量,则可以使用:
1
gen localed = strpos(a, b) > 0
去除特殊字符
Ans 1 到 ans 83 的文本变量夹杂着各种非中文符号,可以使用以下函数去除:
以下是个人筛选出的乱码符号。
💬 备注:为什么要坚持排除法,而不选择只保留中文字符? 因为个人尝试时,发现部分中文变量会因此变成乱码。
1
2
3
4
5
6
7
# 定义需要移除的符号列表(包括空格)
local symbols "ⅩⅩⅩ X ? ; ;, 《 》 . + ( ) ( ) & # 1 2 3 4 5 6 7 8 9 0 & A-Z a-z ;? * ︰ ++ . XX XXX ______ ` - + BRR H imestimes jzwjzwnjzwnjzwjzwnjzwnjzwnjzwjzwjzwjzwnjzwnjzwnjzwjzwnjzwnj jzwnjzwjzwjzwnjzwnjzwnjzwnjzwnjzwjzwjzwjzwnjzwjzwnjzwjzwj spemsp sp emsp ;; * XX XXX X XXX"
* 遍历符号列表并移除每个符号及空格
foreach s of local symbols {
replace judge_fin = subinstr(judge_fin, "`s'", "", .)
}
论文标签
有些时候,stata 数据只有变量名,同时另外有一个 excel 表格储存 label 值。
如何读取 excel 然后自动批量生成 labal vars name 呢?
1
2
3
4
5
6
7
8
9
10
11
12
* 导入 Excel 对照表
clear
import excel "基本情况代码对照表.xlsx" , ///
sheet ( "支出1编码对照" )
rename B varname
rename A varlabel
* 生成命令(注意 compound quotes )
gen cmd = "label variable " + varname + " `" + ` """' + varlabel + `""" ' + "' "
outsheet cmd using " 变量标签命令 . txt ", noquote replace
这样就会生成一个文件,储存所有 stata 对应的标签化命令。
一切代码在自动化和透明度都有个取舍,个人比较偏好这种有中间产物的流程,便于检查和修正。
正则表达式提取
字符筛选
以裁判长文本变量为例子,
明明变量应该是一个名字,结果出现了一个段落
张三人民委托、张三于 2014 年进行审判、张三人民审判员进行裁决、张三代理裁判长进行庭审、张三李四熟记员进行开庭……
再举例子——法院变量
先使用字符长度筛选例子,查看文本格式:
1
2
* 列出字符长度大于 14 的变量行
list var if ustrlen ( judge_fin ) >= 14
然后根据情况只保留特定字符 。
⛔ 警告:注意顺序!
例如有以下组合
张三于 2014 年进行庭审
张三代理 审判长于 2014 年进行庭审
在该变量包含"庭审"两个字时,我们应该先都保留“于”以前的字符,再保留"代理"以前的字符。
条件筛选最好找两个字的特征词,这样叫“于庭审”的法官名字几乎不可能出现。
个人使用的顺序,仅供参考:
1
2
3
4
5
6
7
8
9
10
11
12
13
replace judge_fin = ustrregexra(judge_fin, "人民陪审员.*", "") if strpos(judge_fin, "人民陪审员") > 0
replace judge_fin = ustrregexra(judge_fin, "审判员.*", "") if strpos(judge_fin, "审判员") > 0
replace judge_fin = ustrregexra(judge_fin, "独任.*", "") if strpos(judge_fin, "独任") > 0
replace judge_fin = ustrregexra(judge_fin, "陪审员.*", "") if strpos(judge_fin, "陪审员") > 0
replace judge_fin = ustrregexra(judge_fin, "代理.*", "") if strpos(judge_fin, "代理") > 0
replace judge_fin = ustrregexra(judge_fin, "书记员.*", "") if strpos(judge_fin, "书记员") > 0
replace judge_fin = ustrregexra(judge_fin, "助理.*", "") if strpos(judge_fin, "助理") > 0
replace judge_fin = ustrregexra(judge_fin, "审判长.*", "") if strpos(judge_fin, "审判长") > 0
replace judge_fin = ustrregexra(judge_fin, "人民.*", "") if strpos(judge_fin, "人民") > 0
replace judge_fin = ustrregexra(judge_fin, "二.*", "") if strpos(judge_fin, "年") > 0
replace judge_fin = ustrregexra(judge_fin, "适用.*", "") if strpos(judge_fin, "适用") > 0
replace judge_fin = ustrregexra(judge_fin, "于.*", "") if strpos(judge_fin, "开庭") > 0
replace judge_fin = ustrregexra(judge_fin, "对.*", "") if strpos(judge_fin, "审理") > 0
由于爬虫有时候遇上网站加密,爬虫结果是 陈*,,完成以上清洗后只剩下 陈,删除单个字符行的函数命令是:
1
2
*删除只有一个字的,例如本来是*陈
drop if ustrregexm(judge_fin, "^[\p{Han}]$")
数字提取
例如数据显示 2.34435元(需要是字符串变量),我们只想单独提取数字,可以使用以下代码。
1
2
gen num_var = .
replace num_var = real ( regexs ( 1 )) if regexm ( str_var , "([0-9]+\.[0-9]+|[0-9]+)" )
顺便一提,如果没有 real(regexs(1)) 这个参数则表示判断,只会返回 0 和 1,代表不符合或者符合格式。
1
replace num_var = regexm ( str_var , "([0-9]+\.[0-9]+|[0-9]+)" )
dta 时间修正
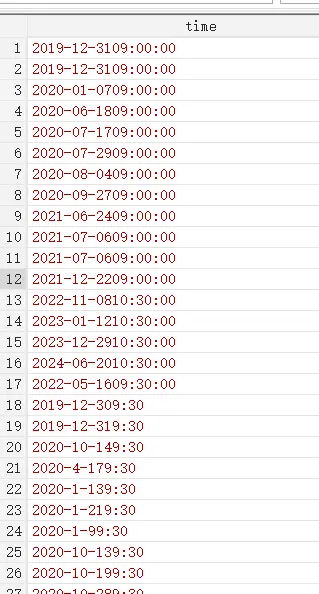
在师门的招投标中,很多时间格式是混乱的。
例如标准的两种:
2019-12-31 09:00:00、
2019/12/30 09:30
但是也会出现 20220516 09:30:00、2022051609:30:00、2022051609:30
例如缺少秒、月份位置写成 4 而不是 04。
如图
下面的代码集中处理了这套时间编码。
一些中文符号转英文的预处理。
在日期和时间之间没有空格时(例如 2022051609:30:00),如果范围在对应年月内(比如 0-31)则优先取两位数,超过范围了则取前面的个位数。
最后兼容各种格式的时间提取。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
/*-----------------------------------------
日期提取转换方案(紧凑格式增强版)
版本:2.6
最后更新:2024-06-27
-----------------------------------------*/
version 17
clear all
set more off
use "F:\桌面\test.dta", clear
keep time
*===============================
* 预处理阶段(增强)
*===============================
// 基础清理
replace time = ustrtrim(time)
replace time = subinstr(time, char(92), "-", .)
replace time = subinstr(time, ":", ":", .)
replace time = subinstr(time, " ", "", .)
*===============================
* 新增紧凑格式识别模块
*===============================
// 识别YYYYMMDD-格式(核心改进)
gen str8 compact_date = ""
replace compact_date = substr(time, 1, 8) ///
if ustrregexm(time, "^\d{8}-") // 严格匹配8位数字+连字符格式
// 分离紧凑格式数据
preserve
keep if compact_date != ""
gen date_stata = date(compact_date, "YMD")
format date_stata %tdCCYY-NN-DD
tempfile compact
save `compact'
restore
// 处理非紧凑格式数据
keep if compact_date == ""
drop compact_date
*===============================
* 原有处理流程(优化)
*===============================
// 统一分隔符处理
foreach s in "." "_" "/" {
replace time = subinstr(time, "`s'", "-", .)
}
// 日期部分提取
gen str50 date_part = ustrregexs(1) if ustrregexm(time, "(\d{4}-\d{1,2}-\d{2,})[^\d]")
replace date_part = time if missing(date_part)
// 智能日期处理
gen str4 year = ustrregexs(1) if ustrregexm(date_part, "^(\d{4})-\d+")
gen str2 month = ustrregexs(1) if ustrregexm(date_part, "-(\d{1,2})-")
gen str5 raw_day = ustrregexs(1) if ustrregexm(date_part, "-(\d+)$")
replace month = cond(strlen(month) == 1, "0" + month, month)
replace month = "12" if real(month) > 12
gen str2 day = substr(raw_day,1,2)
replace day = substr(day,1,1) if real(day) > 31
replace day = "31" if real(day) > 31
replace day = "0" + day if real(day) < 10 & strlen(day) == 1
replace date_part = year + "-" + month + "-" + day
drop year month raw_day day
gen date_stata = date(date_part, "YMD")
replace date_stata = date(ustrregexra(time, "[^0-9]", ""), "YMD") if missing(date_stata)
*===============================
* 合并处理结果
*===============================
append using `compact'
*===============================
* 后处理与验证
*===============================
format date_stata %tdCCYY-NN-DD
提醒
建议先将 stata 数据导出为 csv 格式。
最大的问题是乱码 。
如图
😨 注意:一定要保证CSV 文件默认格式刷 UTF-8 ,然后进行处理。
Python 例子 : 提取上诉法官过去和现在的特征均值
例子 3 是逐行匹配,但是这样处理实在是太慢了。
现在我想要这样处理:
提取法官经历上诉前的 20 个案子,然后求罚款均值;同时提取法官经历上诉后的 20 个案子,然后求罚款的均值。
个人设计的算法逻辑如下:
按照法院-法官的组合对数据进行分组。
每个数据都有初审到终审的时间,形成时间戳,并且每一行应该识别一系列时间中的最早时间和最晚时间。
当最早时间不等于最晚时间时,这条数据就是主干数据。
在每个组别内,只保留满足条件的样本。
在主干数据周围,当在主干数据最早数据之前还有 10 个案子,在主干数据之后也还有 10 个案子,最终只保留这 21 条数据。
如果一个组别同时有多个案子,则都保留满足要求的样本。
给满足周围存在对应数量案子的主干数据生成变量 a,标识为 1。
生成上诉前变量和上诉后变量,求数量对应案子的均值。
为了更好地利用 ai,实际上这个算法我是拆成了两步。第一部分是筛选满足要求的所有样本;第二部是在满足要求的主干数据(a=1)处计算前后案件的均值。最周再整合两部分的代码。
我最终多设置了一个参数,关于主干案件周围需要有多少案子才保留。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
import pandas as pd
from tqdm import tqdm
import numpy as np
# 参数配置
input_path = r 'C:\Users\PC\Desktop\hzp_project_re\re_论文开始\最终面板数据\去极端值交通民事上诉样本.csv'
output_path = r 'C:\Users\PC\Desktop\hzp_project_re\re_论文开始\最终面板数据\去极端值交通民事上诉样本_论文去0_45_民诉样本.csv'
before_n = 45 # 保留之前记录的条数
after_n = 45 # 保留之后记录的条数
# 时间字段配置
time_columns = [
'jud_year' , 'jud_month' ,
'm1_jud_year' , 'm1_jud_month' ,
'm2_jud_year' , 'm2_jud_month' ,
'm3_jud_year' , 'm3_jud_month' ,
'm4_jud_year' , 'm4_jud_month' ,
]
def extract_timestamps ( row ):
"""提取每行的时间戳(最早和最晚时间)"""
timestamps = []
for i in range ( 0 , len ( time_columns ), 2 ):
year = row [ time_columns [ i ]]
month = row [ time_columns [ i + 1 ]]
if pd . notna ( year ) and pd . notna ( month ):
try :
timestamps . append (( int ( year ), int ( month )))
except :
continue
return min ( timestamps , default = None ), max ( timestamps , default = None )
def is_main_case ( row ):
"""判断是否为主干数据"""
conditions = [
( pd . notna ( row [ 'm1_judge_am' ]) & pd . notna ( row [ 'm2_judge_am' ])),
( pd . notna ( row [ 'm1_judge_am' ]) & pd . notna ( row [ 'm3_judge_am' ])),
( pd . notna ( row [ 'm1_judge_am' ]) & pd . notna ( row [ 'm4_judge_am' ])),
( pd . notna ( row [ 'm2_judge_am' ]) & pd . notna ( row [ 'm3_judge_am' ])),
( pd . notna ( row [ 'm2_judge_am' ]) & pd . notna ( row [ 'm4_judge_am' ])),
( pd . notna ( row [ 'm3_judge_am' ]) & pd . notna ( row [ 'm4_judge_am' ])),
]
return any ( conditions )
def filter_valid_judge ( data ):
"""过滤有效金额(非0非空)"""
return data [( data [ 'judge_am' ] != 0 ) & ( data [ 'judge_am' ] . notna ())]
def calculate_means ( group , main_case_idx ):
"""
计算主干数据的 judge_sum, bf_judge_sum 和 af_judge_sum(均排除0值和空值)
"""
min_time , max_time = extract_timestamps ( group . loc [ main_case_idx ])
if min_time is None or max_time is None :
return group
# 计算judge_sum
judge_data = group [ group . index != main_case_idx ]
valid_judge = filter_valid_judge ( judge_data )
group . loc [ main_case_idx , 'judge_sum' ] = valid_judge [ 'judge_am' ] . mean () if not valid_judge . empty else np . nan
# 计算bf_judge_sum
bf_cond = (
( group [ 'jud_year' ] < min_time [ 0 ]) |
(( group [ 'jud_year' ] == min_time [ 0 ]) & ( group [ 'jud_month' ] < min_time [ 1 ]))
) & ( group . index != main_case_idx )
valid_bf = filter_valid_judge ( group [ bf_cond ])
group . loc [ main_case_idx , 'bf_judge_sum' ] = valid_bf [ 'judge_am' ] . mean () if not valid_bf . empty else np . nan
# 计算af_judge_sum
af_cond = (
( group [ 'jud_year' ] > max_time [ 0 ]) |
(( group [ 'jud_year' ] == max_time [ 0 ]) & ( group [ 'jud_month' ] > max_time [ 1 ]))
) & ( group . index != main_case_idx )
valid_af = filter_valid_judge ( group [ af_cond ])
group . loc [ main_case_idx , 'af_judge_sum' ] = valid_af [ 'judge_am' ] . mean () if not valid_af . empty else np . nan
return group
def process_group ( group ):
"""处理单个分组并生成特征"""
# 创建新列的 DataFrame
new_columns = {}
for i in range ( 1 , before_n + 1 ):
new_columns [ f 'bf_ { i } _judge_am' ] = np . nan
new_columns [ f 'bf_ { i } _count_tiao' ] = np . nan
new_columns [ f 'bf_ { i } _total_chars' ] = np . nan
new_columns [ f 'bf_ { i } _clause_count' ] = np . nan
for j in range ( 1 , after_n + 1 ):
new_columns [ f 'af_ { j } _judge_am' ] = np . nan
new_columns [ f 'af_ { j } _count_tiao' ] = np . nan
new_columns [ f 'af_ { j } _total_chars' ] = np . nan
new_columns [ f 'af_ { j } _clause_count' ] = np . nan
new_columns . update ({
'a' : 0 ,
'judge_sum' : np . nan ,
'bf_judge_sum' : np . nan ,
'af_judge_sum' : np . nan
})
# 将新列一次性添加到 group 中
new_columns_df = pd . DataFrame ( new_columns , index = group . index )
group = pd . concat ([ group , new_columns_df ], axis = 1 )
# 筛选主干数据
main_cases = group [ group . apply ( is_main_case , axis = 1 )]
if main_cases . empty :
return group
for idx , row in main_cases . iterrows ():
min_time , max_time = extract_timestamps ( row )
if not min_time or not max_time :
continue
group . loc [ idx , 'a' ] = 1
group = calculate_means ( group , idx )
# 获取有效上下文数据
before_data = filter_valid_judge ( group [
( group [ 'jud_year' ] < min_time [ 0 ]) |
(( group [ 'jud_year' ] == min_time [ 0 ]) & ( group [ 'jud_month' ] < min_time [ 1 ]))
]) . sort_values ([ 'jud_year' , 'jud_month' ], ascending = [ True , True ])
after_data = filter_valid_judge ( group [
( group [ 'jud_year' ] > max_time [ 0 ]) |
(( group [ 'jud_year' ] == max_time [ 0 ]) & ( group [ 'jud_month' ] > max_time [ 1 ]))
]) . sort_values ([ 'jud_year' , 'jud_month' ], ascending = [ True , True ])
# 填充前向特征
for i in range ( 1 , min ( before_n + 1 , len ( before_data ) + 1 )):
row_data = before_data . iloc [ - i ]
group . loc [ idx , f 'bf_ { i } _judge_am' ] = row_data [ 'judge_am' ]
group . loc [ idx , f 'bf_ { i } _count_tiao' ] = row_data [ 'count_tiao' ]
group . loc [ idx , f 'bf_ { i } _total_chars' ] = row_data [ 'total_chars' ]
group . loc [ idx , f 'bf_ { i } _clause_count' ] = row_data [ 'clause_count' ]
# 填充后向特征
for j in range ( 1 , min ( after_n + 1 , len ( after_data ) + 1 )):
row_data = after_data . iloc [ j - 1 ]
group . loc [ idx , f 'af_ { j } _judge_am' ] = row_data [ 'judge_am' ]
group . loc [ idx , f 'af_ { j } _count_tiao' ] = row_data [ 'count_tiao' ]
group . loc [ idx , f 'af_ { j } _total_chars' ] = row_data [ 'total_chars' ]
group . loc [ idx , f 'af_ { j } _clause_count' ] = row_data [ 'clause_count' ]
return group
if __name__ == "__main__" :
try :
with open ( input_path , 'r' , encoding = 'utf-8' , errors = 'replace' ) as file :
df = pd . read_csv ( file )
print ( f "成功加载数据: { len ( df ) : , } 条" )
except Exception as e :
print ( f "数据加载失败: { str ( e ) } " )
exit ()
final_dfs = []
grouped = df . groupby ([ 'court_name' , 'judge_fin' ])
with tqdm ( total = len ( grouped ), desc = "处理进度" ) as pbar :
for ( court , judge ), group in grouped :
final_dfs . append ( process_group ( group ))
pbar . update ( 1 )
final_df = pd . concat ( final_dfs )
final_df . to_csv ( output_path , index = False , encoding = 'utf-8' )
# 结果验证
main_data = final_df [ final_df [ 'a' ] == 1 ]
print ( f " \n 生成主干数据: { len ( main_data ) : , } 条" )
print ( "字段验证(应无0值和空值):" )
print ( main_data [[ 'judge_sum' , 'bf_judge_sum' , 'af_judge_sum' ]] . describe ())
以上代码如果不是在 jupyter 环境中运行而是在 pycharm 环境中运行,需要调整下输入参数的位置。
一些可以快速得到的裁判文书变量
工作经验:第一次出现的时间和最后一次出现的时间段
共同案件:在样本中一共处理了多少案件
累计案件:这是目前处理的第几起案件。由于样本是以月为单位,累计计数应当是1、1、3、3、5、6……
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
* 生成唯一行号 id
gen id = _n
* 确保数据按法院、法官、年份、月份、案件顺序排序
sort court_name judge_fin jud_year jud_month id
* 创建案件计数变量(每一行默认计数为 1)
gen case_count = 1
* 按法院和法官分组,并对案件计数进行累计
bysort court_name judge_fin (jud_year jud_month): gen cumulative_count = sum(case_count)
* 修正为同月累计数相同
bysort court_name judge_fin jud_year jud_month (cumulative_count): replace cumulative_count = cumulative_count[_N]
* 转换年份和月份为单一时间点(以月份为单位)
gen time = jud_year * 12 + jud_month
* 计算首次时间点(每个法官在某法院处理第一个案件的时间)
bysort court_name judge_fin (jud_year jud_month): gen first_time = time[1]
* 计算工作经验(单位:月份)
gen work_experience_months = time - first_time + 1
* 删除不需要的临时变量
drop id case_count time first_time
egen combo_count = count(court_name + judge_fin), by(court_name judge_fin)
Python 例子 :案件积压量
在裁判文书中有两个时间,案件判决时间( jud 开头)和案件立案( acc 开头)时间。
案件积压量是指立案时间早于当前年月,判决年饭晚于当前年份的所有案件。这种涉及跨行变量识别处理的操作就是 stata 的弱点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
import pandas as pd
import numpy as np
from tqdm import tqdm
import time
def calculate_backlog ( df : pd . DataFrame ) -> pd . DataFrame :
# 构造时间字段(以月份为单位)
df [ 'acc_time' ] = df [ 'acc_year' ] * 12 + df [ 'acc_month' ]
df [ 'jud_time' ] = df [ 'jud_year' ] * 12 + df [ 'jud_month' ]
# 初始化 backlog 列
df [ 'backlog' ] = 0
# 按法院+法官分组处理
grouped = df . groupby ([ 'court_name' , 'judge_fin' ])
print ( f "共有分组数量: { len ( grouped ) } " )
start_time = time . time ()
# 遍历每组
for ( court , judge ), group_df in tqdm ( grouped , desc = "Processing court-judge groups" ):
idx = group_df . index
jud_times = group_df [ 'jud_time' ] . to_numpy ()
acc_times = group_df [ 'acc_time' ] . to_numpy ()
# 初始化 backlog 结果
backlog_counts = np . zeros ( len ( group_df ), dtype = int )
for i in range ( len ( group_df )):
jud_time_i = jud_times [ i ]
# 积压条件:立案时间 < 当前判决时间,且 其他案件的判决时间 > 当前判决时间
backlog_mask = ( acc_times < jud_time_i ) & ( jud_times > jud_time_i )
backlog_counts [ i ] = backlog_mask . sum ()
# 更新结果
df . loc [ idx , 'backlog' ] = backlog_counts
elapsed = time . time () - start_time
print ( f " \n 处理完成,总耗时: { elapsed : .2f } 秒" )
return df
def main ( input_path , output_path ):
print ( "读取数据中..." )
df = pd . read_csv ( input_path , encoding = 'utf-8' , encoding_errors = 'replace' )
print ( f "数据读取完成,共有 { len ( df ) } 条记录。" )
df_result = calculate_backlog ( df )
print ( f "保存结果到: { output_path } " )
df_result . to_csv ( output_path , index = False , encoding = 'utf-8-sig' )
print ( "保存完成。" )
if __name__ == "__main__" :
# 请根据你的环境修改输入输出路径
input_path = r 'C:\Users\PC\Desktop\hzp_project_re\re_论文开始\案件积压\案件积压计算.csv'
output_path = r 'C:\Users\PC\Desktop\hzp_project_re\re_论文开始\案件积压\论文_案件积压计算.csv'
main ( input_path , output_path )
Stata 例子 :法院-年份案件公开率
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
********** 思路 *************
/*
由于每年案件编号为
民初(2020)**号,**号按照顺序编号。
有可能样本只有1、3、5、7号,
通过极大似然法估计产生的“坦克公式”估计公开率(二战坦克缴获率)
最终计算每年每个法院对应的公开率
考虑去掉公开率低的法院(等同于去掉公开率低的地区)
*/
********** 变量说明 *************
/*
case_num_str:裁判文书案号
court_name:法院名称
jud_year:判决年份
public_rate:公开率
*/
********** 参考文献 *************
/*
1公式的提出,还有其他估计公开率的方法
Augmenting serialized bureaucratic data: the case of Chinese courts(2022,工作论文)
2应用例子
Suing the government under weak rule of law: Evidence from administrative litigation reform in China(2023,jpube)
*/
gen case_num_str = ustrregexs ( 1 ) if ustrregexm ( case_wid_str , "民[^0-9]*([0-9]+)" )
replace case_num_str = ustrregexra ( case_num_str , "^0+" , "" )
destring case_num_str , gen ( case_num )
drop case_num_str
order case_wid_str case_num
bysort court_name jud_year : egen max_case_num = max ( case_num )
bysort court_name jud_year : gen case_count = _N
order max_case_N
bysort court_name jud_year : egen max_case_N = max ( case_count )
gen case_count = max_case_num
gen public_rate = max_case_N / ( max_case_num * ( 1 + 1 / max_case_N ) - 1 )
sum public_rate
keep court_name jud_year public_rate
duplicates drop court_name jud_year , force
duplicates report court_name jud_year
Python 例子:大型数据的匹配
现在比较流行工商注册数据和其他企业数据库的匹配,几乎就是 5000 万条有效数据起步。
Stata 的 merge 命令在匹配时非常消耗内存,因为其临时副本的原因会轻松在内存损耗上翻倍。因此个人推荐都导出 .csv 文件使用 python 的 duckdb(pandas 匹配只是比 stata merge 略微好一点而已。)
下面这个例子就是 duckdb 的例子,代码作用和 stata 的 merge m:1 效果相同,但更优化内存:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
import duckdb
import os
con . execute ( "DROP TABLE IF EXISTS using_tbl" )
con . execute ( "DROP TABLE IF EXISTS main_tbl" )
con . execute ( "DROP TABLE IF EXISTS merged" )
# =====================
# 路径(按你自己实际路径改)
# =====================
MAIN_CSV = r "C:\Users\PC\Desktop\中国招投标\论文代码\回归数据.csv"
USING_CSV = r "C:\Users\PC\Desktop\中国招投标\论文代码\注册数据.csv"
OUT_CSV = r "C:\Users\PC\Desktop\中国招投标\论文代码\merged.csv"
DB_FILE = r "C:\Users\PC\Desktop\中国招投标\论文代码\merge.duckdb"
# =====================
# 连接 DuckDB(落盘,防 OOM)
# =====================
con = duckdb . connect ( DB_FILE )
# (可选)限制内存,更稳
con . execute ( "PRAGMA memory_limit='16GB'" )
con . execute ( "PRAGMA threads=8" )
print ( "1️⃣ 读取 using 表(1.8 亿)" )
con . execute ( f """
CREATE TABLE using_tbl AS
SELECT *
FROM read_csv_auto(
' { USING_CSV } ',
SAMPLE_SIZE=1000000,
parallel=true
)
""" )
print ( "2️⃣ 读取 main 表(2000 万)" )
con . execute ( f """
CREATE TABLE main_tbl AS
SELECT *
FROM read_csv_auto(
' { MAIN_CSV } ',
SAMPLE_SIZE=500000,
parallel=true
)
""" )
print ( "3️⃣ LEFT JOIN(m:1)" )
con . execute ( """
CREATE TABLE merged AS
SELECT
m.*,
u.*
FROM main_tbl m
LEFT JOIN using_tbl u
ON m.credit_code = u.credit_code
""" )
print ( "4️⃣ 导出结果" )
con . execute ( f """
COPY merged
TO ' { OUT_CSV } '
(HEADER, DELIMITER ',')
""" )
con . close ()
print ( "✅ 完成" )
python 例子 :案件类型的分类
参考了论文《Women in the Courtroom: Technology and Justice 》。裁判文书案件类型太多怎么办?通过LDA模型聚类到50个案件类型。
此处代码是假设你已经有了一个案件面板(.csv) 案件号-案件类型名称。接下来可以通过机器学习分类简化为 50 个案件类型。
应用例子可以参考 LDA 主题模型与 Gephi 可视化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
import ast
import pandas as pd
import jieba
import logging
from gensim import corpora , models
from tqdm.auto import tqdm
import warnings
import os
import re
# -------------------------------
# 0. 全局设置
# -------------------------------
# 忽略警告
warnings . filterwarnings ( "ignore" )
jieba . setLogLevel ( logging . INFO )
# 初始化 jieba,避免在进度条中打印日志
jieba . initialize ()
# -------------------------------
# 用户可配置参数 (User Configurable Parameters)
# -------------------------------
# 设置要生成的主题数量。请在此处修改主题数,例如 20, 50, 100 等。
NUM_TOPICS = 50
# 设置用于过滤低频词的最小出现次数。例如,no_below=100 表示只保留出现次数 >= 100 的词汇。
MIN_WORD_COUNT = 100
# LDA 训练的迭代次数 (Passes)
NUM_PASSES = 10
# -------------------------------
# 文件路径设置 (文件名为动态生成,包含主题数量)
# -------------------------------
input_path = r "/root/案件类型.csv"
output_path = r "/root/案件类型_ {} 类别结果.csv" . format ( NUM_TOPICS )
topic_words_path = r "/root/主题 {} 词汇.csv" . format ( NUM_TOPICS )
doc_topic_words_path = r "/root/文档主题词_ {} 主题.csv" . format ( NUM_TOPICS )
# 定义常用且低区分度的停用词
# 目标是强制模型关注案件的主体名词(如:买卖、金融、商标、继承)
CHINESE_STOPWORDS = {
'纠纷' , '责任' , '案件' , '争议' , '纠纷案件' , '追偿' , '纠葛' , '诉讼' , '法律' , '与' , '及' , '的' , '是' ,
'一' , '二' , '三' , '四' , '等' , '其他' , '之' , '因' , '中' ,
# 新增加的通用法律词汇,这些词汇在各类案件中都可能出现,降低了主题区分度
'权' , '损害' , '赔偿' , '物' , '行为' , '权利' , '民事' , '确认'
}
print ( f "正在读取数据: { input_path } ..." )
# -------------------------------
# 1. 读取数据
# -------------------------------
data = pd . read_csv ( input_path , dtype = str )
data = data . fillna ( "" )
# -------------------------------
# 2. 清洗 type 字段
# -------------------------------
def clean_type ( x ):
x = str ( x ) . strip ()
try :
val = ast . literal_eval ( x )
if isinstance ( val , list ):
return " " . join ( val )
except :
pass
# 移除所有非中文字符,确保只保留中文案由名称
x = re . sub ( r '[^\u4e00-\u9fa5\s]' , '' , x )
return x . replace ( "[" , "" ) . replace ( "]" , "" ) . replace ( "'" , "" )
tqdm . pandas ( desc = "清洗数据" , mininterval = 0.5 )
data [ "type_clean" ] = data [ "type" ] . progress_apply ( clean_type )
# -------------------------------
# 3. 中文分词和停用词过滤
# -------------------------------
print ( "正在进行分词和停用词过滤..." )
def cut_words_and_filter ( text ):
# 分词
words = jieba . lcut ( text )
# 过滤空词和停用词
filtered_words = [ w for w in words if w . strip () and w not in CHINESE_STOPWORDS ]
return filtered_words
tqdm . pandas ( desc = "分词处理" , mininterval = 0.5 )
data [ "words" ] = data [ "type_clean" ] . progress_apply ( cut_words_and_filter )
# 过滤空文本
original_len = len ( data )
data = data [ data [ "words" ] . map ( len ) > 0 ] . reset_index ( drop = True )
print ( f "有效文本数量: { len ( data ) } / { original_len } " )
texts = data [ "words" ] . tolist ()
# -------------------------------
# 4. 构建字典和语料
# -------------------------------
print ( "构建字典和语料..." )
dictionary = corpora . Dictionary ( texts )
# 过滤掉出现次数少于 MIN_WORD_COUNT 次的词汇
dictionary . filter_extremes ( no_below = MIN_WORD_COUNT )
corpus = [ dictionary . doc2bow ( t ) for t in tqdm ( texts , desc = "生成语料" , mininterval = 0.5 )]
# -------------------------------
# 5. LDA训练 (使用 LdaMulticore 加速)
# -------------------------------
num_topics = NUM_TOPICS # 使用用户设置的主题参数
passes = NUM_PASSES # 使用用户设置的迭代次数参数
# 自动设置核心数,使用所有核心 - 1
workers = max ( 1 , os . cpu_count () - 1 )
print ( f "开始 LDA Multicore 训练 (主题数= { num_topics } , 轮数= { passes } , 核心数= { workers } )..." )
# 切换到 LdaMulticore,使用多核并行计算
lda = models . LdaMulticore (
corpus = corpus ,
id2word = dictionary ,
num_topics = num_topics ,
passes = passes ,
random_state = 42 ,
workers = workers , # 使用多核心并行计算
chunksize = 5000 # 增大块大小以优化性能
)
# -------------------------------
# 6. 输出主题高频词
# -------------------------------
topn = 10
topic_words = {}
for t in range ( num_topics ):
topic_words [ t ] = [ word for word , _ in lda . show_topic ( t , topn = topn )]
df_topic_words = pd . DataFrame ({
"topic" : list ( topic_words . keys ()),
"words" : [ " " . join ( wlist ) for wlist in topic_words . values ()]
})
df_topic_words . to_csv ( topic_words_path , index = False , encoding = "utf-8-sig" )
print ( f "已输出主题高频词到: { topic_words_path } " )
# -------------------------------
# 7. 文本 → 主题映射(保证相同文本同主题,并输出主题词)
# -------------------------------
text2topic = {}
topic_list = []
doc_topic_words_list = [] # 存放每条文档对应主题的前 N 个词
print ( " \n 正在进行文档主题预测..." )
# total=len(corpus) 确保 tqdm 正确计算进度
for t_clean , doc in tqdm ( zip ( data [ "type_clean" ], corpus ), total = len ( corpus ), desc = "主题预测" , mininterval = 0.5 ):
if t_clean in text2topic :
best_topic = text2topic [ t_clean ]
else :
tp = lda . get_document_topics ( doc )
if tp :
# 取概率最大的主题ID
best_topic = max ( tp , key = lambda x : x [ 1 ])[ 0 ]
else :
best_topic = - 1
# 缓存结果
text2topic [ t_clean ] = best_topic
topic_list . append ( best_topic )
if best_topic != - 1 :
doc_topic_words_list . append ( " " . join ( topic_words [ best_topic ]))
else :
doc_topic_words_list . append ( "" )
# 使用动态列名,例如 topic50
data [ f "topic { NUM_TOPICS } " ] = topic_list
data [ "topic_words" ] = doc_topic_words_list
# -------------------------------
# 8. 保存结果
# -------------------------------
output_columns = [ c for c in data . columns if c not in [ "words" ]]
data [ output_columns ] . to_csv ( output_path , index = False , encoding = "utf-8-sig" )
print ( f "完成!已输出最终结果到: { output_path } " )
# -------------------------------
# 9. 保存文档对应主题词 CSV
# -------------------------------
# 调整列名以保持清晰
data_doc_topic = data [[ "type_clean" , f "topic { NUM_TOPICS } " , "topic_words" ]]
data_doc_topic . columns = [ "type_clean" , "topic_id" , "topic_words" ]
data_doc_topic . to_csv ( doc_topic_words_path , index = False , encoding = "utf-8-sig" )
print ( f "文档主题词已输出到: { doc_topic_words_path } " )
Python 例子 :基于姓名预测性别
由于法官没有公布性别,可以通过姓名预测性别。Python 包调用即可。参考论文《Women in the Courtroom: Technology and Justice 》,下面使用的是 ngender 包。
这个包也存在缺陷,使用的是贝叶斯估计训练的参数,因此假设名字字符是独立的。例如王胜男,每个字单独看起来偏男性,但是个典型女性名字,但是基于贝叶斯估计,这个包会将其识别为男性。
如果想要进一步做严谨,个人推荐了解一个 github 仓库预测中文姓名的性别
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import pandas as pd
import ngender
# Load the CSV file
df = pd . read_csv ( 'F:\桌面\性别预测测试\测试.csv' ) # Replace with your actual CSV file name
# Function to predict gender
def predict_gender ( name ):
try :
result = ngender . guess ( str ( name )) # Returns (gender, probability)
return result [ 0 ] # Extract gender ('male', 'female', or 'neutral')
except :
return 'unknown' # Handle invalid names
# Add predicted gender column
df [ '预测性别' ] = df [ 'name' ] . apply ( predict_gender )
# Save the updated CSV
df . to_csv ( 'output.csv' , index = False , encoding = 'utf-8-sig' )
print ( "Gender predictions added to 'output.csv'" )
描述统计
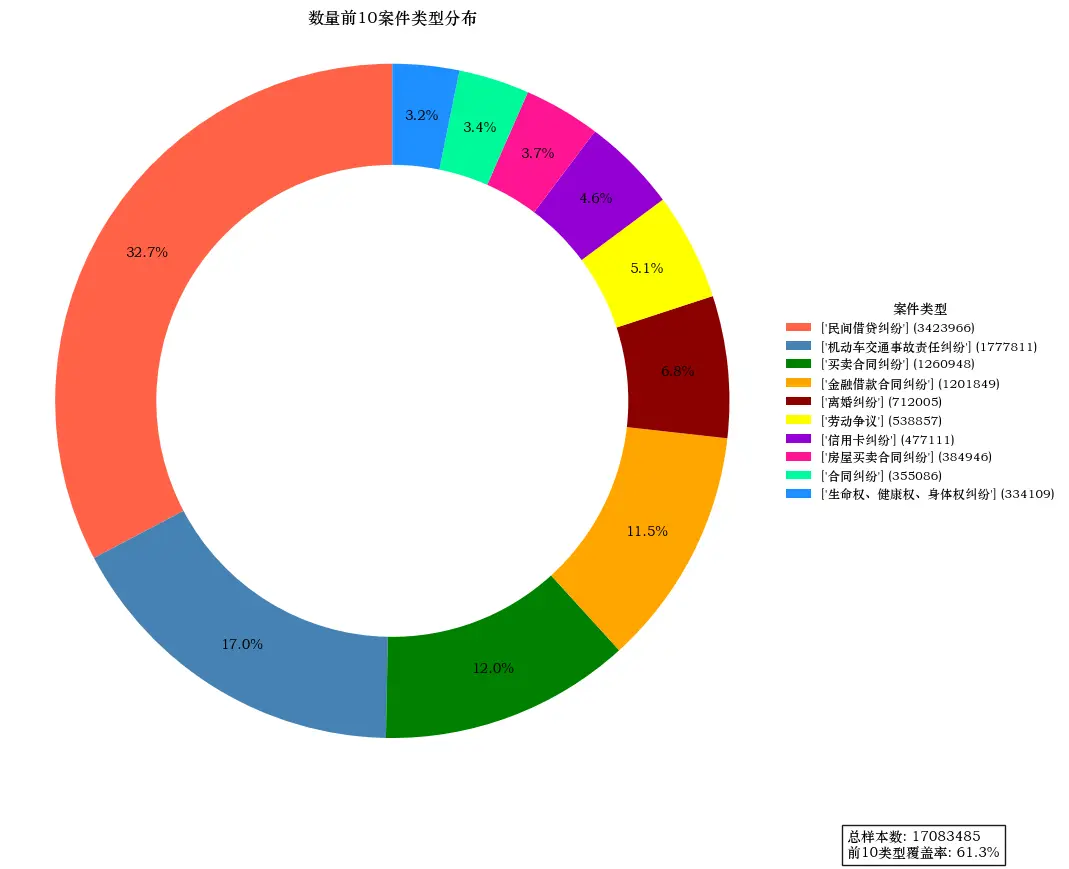
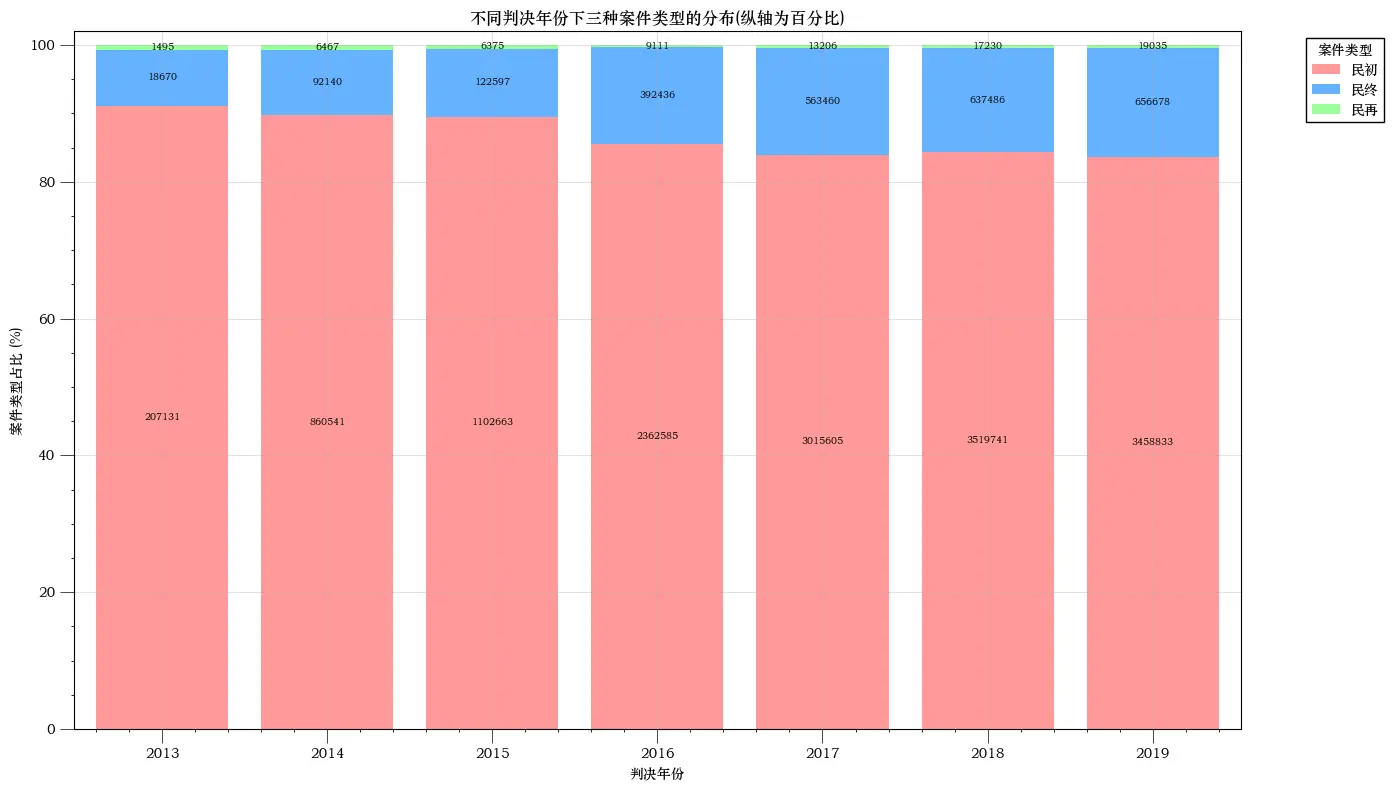
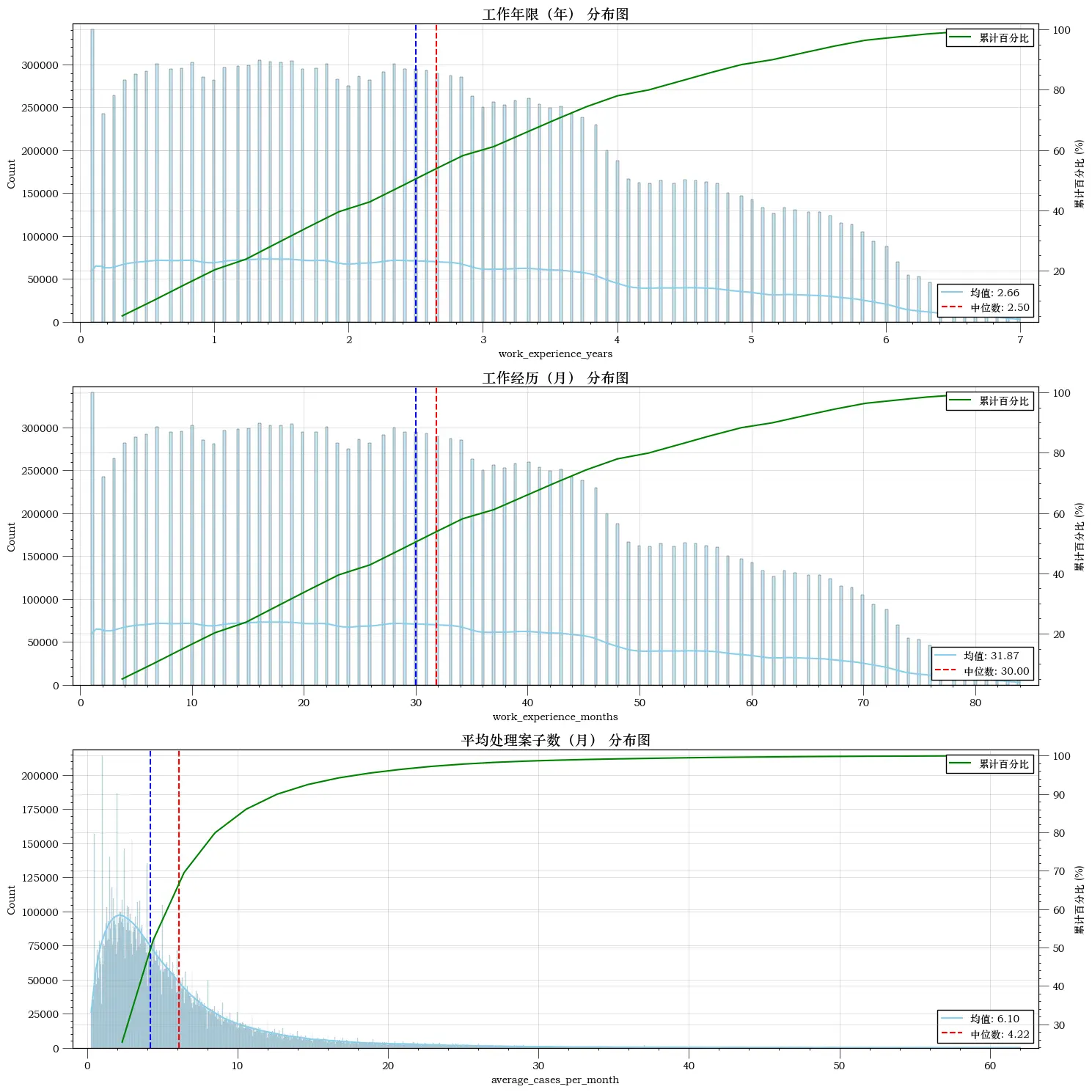
环状图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
import pandas as pd
import matplotlib.pyplot as plt
from aquarel import load_theme
# 加载并应用主题
theme = load_theme ( "boxy_light" )
theme . apply ()
# 设置中文字体
plt . rcParams [ 'font.sans-serif' ] = [ 'STZhongsong' ]
plt . rcParams [ 'axes.unicode_minus' ] = False
# 数据处理
types = df [ 'type' ] . explode () . value_counts ()
top_types = types . head ( 10 )
# 颜色配置
colors = [ '#FF6347' , '#4682B4' , '#008000' , '#FFA500' , '#8B0000' ,
'#FFFF00' , '#9400D3' , '#FF1493' , '#00FA9A' , '#1E90FF' ]
# 创建画布
fig , ax = plt . subplots ( figsize = ( 10 , 8 ))
# 绘制环状图
wedges , texts , autotexts = ax . pie (
top_types . values ,
autopct = ' %1.1f%% ' ,
startangle = 90 ,
pctdistance = 0.85 ,
wedgeprops = dict ( width = 0.3 ),
colors = colors
)
# 创建自定义图例
legend_labels = [ f " { label } ( { value } )" for label , value in zip ( top_types . index , top_types . values )]
legend = ax . legend (
wedges ,
legend_labels ,
title = "案件类型" ,
loc = "center left" ,
bbox_to_anchor = ( 1 , 0 , 0.5 , 1 ),
fontsize = 9 ,
title_fontsize = 10 ,
frameon = False
)
# 添加统计信息
total = len ( df [ 'type' ])
plt . text ( 1.35 , - 1.35 ,
f "总样本数: { total } \n 前10类型覆盖率: { top_types . sum () / total : .1% } " ,
bbox = dict ( facecolor = 'white' , alpha = 0.9 ))
# 调整布局
plt . title ( '数量前10案件类型分布' , pad = 20 )
plt . tight_layout ()
plt . axis ( 'equal' )
plt . show ()
如图
条状图
优化了数字排列方式不重叠
规定了民初、再、终案号的排列顺序
使用了 python 包 pip install aquarel 优化了绘图风格。
Aquarel
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
# 设置中文字体和解决负号显示问题
mpl . rcParams [ 'font.sans-serif' ] = [ 'STZhongsong' ] # 指定默认字体:解决plot不能显示中文问题
mpl . rcParams [ 'axes.unicode_minus' ] = False # 解决保存图像是负号'-'显示为方块的问题
# 加载数据
df = pd . read_csv ( r 'C:\Users\PC\Desktop\hzp_project_re\re_论文开始\最终面板数据\民事上诉样本.csv' , encoding = 'utf-8' , low_memory = False )
# 从case_wid_str中提取案件类型
df [ 'case_type' ] = df [ 'case_wid_str' ] . str . extract ( r '(民初|民终|民再)' )
# 统计每种案件类型在不同法院级别的分布情况
distribution = df . groupby ([ 'court' , 'case_type' ]) . size () . unstack ( fill_value = 0 )
# 只保留特定的法院级别,但只包括实际存在的法院级别
desired_courts = [ 1 , 3 , 4 , 5 , 6 ]
existing_courts = [ court for court in desired_courts if court in distribution . index ]
distribution = distribution . loc [ existing_courts ]
# 计算每个法院级别的总案件数
total_cases_per_court = distribution . sum ( axis = 1 )
# 计算比例
distribution_ratio = distribution . div ( total_cases_per_court , axis = 0 ) * 100
# 设置图表大小
plt . figure ( figsize = ( 12 , 8 ))
# 定义一个空列表用于底部高度
bottoms = [ 0 ] * len ( distribution_ratio )
# 按照民初、民再、民终的顺序进行堆叠
case_types_order = [ '民初' , '民再' , '民终' ]
for case_type in case_types_order : # 使用正序确保民初在最下面
if case_type in distribution . columns :
plt . bar ( range ( len ( distribution_ratio . index )), distribution_ratio [ case_type ], bottom = bottoms , label = case_type )
# 在每个条形图上方显示具体数量
for index , value in enumerate ( distribution [ case_type ]):
text_y_position = bottoms [ index ] + ( distribution_ratio . loc [ existing_courts [ index ], case_type ] / 2 )
# 调整文本位置以避免重叠
if case_type == '民再' :
if index % 2 == 0 :
text_y_position += 2 # 向上移动
else :
text_y_position -= 2 # 向下移动
plt . text ( index , text_y_position ,
str ( int ( value )), ha = 'center' , va = 'center' , color = 'black' , fontsize = 9 )
# 更新底部高度
bottoms = [ sum ( x ) for x in zip ( bottoms , distribution_ratio [ case_type ])]
# 修改x轴标签
court_labels = { i : label for i , label in enumerate ([ "最高" , "高级" , "中级" , "基层" , "专门" ][: len ( existing_courts )])}
plt . xticks ( range ( len ( existing_courts )), list ( court_labels . values ()))
# 添加标题和标签
plt . title ( '案件类型在不同法院级别的比例分布' , fontsize = 14 , pad = 20 )
plt . xlabel ( '法院级别' , fontsize = 12 , labelpad = 15 )
plt . ylabel ( '比例 (%)' , fontsize = 12 , labelpad = 15 )
plt . legend ( title = "案件类型" , bbox_to_anchor = ( 1.05 , 1 ), loc = 'upper left' )
# 显示图表
plt . tight_layout ()
plt . show ()
如图
均值中位数分布图
包含均值、中位数、累计比例
使用了参数名称映射
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pylab import mpl
# 设置中文字体和解决负号显示问题
mpl . rcParams [ 'font.sans-serif' ] = [ 'STZhongsong' ] # 指定默认字体:解决plot不能显示中文问题
mpl . rcParams [ 'axes.unicode_minus' ] = False # 解决保存图像是负号'-'显示为方块的问题
# 假设这是你的数据列与其中文名称的映射
var_names_zh = {
'work_experience_years' : '工作年限(年)' ,
'work_experience_months' : '工作经历(月)' ,
'average_cases_per_month' : '平均处理案子数(月)'
}
# 加载数据
df = pd . read_csv ( r 'C:\Users\PC\Desktop\hzp_project_re\re_论文开始\最终面板数据\民事上诉样本.csv' , encoding = 'utf-8' , low_memory = False )
# 转换工作经历为年份
df [ 'work_experience_years' ] = df [ 'work_experience_months' ] / 12
# 计算平均一个月处理多少案子
df [ 'average_cases_per_month' ] = df [ 'cumulative_count' ] / ( df [ 'work_experience_months' ] + 1 )
def add_statistics ( ax , data ):
"""在给定的轴上添加平均数和中位数的标注"""
mean_val = data . mean ()
median_val = data . median ()
ax . axvline ( mean_val , color = 'red' , linestyle = '--' )
ax . axvline ( median_val , color = 'blue' , linestyle = '--' )
# 添加图例于右下角
ax . legend ([ f '均值: { mean_val : .2f } ' , f '中位数: { median_val : .2f } ' ], loc = 'lower right' )
def add_percentage_axis ( ax , data ):
"""在给定的轴上添加右侧的百分比轴"""
values , base = np . histogram ( data . dropna (), bins = 30 )
cumulative = np . cumsum ( values )
percentage = cumulative / cumulative [ - 1 ] * 100 # 将累计值转换为百分比
ax_percent = ax . twinx ()
ax_percent . plot ( base [ 1 :], percentage , c = 'green' , label = '累计百分比' )
ax_percent . set_ylabel ( '累计百分比 (%)' )
ax_percent . legend ( loc = 'upper right' )
def trim_data ( data , lower = 0.5 , upper = 99.5 ):
"""返回给定百分比范围内的数据"""
lower_quantile = np . percentile ( data , lower )
upper_quantile = np . percentile ( data , upper )
return data [( data >= lower_quantile ) & ( data <= upper_quantile )]
variables = [ 'work_experience_years' , 'work_experience_months' , 'average_cases_per_month' ]
fig , axes = plt . subplots ( len ( variables ), 1 , figsize = ( 15 , len ( variables ) * 5 ))
for idx , var in enumerate ( variables ):
# 使用中文名称
var_zh = var_names_zh . get ( var , var )
if var == 'average_cases_per_month' :
data_to_plot = trim_data ( df [ var ])
else :
data_to_plot = df [ var ]
# 原始数据分布
sns . histplot ( data_to_plot , kde = True , color = "skyblue" , edgecolor = "black" , ax = axes [ idx ])
axes [ idx ] . set_title ( f ' { var_zh } 分布图' , fontsize = 14 )
add_statistics ( axes [ idx ], data_to_plot ) # 添加平均数和中位数的标注
# 添加累计百分比轴
add_percentage_axis ( axes [ idx ], data_to_plot )
plt . tight_layout ()
plt . show ()
如图