
裁判文书清洗指南

+++ Title = ’ 标题名' Slug = ‘链接名’ date = 2024-10-29T18:52:19+08:00 Draft = true Math= false OutdatedInfoWarning = false Lightgallery = true FeaturedImage=“/img/pythonGIS.zh-cn-20250524111143536.webp” Tags = [“标签”,“ass” ] Categories= [“Movies”,“test”] Summary=’ 总结' +++
裁判文书清洗手册
作者:滑翔闪
- 这个文档既是目前工作的汇报,也是一些经验的总结。
- 或许能方便后面的同学更快上手裁判文书的清洗工作。
- 希望未来的同学能重视工程技巧的优化总结与文档分享。
思考如何优化工程,优化团队协作,让积累和输出成为一种能力。
世界不但需要输入,也需要输出,知识的分享与传递才是人类文明不断进步的纽带。
关于 ai 编程
选择什么 ai
关于 AI 工具的推荐:能用 GPT、claude 就用这些第一梯队的。
但是正如 vibecoding 给世界带来的冲击——vibe slop。我们使用 ai 编程,更要关心代码的可检验性,复用性,安全性,兼容性,易读性。
代码风格
复用性、易读性之间存在取舍。例如我个人不太喜欢顶刊代码那种疯狂使用 program,global 的风格。统计学代码不是产品代码,在科研中,除非数值计算,否则我们一般不太需要考虑复杂的宏来优化运行效率,大部分时候我们也只关系数据清洗如何减少内存占用和复用性。综上,我认为,在团队合作中,统计代码的易读性更重要。
我个人更偏好使用 local 实现代码功能,因此我往往会限制 ai 使用 glocal 和 program。
人的主观能动性
AI 虽然掌握了很多函数,但它不知道怎么组合。谋篇布局的算法理解才是我们的最大优势。提问时要替 AI 理顺代码的算法。
有了 AI 后——知道什么包能实现什么功能,在算法下有什么作用,比掌握细节更重要。
还有一个良好的习惯是及时总结为 md 文档。当我们用 ai 做了很多工作后,保留这些细节文档,能提升 ai 编程效率。
关于裁判文书的网站
不建议去裁判文书网查询案例,反应卡顿,验证频繁
裁判文书资源
原始文本数据:一堆 txt 文件。每一行是一条裁判文书信息,Txt 文件以 “万”作为文件名,因此下面使用整数部分的数字代表每个 txt 文件。
配套的文档是压缩包、文书字典、变量含义表格。

提示😍:每个 txt 文件都很大,一般软件打不开。个人推荐使用 EmEditor 软件查看。积极使用 EmEditor 软件查看例子,能让我们更好地了解乱码情况和裁判文书的书写规则,以便改进我们的文本处理代码。
- Dta 数据:前辈们清洗好的 stata 文件。拆分为了 ans 1—ans 83。格式刷 stata 的
.dta格式
一套完整的清洗流程就是:
从原始的 txt 中筛选提取我们需要的信息,最终成为能导入 stata 使用的数据。
txt 文件的处理
Txt 的裁判文书大部分已经处理为了 json格式,python 读取其实较为方便。
其中,大部分裁判文书 txt 文件是下方的 s 系列命名结构:
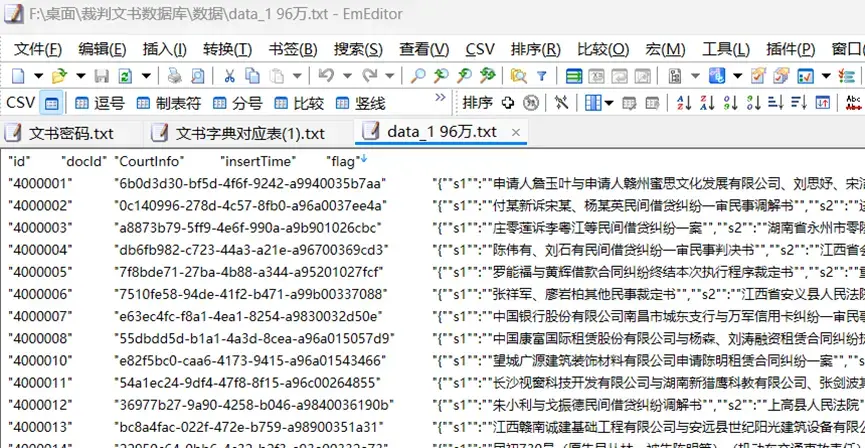
重要的信息都在第三列,s*系列包含的数据结构当中
但跑通了一到三份 txt 文件不等于能跑通所有。
- 有些 txt 文件格式为 DocInfoVo 开头的。
- 有些 txt 文件格式为 title 开头的。
- 有些 txt 文件格式夹杂着 HTML 语言。
- 有些 txt 文件格式是纯粹的乱码。
- 有些格式中 s 系列和 DocInfoVo 格式混在一起,导致循环代码被打断。
</b></div>
因此处理时得考虑代码的兼容性和全面性**,分开写处理代码,然后对这种 txt 文件处理两次。**
一些建议
由于循环容易被打断,用 txt 进行处理处理时,建议参考如下逻辑:
1、将乱码的 txt(附在后文)和 s 系列的 txt 分开处理
2、原始文件为 txt,清洗处理后生成新的 cleaned_txt。
3、由于清洗循环命令容易被打断,最好多写一个命令:对比 txt 和 cleaned_txt 的文件名。
4、多写一个步骤:将处理完成的 txt 文档移动到另一个文件夹,修改报错代码后继续循环。
Python 默认读取文件的顺序是 txt 1 txt 10 text 111… 而不是 1、2、3…
乱码文档
不只是 s 系列格式的 txt 文件有:
Python 例子 :提取案件号序列
思路
python 读取 txt 的 json 格式。
提取第三列 CourtInfo 数据。
s 23 变量所有案件号,以此追踪一审二审再审终审**。**
例如 (2016)沪0104民初33043号 ,其实就是一个裁判文书案件的身份证号。
正则表达式筛选:按照 (年份)初\终\再 号 的规则提取满足要求的字符串
提取后去除重、排除包含“['X', 'x', 'X', '执', '不动产', '-', '第']”的案件号。
如果继续使用这种方法提取,排除时最好加入 辖。
这种案号也有辖初、辖再、辖终,但只表示法院在管理权上的划分。
(或许以后还有人能想到用这个特征做研究?👍)
排序,优先按照案号中的 (年份) 进行排序。 删除案号数量大于等于 5 的所有行。
一个案子最多是如下的顺序:
初审,不服申请上诉,再审,终审,不服再进行上诉,终审。
可以直接从初审跳到终审,终审后还有最后一次再审机会,再审结束后一般就不会更改了。
个人的排序逻辑:(此处最大的漏洞是我想不到怎么完美识别“再”案号的位置)
生成 m 1——m 4 四个变量 带有初的案号归类到 m 1,带有终的案号归类到 m 3。
带有再的情况:
如果只有初和再,再归类到 m 2
如果只再,我默认放在 m 4
如果同时有终、再,根据相对位置判断再是 m 2 还是 m 4。
后面发现:【辖终】会干扰顺序,所以先将包含辖的案号清除,然后和被其挤到 m 4 的【终】案号交换顺序。
这就是大数据最麻烦的点:
如果前面工作没有完美做好,后面返工成本会越来越高。 最糟糕的是——大数据总是很难穷尽所有乱码可能。
单个 txt 的处理
以下代码只针对 s 系列命名的文档。
批量处理
个人选择的批量处理思路是循环处理一个文件夹下面的所有文档。
循环容易被打断,建议写一个报错记录,和处理完一个文档便移动的命令。
Python 例子 :提取法条和移动文件夹
法条数量可以衡量案件复杂度,法条本身也衡量了案件类型。
Txt 文档的 s 47 系列对应着文书的法条,里面是第二层 json 格式:
['s23', 's25', 's26', 's27'] 的中文字符加总就是裁判文书的正文字数。
“s7”: “案件号”,“s23”: “诉讼记录”,“s24”: “诉控辩”,“s25”: “事实”,“s26”: “理由”,“s27”: “判决结果”。
多个 txt
移动 txt
因为代码循环非常容易被打断,我建议设置三个文件夹**:**
原始文件夹存放原始数据,
结果文件夹存放处理完成的数据,统一改为 cleaned_* 的 txt 名字,
清洗完成的文件夹:把清洗完成的原始数据放到这里,便于循环打断后继续开始,
因此本代码的逻辑就是对照清洗完成的文件夹和原始文件夹**,将名字有对应的 txt 文档进行移动。**
例子 : 裁判文书索引重新排序
初审案号最早的排在前(m_sorted_1)
终审案号最晚的排在后(m_sorted_3)
再审案件按照“终审前最早、终审后最晚”安排(m_sorted_2, m_sorted_4)
其余案号按时间顺序补充空位(m_sorted_5)
dta 数据的匹配
关于案号
裁判文书的案号分为裁定文书、判决文书、其他文书(监督、执行、保证….)
裁定文书是审判程序上的问题,例如这个问题不该xx法院管,移交到xx法院去。
判决文书是实体问题,也就是判决的最终结果。
注意!判决文书和裁判文书是可能共享一个案号的!
同时在这里分享一些个人看到的奇葩裁判文书案号,有一些奇怪的符号可能是别人用过了然后再加符号作为区分。
由于中英文括号的问题,建议可以去除括号,但是不建议采用只保留中文和数字的筛选方式,很多时候短横线神秘字符也有标识作用。
个人匹配的筛选如下:
标识的去重
Txt 提取完成后,就是转化为 .dta 匹配到 ans*.dta 中。
****案号是理论上的唯一标识,但实际上可能出现重复的情况。
这时候建议使用以下逻辑,先历遍所有变量,生成非空数值总数,去重,在案号的重复行间保留非空数值最多的一行:
索引值的去重
文本匹配标识的格式转化
ans*.dta 系列的文本格式都是 strL,含义为长字符串。Stata 的字符串匹配只能选择有具体长度的字符串格式,我们可以通过字符截取来改变变量格式。
例如“民初 730 号”,虽然只是六个字符,但可能实际上占了 15 个位置。
如果我们只截取 6 个长度,变量就会变成乱码。
个人观察到的案号占位符最长大概是 39 个位置,个人为了稳健直接选择的截取 88 个字符符号。
这也意味着: 我们需要在清理掉文本中的奇怪符号以后再转化。
例如有些法院名字是“
广西壮族自治区柳州市鱼峰区人民法院”
匹配命令的选择
多(基础表格)对一时:merge 命令直接使用。
一(基础表格)対多时:例如 txt 有一些重复记录,但是不同行的空缺值不同。我们可以使用 merge 的追加匹配 update nogen force,只在这一行有空缺时,将空缺值的变量匹配上去;非空缺的部分则不更改。
多对多(基础表格)匹配时:此时使用 merge 不再合适,推荐 joinby
详细可参考 Stata命令:joinby VS merge m:m常见问题
循环匹配命令
当我们写循环匹配命令时,数字可能是间断点,例如 data 1、data 3、data 5、data 7…
可以选择使用 python 直接更改文件名字按顺序排序,但容易破坏命名含义。
这里提供个人写的 stata 自然数循环命令:
当然,其实可以通过扫描文件夹下面的文件名识别所有文件,然后循环,但是如果是存在一些文件需要手动排除可以参考下这个代码。
但是如果遇到的完全乱码名字的文件怎么办?在文件名没有空格或者特殊符号的情况下,可以读取文件名存入 local 再加入循环。这个也是更加泛用的代码。
例如以下乱码:
- 我们可以利用 stata 的 fs 包读取所有名字
- 然后使用 local 直接储存名字进行循环
- 循环过程中可以嵌套一层循环,使得新文件按照顺序命名
匹配速度的优化
正常匹配,应该是将 119 个 txt 转化的 dta 匹配,嵌套循环匹配到 ans 1-ans 83 上去。
如果直接嵌套循环匹配,可能需要 4 到 5 天。
匹配耗时过长的原因在于每一次嵌套循环的文件读取时间太长了,而且不同文件之间有重复值。
**建议先将 119 个 dta 文件使用 append 命令纵向匹配到一起,然后循环匹配到 ans 1 到 ans 83 上去,这样最多只需要 2 天即可完成全部匹配。
**
dta 数据的清洗
常用文本处理函数
去除空格
例如裁判长(法官)变量,会出现以下情况 四川 大学, 四川大学,四 川 大 学。
不同网站的空格符号并不相同,建议使用以下函数:
** * 移除所有特殊字符,包括不可见字符、空白和标点符号**
筛选特定字符
如果变量中含有特定字符则保留
如果有两个变量,例如一个是规范的省份变量 a(四川省,内蒙古自治区),另外一个是不规范的省变量 b(四川,内蒙古)。如果要判断 a 变量是否包含了 b 变量,则可以使用:
去除特殊字符
Ans 1 到 ans 83 的文本变量夹杂着各种非中文符号,可以使用以下函数去除:
以下是个人筛选出的乱码符号。
论文标签
有些时候,stata 数据只有变量名,同时另外有一个 excel 表格储存 label 值。
如何读取 excel 然后自动批量生成 labal vars name 呢?
这样就会生成一个文件,储存所有 stata 对应的标签化命令。
一切代码在自动化和透明度都有个取舍,个人比较偏好这种有中间产物的流程,便于检查和修正。
正则表达式提取
字符筛选
以裁判长文本变量为例子,
明明变量应该是一个名字,结果出现了一个段落
张三人民委托、张三于 2014 年进行审判、张三人民审判员进行裁决、张三代理裁判长进行庭审、张三李四熟记员进行开庭……

先使用字符长度筛选例子,查看文本格式:
然后根据情况只保留特定字符**。**
例如有以下组合
张三于** 2014 年进行庭审**
张三代理审判长于** 2014 年进行庭审**
在该变量包含“庭审”两个字时,我们应该先都保留“于”以前的字符,再保留“代理”以前的字符。
条件筛选最好找两个字的特征词,这样叫“于庭审”的法官名字几乎不可能出现。
个人使用的顺序,仅供参考:
由于爬虫有时候遇上网站加密,爬虫结果是 陈*,,完成以上清洗后只剩下 陈,删除单个字符行的函数命令是:
数字提取
例如数据显示 2.34435元(需要是字符串变量),我们只想单独提取数字,可以使用以下代码。
顺便一提,如果没有 real(regexs(1)) 这个参数则表示判断,只会返回 0 和 1,代表不符合或者符合格式。
dta 时间修正
在师门的招投标中,很多时间格式是混乱的。
例如标准的两种:
2019-12-31 09:00:00、
2019/12/30 09:30
但是也会出现 20220516 09:30:00、2022051609:30:00、2022051609:30
例如缺少秒、月份位置写成 4 而不是 04。
下面的代码集中处理了这套时间编码。
一些中文符号转英文的预处理。
在日期和时间之间没有空格时(例如 2022051609:30:00),如果范围在对应年月内(比如 0-31)则优先取两位数,超过范围了则取前面的个位数。
最后兼容各种格式的时间提取。
提醒
建议先将 stata 数据导出为 csv 格式。
最大的问题是乱码**。**
Python 例子 : 提取上诉法官过去和现在的特征均值
例子 3 是逐行匹配,但是这样处理实在是太慢了。
现在我想要这样处理:
提取法官经历上诉前的 20 个案子,然后求罚款均值;同时提取法官经历上诉后的 20 个案子,然后求罚款的均值。
个人设计的算法逻辑如下:
- 按照法院-法官的组合对数据进行分组。
- 每个数据都有初审到终审的时间,形成时间戳,并且每一行应该识别一系列时间中的最早时间和最晚时间。
- 当最早时间不等于最晚时间时,这条数据就是主干数据。
- 在每个组别内,只保留满足条件的样本。
- 在主干数据周围,当在主干数据最早数据之前还有 10 个案子,在主干数据之后也还有 10 个案子,最终只保留这 21 条数据。
- 如果一个组别同时有多个案子,则都保留满足要求的样本。
- 给满足周围存在对应数量案子的主干数据生成变量 a,标识为 1。
- 生成上诉前变量和上诉后变量,求数量对应案子的均值。
我最终多设置了一个参数,关于主干案件周围需要有多少案子才保留。
以上代码如果不是在 jupyter 环境中运行而是在 pycharm 环境中运行,需要调整下输入参数的位置。
一些可以快速得到的裁判文书变量
- 工作经验:第一次出现的时间和最后一次出现的时间段
- 共同案件:在样本中一共处理了多少案件
- 累计案件:这是目前处理的第几起案件。由于样本是以月为单位,累计计数应当是1、1、3、3、5、6……
Python 例子 :案件积压量
在裁判文书中有两个时间,案件判决时间( jud 开头)和案件立案( acc 开头)时间。
案件积压量是指立案时间早于当前年月,判决年饭晚于当前年份的所有案件。这种涉及跨行变量识别处理的操作就是 stata 的弱点。
Stata 例子 :法院-年份案件公开率
Python 例子:大型数据的匹配
现在比较流行工商注册数据和其他企业数据库的匹配,几乎就是 5000 万条有效数据起步。
Stata 的 merge 命令在匹配时非常消耗内存,因为其临时副本的原因会轻松在内存损耗上翻倍。因此个人推荐都导出 .csv 文件使用 python 的 duckdb(pandas 匹配只是比 stata merge 略微好一点而已。)
下面这个例子就是 duckdb 的例子,代码作用和 stata 的 merge m:1 效果相同,但更优化内存:
python 例子 :案件类型的分类
参考了论文《Women in the Courtroom: Technology and Justice》。裁判文书案件类型太多怎么办?通过LDA模型聚类到50个案件类型。
此处代码是假设你已经有了一个案件面板(.csv) 案件号-案件类型名称。接下来可以通过机器学习分类简化为 50 个案件类型。
应用例子可以参考 LDA 主题模型与 Gephi 可视化
Python 例子 :基于姓名预测性别
由于法官没有公布性别,可以通过姓名预测性别。Python 包调用即可。参考论文《Women in the Courtroom: Technology and Justice》,下面使用的是 ngender 包。
这个包也存在缺陷,使用的是贝叶斯估计训练的参数,因此假设名字字符是独立的。例如王胜男,每个字单独看起来偏男性,但是个典型女性名字,但是基于贝叶斯估计,这个包会将其识别为男性。
如果想要进一步做严谨,个人推荐了解一个 github 仓库预测中文姓名的性别
内存管理
Stata:小心文本变量的膨胀
由于 strL 格式无法用于 stata 匹配,我们一般都清晰为固定的文本长度格式,例如 str9s:代表 9 个代码字符长度——一般一个汉字就是 3 个字符占位。
裁判文书免不了处理文本变量,例如法院名称,原告被告名称,案件类型。
文本膨胀是非常恐怖的事情。例如 dta1 法官最长名字是 5 个字符,但是 dta2 由于脏数据混进去了正文,最长字符数 100 个字符。
当我们纵向合并时,所有文本变量这时候所有变量为兼容最长的格式,会统一变成 str100s 格式,这时候多余的空格也会占用内存。当千万级别的裁判文书,n 个文本变量都发生这个膨胀时,就是内存的巨大灾难。
个人的一些默认处理:
Python:流式处理的压缩包
裁判文书 13 年到 19 年全部解压大概内存 1 T 左右,为节约内存,我们可以构造一个流式处理的管理过程。
- 存在 n 个压缩包。
- 解压一个压缩包,提取相关变量(例子代码提取了案号、裁判文书说理性,二审案件时提取一审案号)。
- 删除压缩包
- 可视化当前进度,并记录目前提取了哪些压缩包(断点处理,便于临时停电后接着未完成部分继续处理)
下面是我的代码例子,因为有些压缩包有密码,还加了读取压缩包密码说明文件进行密码解压的过程:
描述统计
环状图
条状图
优化了数字排列方式不重叠
规定了民初、再、终案号的排列顺序
使用了 python 包 pip install aquarel 优化了绘图风格。
均值中位数分布图
包含均值、中位数、累计比例
使用了参数名称映射