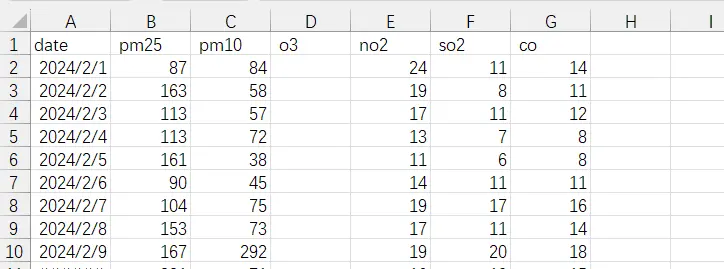
微观数据库例子
前人之述备矣,我只是浅踩了几个坑。 stata、EXCEL、SAS。
一、流行的国内数据库:
大部分微观数据库文件以 DTA、SAS、EXCEL 文件为主。按主体(社区问卷、家庭问卷、社会文件)和主题(背景信息、健康、经济…)分开。每一年的截面数据也是分开的, 所以需要自己处理成面板数据。
用学生邮箱 在官网申请即可。
申请体验:CFPS\CHARLS\CHIP\CGSS 的申请体验非常好。就是网站偶尔会崩掉打不开,申请上就建议马上下载全部数据。
大型、综合数据库
1、CFPS:www.isss.pku.edu.cn/cfps/
中国教育追踪调查: CFPS 由北京大学中国社会科学调查中心(ISSS)实施。跟踪收集个体、家庭、社区三个层次的数据,反映中国社会、经济、人口、教育和健康的变迁,为学术研究和公共政策分析提供数据基础。
2、CMDS:数据申请 (chinaldrk.org.cn)
中国流动人口动态监测数据: 国家卫生健康委自 2009 年起一年一度大规模全国性流动人口抽样调查数据,内容涉及流动人口及家庭成员基本信息、流动范围和趋向、就业和社会保障、收支和居住、基本公共卫生服务、婚育和计划生育服务管理、子女流动和教育、心理文化等。
CMDS已经停止更新
3、CHARLS: 中国健康与养老追踪调查 (pku.edu.cn)
中国健康与养老追踪调查: 中国健康与养老追踪调查。北京大学国家发展研究院主持、中国社会科学调查中心执行的一项大型跨学科调查项目代表中国 45 岁及以上中老年人家庭和个人的高质量微观数据。
4、CSS:中国社会状况综合调查(http://css.cssn.cn/css_sy/ )
中国社会状况综合调查: 中国社会科学院社会学研究所于 2005 年发起的一项全国范围内的大型连续性抽样调查项目,目的是通过对全国公众的劳动就业、家庭及社会生活、社会态度等方面的长期纵贯调查,来获取转型时期中国社会变迁的数据资料,从而为社会科学研究和政府决策提供翔实而科学的基础信息。目前,2006、2008、2022、2013、2015、2017、2019、2021 年,共八期 CSS 数据,已向全社会开放。
5、CHIP:中国家庭收入调查(http://www.ciidbnu.org/ )
中国家庭收入调查: 北京师范大学收入分配研究院发动
6、CGSS:中国家庭收入调查(http://www.cnsda.org/ )
中国综合社会调查(Chinese General Social Survey,CGSS),是中国第一个全国性、综合性、连续性的大型社会调查项目。目的是通过定期、系统地收集中国人与中国社会各个方面的数据,总结社会变迁的长期趋势,探讨具有重大理论和现实意义的社会议题,推动国内社会科学研究的开放性与共享性,为政府决策与国际比较研究提供数据资料。
7、中国统计年鉴: 城市数据、区域数据…
这个网上整理好的面板数据满天飞。
其他:例如还有中国家庭金融调查 CHFS(https://chfser.swufe.edu.cn/datasso/Home/Login?4813085540248732983 )。
我们还可以用一些小的专题数据库来辅助主要数据库进行分析。
例如北大普惠金融数据库:北京大学数字普惠金融指数 、创新创业指数、政府治理指数…
例如现在关于城市数字经济的测量,
还有一些付费网站(学校可能会有买的
经济学还有以上付费数据库,可以看自己学校有没有购买
经济学还有以上付费数据库,可以看自己学校有没有购买
金融数据库不太了解,锐思看起来挺好用
经济方面:中经网、EPS 网页直接整理面板,非常好用。
互联网上的数据库灰色产业 :
二、清洗思路和意义
清洗数据具体做什么?基本上就是完成以下工作。
进行表格匹配 :匹配合并不同的数据库表格,目的是整合筛选指标,分为横向和纵向匹配。去除不良数据: 去除不良数据。例如空白数据、极端数据、不需要的数据………填补空白数据: 填充数据。处理面板数据和时间序列,我们往往通过线性插值的方法补充中间或边缘的缺失值。数据聚合: 通过特定方法数据建立指标,例如主成分、熵权法、层次分析……
最重要的是掌握工!作!流!程!
一般在跑回归时都会发生“变量不够”、“遗失变量”等惨剧,我们随时可能需要返工更新变量,检查失误环节,因此保留完整的流程文件夹是很有必要的。
流程
经验之谈!!!!! 原始数据保留一个文件夹、表格匹配完成后保留一个文件夹、清洗过程再保留一个文件夹!
把代码写成——可以丝滑的一口气从数据清洗运行到结果输出就是流水线的最高境界!
一是能展现我们各个工作步骤,便于检查工作,二是方便随时从中间步骤“返工”。
三、STATA 操作
推荐教程
教程视频,看一个足矣(两小时):
简介里提到了这位 up 个人 githubgithub 主页(录屏和 do 文件)
我个人遇到过的一些情况
1、中文数据库导入转码
中文乱码,要么更新 statastata 版本、要么使用代码
两个方法其实是一个作用。
方法一:处理 cmdscmds 时遇到了
1
2
3
4
5
clear
cd "C:\Users\Desktop\转码" // 新建一个转码文件夹,然后修改自己的路径
unicode encoding set gb18030
unicode analyze 流动人口数据个人问卷 2018 . dta // 文件名根据自己的数据进行调整
unicode translate 流动人口数据个人问卷 2018 . dta , invalid // 文件名根据自己的数据进行调整
方法二:处理 charlscharls 的 PSU. Dta时遇到省份、城市乱码
1
2
3
4
cd "D:\household_and_community_questionnaire_data" // 设置文件储存地点
unicode analyze PSU . dta // PSU . dta换成要编译的文件
unicode encoding set "GB18030"
unicode retranslate psu . dta , transutf8
2、数据库的匹配
无非就是围绕样本的 ID、yearID、year 进行整合
img
Stata 的匹配代码——以下只写简洁解释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// master_data . dta就是基底数据库 , using_data . dta就是我们要匹配上去的数据库
// m : n id 意思就是第一个数据的 m个id可以对应n个第二个数据库的样本id
// 简而言之, m : n就是多对一 , n : n就是1对1 , m : m就是多对多
// 所以我们也可以添加多个匹配条件,例如 merge 1 : 1 id year treat ......
************ 横向匹配 1 **************************
use "master_data.dta"
merge m : n id using "using_data.dta"
drop _merge
save "new_data.dta"
************ 横向匹配 2 **************************
use "master_data.dta"
joinby id using "using_data.dta"
************ 纵向匹配 **************************
use "data1.dta"
append using "data2.dta"
save "new_data.dta"
merge 适合匹配方或者被匹配方的标识是唯一 的。
一对多匹配时,比如主数据标识是唯一的,被匹配数据虽然重复,但每个重复标识行分别在不同的变量空缺,可以使用 merge 的追加匹配子命令,每次匹配只更新空缺部分。
1
2
use "master_data.dta"
merge 1:m id using "using_data.dta", update nogen force
多对多的匹配,需要使用 joinby。
详细情况可参考: 多对多合并-merge-joinby
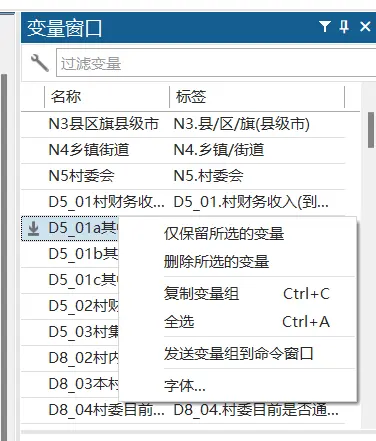
3、变量的快速选择
Shift\ctrl 这类快捷键基本是软件设计通用的,用多了就能融会贯通到其他软件里。
Stata 右上角有个变量窗口。右键可以得到全选和其他选择,也可以充当检索框。
同时选择就是 ctrl+多次点击。如果我们需要一口气同时选择断断续续的十几个变量,请积极使用。
截取中间一段,就是点击一个变量,然后同时 shift+单击一个变量,就是截取中间一段
例如,可以先右键,全选,然后 ctrl+点击去掉不要的变量;
在python拥有这种窗口前我不会认为跑回归这事它优于stata
4、插值法
线性插值,面板数据,
老规矩,面板先标记个体编号和年份编号 ,
1
2
3
xtset id year
by id : ipolate YY year , gen ( YYY ) // 内插,中间空缺值,填完后命名为新变量 YYY
by id : ipolate XX year , gen ( XXX ) epolate // 外插,边缘空缺值,填完后命名为新变量 XXX
我的建议是,能用 forvalues 就用 forvalues
当知道了基础的循环命令+变量嵌套+判断筛选命令,编写代码就可以天马行空了。
例如下面这个批量插值循环如下:
$var_i \stackrel{内插}{\longrightarrow}varx_i\stackrel{外插}{\longrightarrow}varn_i\stackrel{替换}{\longrightarrow}var_i\stackrel{删除}{\longrightarrow}varx_i $
1
2
3
4
5
6
7
8
global var var0 var1 var2 var3 genshin
* 打包所有需要插值的变量
foreach i in $ var {
by id : ipolate ` i ' year,gen(varx`i' )
by id : ipolate varx ` i ' year,gen(varn`i' ) epolate
replace ` i ' = varn`i'
drop varx ` i ' varn`i'
}
同理,清洗问卷数据的不良数据也是一样的循环
1
2
3
4
5
6
7
8
global var var0 var1 var2 var3 genshin
* 打包所有需要插值的变量
foreach i in $ var {
drop if ` i ' == -88
drop if `i' == - 99
drop if ` i ' ==.
drop if `i' <= 0
}
互联网还流传着一个“一键显著”的清洗。思想就是暴力排列组合控制变量,后面甚至开始筛选样本了。我的看法是,可以看看选控制变量的代码,但别随意动样本,经济学计量发展的一个核心灵魂就是“随机实验”,干预样本选择容易破坏数据随机性,基本上就是造假了。
(不过仅就代码思维来说,这确实体现了当你掌握了筛选,判断,循环的命令后,你可以干的事已经非常多了,同样是清洗,如何进行算法组合就是考验人的地方。)
5、字符转数字:
例如 charls 数据库的 communityID 就是以字符形式存在的。
虽然中文作为变量名也可以匹配,但当长度太长时 stata 似乎不能处理,强制 转化成数字:
1
destring ID householdID communityID , replace force * 加上 force ,正义执行!
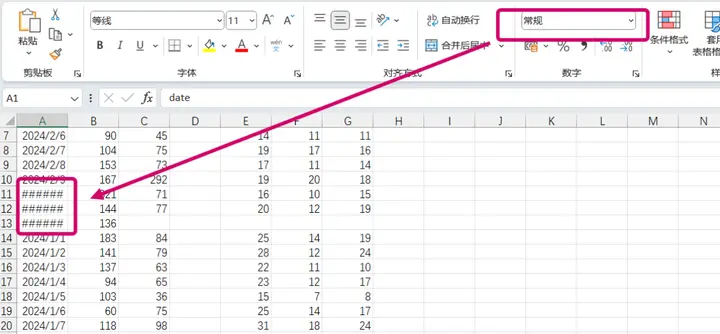
6、日期转码 有些时候我们下载的日期代码不能被 stata 识别,此时要用到 date 函数。
例如一次课堂作业,我想展现中国的自信!艾媒咨询 的华为、苹果笔记本淘宝数据。世界银行 。
但尴尬的是,里面 Excel 加载的日期格式为 Y-M-D, stata 不能直接识别
2是华为,1是苹果,销量是nurmber,日期是year那列
使用代码:(我在经管之家找的代码)
1
2
3
4
clear
import excel "E:\桌面\笔记本.xlsx" , sheet ( "Sheet1" ) firstrow
generate date = date ( year , "YMD" ) // 识别日期
format date % td // 进一步转化
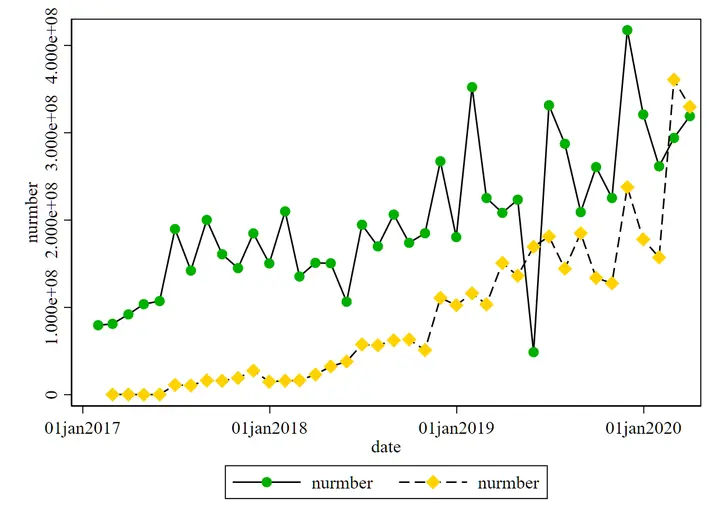
绿色是苹果,金色是华为。可以看到date被处理后变成特殊的日期形式,而且可以直接用stata画散点图。原始图不见了,就简单重画了,请勿在意这鬼畜的配色
绿色是苹果,金色是华为。可以看到 date 被处理后变成特殊的日期形式,而且可以直接用 stata 画散点图。原始图不见了,就简单重画了,请勿在意这鬼畜的配色
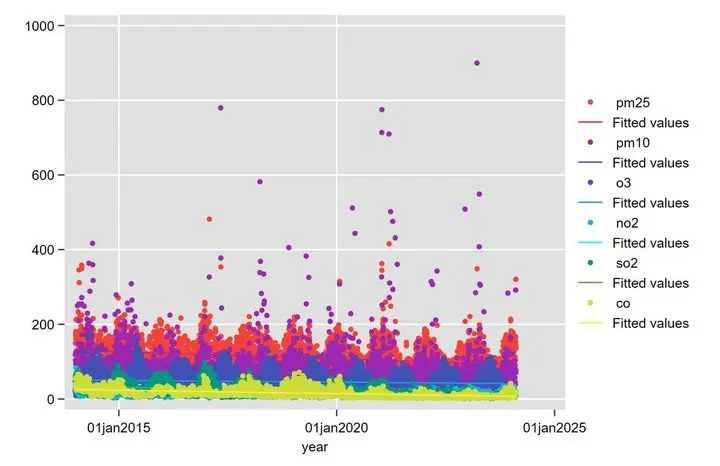
再举例一份关于空气污染的数据。Excel 中 date 一栏为“短格式日期 ”
img
导入 stata 使用 date 函数,进行画图
1
2
generate year = date ( date , "YMD" ) // 识别日期
format year % td // 进一步转化
根据这个图很容易发现季节上的周期性
通过描述统计画图可以看出空气污染在季节上有周期性。于是我们想把月份单独切片出来进行季节编号。
1
2
3
4
5
6
7
8
9
10
generate month = month ( year ) // 对已经处理后的year日期进行月份切片
// 更详细解释可以参考 : https :// stata - club . github . io / stata_article / 2017 - 10 - 29 . html
gen spring = 1 if month == 3 | month == 4 | month == 5
replace spring = 0 if spring ! = 1
gen summer = 1 if month == 6 | month == 7 | month == 8
replace summer = 0 if summer ! = 1
gen fall = 1 if month == 9 | month == 10 | month == 11
replace fall = 0 if fall ! = 1
gen winter = 1 if month == 12 | month == 1 | month == 2
replace winter = 0 if winter ! = 1
根据季节分类进行拟合会发现线性趋势更加明显。我们发现温度和污染具有相关性所以前一个图呈现周期性,我们也可以提出假设温度越低,暖气、热炕、煤炭的使用导致空气污染增多
7、删除和条件语句
Stata 删除特定列的命令是 drop 命令。
建议直接"h drop"查看说明。
活用 if 条件、forvalues 循环命令就是考验算法素养的时候!
你要处理怎样的数据,你的目的是什么?
目的可以怎样分解,可以分解成怎样的流程,怎样的 if 条件筛选更快,怎样的 forvalues 循环可以尽快地简化你的清洗步骤?
活用 stata 的 do 文件,考虑代码的复用性,这样写代码后,之后能不能循环重复利用,例如只换变量名词。
8、去尾处理
使用 winsor2 命令,是连玉君老师 写的命令。
1
2
histogram var , ylabel (, angle ( 0 )) xtitle ( "横坐标名字" ) name ( 图片文件名 , replace ) \\频数图绘制下分布看看
winsor2 var , cut ( 0 97.5 ) trim replace \\去掉变量 var右侧2 . 5 % 的极端数据
9、分组处理
按照变量“国界”分组,计算每组对应变量的
1
2
3
4
5
6
bysort 国界 : egen 乡村振兴边境 = mean ( 乡村振兴 )
bysort 国界 : egen 产业兴旺边境 = mean ( 产业兴旺 )
bysort 国界 : egen 生态宜居边境 = mean ( 生态宜居 )
bysort 国界 : egen 治理有效边境 = mean ( 治理有效 )
bysort 国界 : egen 乡风文明边境 = mean ( 乡风文明 )
bysort 国界 : egen 生活富裕边境 = mean ( 生活富裕 )
10、排序处理
想让数据根据一些标准从小到大排列,使用 sort 命令
1
sort year age income // 首先按照年份排序 , 相同年份的一列中按照年龄排序 , 同年同年龄就按收入排序
11、删去重复行
1
duplicates drop var , force
12、截取字符
中文字符一个字符就是三个位置
12、一些描述统计图
一些可视化代码网站
个人推荐自定义换行符, 这样画图命令更加优雅:
1
2
3
4
5
6
7
8
9
10
11
12
13
#delimit;
;
gen di = year - branch_reform ;
eventdd entre_activation i . year lnagdp indust_stru finance ainternet market ,
timevar ( di ) // 定义时间虚拟变量
ci ( rcap ) // 误差条
noline // 不绘制 - 1 期的置信区间条
method ( fe ) // 如果要添加自相关聚类—— method ( fe , cluster ( 自相关聚类 ))
baseline ( 0 ) // 基础年份为 0
level ( 95 )
graph_op ( ytitle ( "coefficients" ) xtitle ( "Time" ) xlabel ( - 10 ( 2 ) 14 )); // 取消自定义换行
#delimit cr
图片合并
1
graph combine "a.gph" "b.gph", col(1) xcommon ycommon
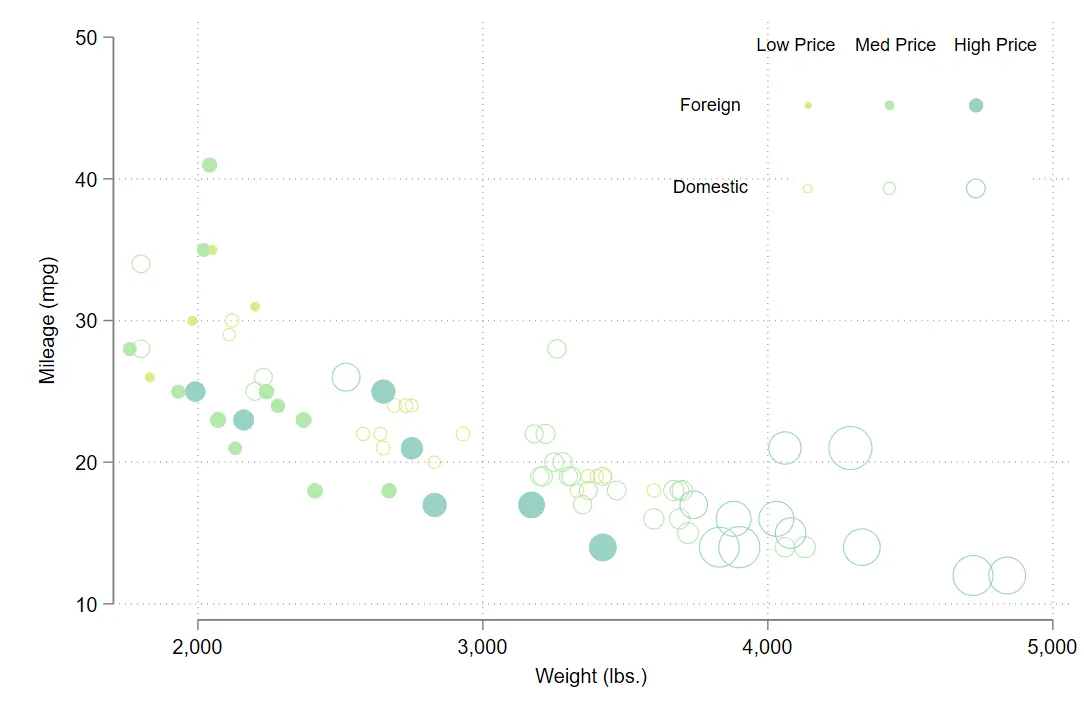
气泡图
在 Stata绘制高级气泡图 看到的,很有意思
1
2
3
4
5
6
7
8
9
10
11
12
sysuse auto , clear
set scheme white_tableau // 设置主题,小伙伴可以根据自己的喜好自行设置
twoway ///
( scatter mpg weight [ w = price ] if foreign == 0 & price <= 4220 , msymbol ( Oh ) mcolor ( "220 235 136" ) msize ( small )) ///
( scatter mpg weight [ w = price ] if foreign == 1 & price <= 4220 , msymbol ( o ) mcolor ( "220 235 136" ) msize ( small )) ///
( scatter mpg weight [ w = price ] if foreign == 0 & ( price > 4220 & price <= 6332 ), msymbol ( Oh ) mcolor ( "180 232 172" ) msize ( medium )) ///
( scatter mpg weight [ w = price ] if foreign == 1 & ( price > 4220 & price <= 6332 ), msymbol ( o ) mcolor ( "180 232 172" ) msize ( medium )) ///
( scatter mpg weight [ w = price ] if foreign == 0 & price > 6332 , msymbol ( Oh ) mcolor ( "152 210 196" ) msize ( large )) ///
( scatter mpg weight [ w = price ] if foreign == 1 & price > 6332 , msymbol ( o ) mcolor ( "152 210 196" ) msize ( large )), ///
xlabel ( 2000 ( 1000 ) 5000 ) ylabel ( 10 ( 10 ) 50 ) legend ( label ( 1 " " ) label ( 2 " " ) label ( 3 " " ) label ( 4 " " ) label ( 5 " " ) label ( 6 " " ) order ( 2 4 6 1 3 5 ) row ( 2 ) ring ( 0 ) size ( 10 ) position ( 2 ) bmargin ( medlarge )) text ( 45 . 3 3800 "Foreign" , size ( * 0 . 7 )) text ( 39 . 5 3800 "Domestic" , size ( * 0 . 7 )) text ( 49 . 5 4100 "Low Price" , size ( * 0 . 7 )) text ( 49 . 5 4450 "Med Price" , size ( * 0 . 7 )) text ( 49 . 5 4800 "High Price" , size ( * 0 . 7 ))
// mycolor中为RGB颜色编码 ,可以自己根据喜好定义;
// xlabel和ylabel分别设置横纵轴的标签 ; legend设置图例 ; text设置文字的具体位置 ,具体格式 text ( y坐标 x坐标 "标签文本" )
气泡散点图
折线图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
twoway ///
( line var2 date if group == 1 ) ///
( line var2 date if group == 2 ) ///
( line var2 date if group == 3 ) ///
( line var2 date if group == 4 ) ///
( line var2 date if group == 5 ) ///
( line var2 date if group == 6 ) ///
( line var2 date if group == 7 ) ///
( line var2 date if group == 8 ) ///
( line var2 date if group == 9 ) ///
( line var2 date if group == 10 ) ///
( line var2 date if group == 11 ) ///
( line var2 date if group == 12 ) ///
, ///
legend ( order ( 1 "group1" 2 "group2" 3 "group3" 4 "group4" 5 "group5" 6 "group6" 7 "group7" 8 "group8" 9 "group9" 10 "group10" 11 "group11" 12 "group12" )) ///
title ( "Line plot" ) ///
note ( "The Stata Guide" , size ( vsmall ))
饼图
1
2
3
4
5
6
graph pie var2 if group <= 10 , ///
over ( group ) plabel ( _all percent , format ( % 9 . 2 f )) ///
line ( lcolor ( black ) lwidth ( vvthin )) ///
// outline colors have to be manually added
title ( "Pie plot" ) ///
note ( "The Stata Guide" , size ( vsmall ))
箱线图
1
2
3
4
5
graph box ///
var * ///
, ///
title ( "Box plot" ) ///
note ( "The Stata Guide" , size ( vsmall ))
柱状图
1
2
3
histogram var4 , percent ///
title ( "Histogram" ) ///
note ( "The Stata Guide" , size ( vsmall ))
加上核密度线
1
2
3
4
histogram var4 , ///
ylabel (, angle ( 0 )) ///
xtitle ( "税收" ) ///
kdensity
竖向条形图
1
2
3
4
5
6
graph bar ///
var * ///
, ///
blabel ( bar , format ( % 9.2 f )) ///
title ( "Bar graph" ) ///
note ( "The Stata Guide" , size ( vsmall ))
横向条形图
1
2
3
4
5
6
7
8
graph hbar ( mean ) ///
var * ///
if group <= 6 , ///
over ( group ) ///
percentages stack ///
legend ( order ( 1 "Var 1" 2 "Var 2" 3 "Var 3" 4 "Var 4" 5 "Var 5" 6 "Var 6" )) ///
title ( "Bar graph" ) ///
note ( "The Stata Guide" , size ( vsmall ))
置信区间
1
2
3
4
5
6
7
twoway ///
( lpolyci var1 var9 , fcolor ( % 80 )) ///
( lpolyci var2 var9 , fcolor ( % 80 )) ///
( lpolyci var3 var9 , fcolor ( % 80 )) ///
, ///
title ( "Confidence Interval" ) ///
note ( "The Stata Guide" , size ( vsmall ))
范围区间
1
2
3
4
5
6
twoway ///
( rcapsym var2 var3 date if group == 1 , sort ) ///
( rcapsym var2 var3 date if group == 2 , sort ) ///
, ///
title ( "Range plots" ) ///
note ( "The Stata Guide" , size ( vsmall ))
面积图
1
2
3
4
5
6
twoway ///
(area den1d den1x, fcolor(%50)) ///
(area gen2d gen2x, fcolor(%50)) ///
(area gen3d gen3x, fcolor(%50)), ///
title("Density plots") ///
note("The Stata Guide", size(vsmall))
标签散点
1
2
3
4
twoway ///
( scatter var2 var1 , mlabel ( group )) ///
if date == 22320 /// , /// title ( "Confidence Interval" ) ///
note ( "The Stata Guide" , size ( vsmall ))
分组散点图
1
2
3
4
5
twoway ///
( scatter var2 var1 ) ///
if group <= 12 , ///
by ( group , yrescale xrescale ) ///
by (, title ( "By graphs" ) note ( "The Stata Guide" , size ( vsmall )))
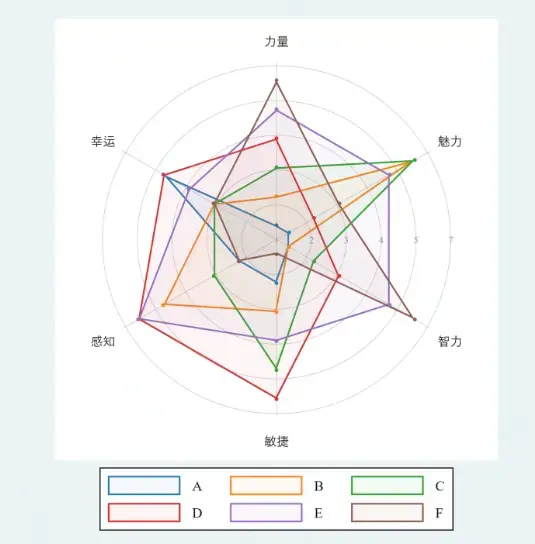
雷达图
radar 和 spyder 都可以,个人觉得蛛网好看很多。
雷达图可以参考 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
ssc install palettes , replace
ssc install colrspace , replace
ssc install schemepack , replace
* 更新
ado update , update
clear
input strL 属性 A B C D E F
力量 2 2 6 4 5 6
敏捷 1 1 3 4 3 6
智力 3 2 2 4 5 6
感知 2 5 1 6 2 5
魅力 4 6 4 5 6 5
幸运 5 3 3 5 4 4
end
compress
spider A - F , over ( 属性 )
sysuse auto , clear
radar make weight if foreign
蛛网图
13、绘图风格
参见最强绘画包
个人最推荐 Rainbow 风格和 gg_tableau。
gg 系列模仿的是 R 语言的默认风格,Rainbow 色彩很明亮,够特立独行,我也喜欢封闭的 box 纯白背景。不过要注意 Rainbow 风格由于背景默认是网格图,不太方便自定义参考线。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
ssc install schemepack , replace
* set scheme white_tableau
* set scheme black_tableau
* set scheme gg_tableau
* set scheme white_tableau
* set scheme Rainbow
汇总风格如下——
Series :
Tableau - white_tableau black_tableau gg_tableau
Cividis - white_cividis black_cividis gg_cividis
Viridis - white_viridis black_viridis gg_viridis
Hue - white_hue black_hue gg_hue
BrBg - white_brbg black_brbg gg_brbg
PiYg - white_piyg black_piyg gg_piyg
pTol - white_ptol black_ptol gg_ptol
Jet - white_jet black_jet gg_jet
w3d - white_w3d black_w3d gg_w3d
Standalones :
Rainbow - rainbow
Neon - neon
Taylor Swift 's Red - swift_red
Ukraine - ukraine
Colorblind-friendly schemes:
Tab1 - tab1
Tab2 - tab2
Tab3 - tab3
cblind1 - cblind1
更多:
stata数据清洗管理的常用技能知识, 资源错配的代码
四、STATA 转 EXCEL dta 文件如何转 excel?
代码为:
1
export excel using "data.xlsx" , firstrow ( variables )
其中 firstrow (variables) 指 excel 行保留为变量名
五、EXCEL
0、常见乱码
一些下面这些样的 excel/csv 乱码是因为格式不对,例如下图,把文本框格式调整为日期即可。
img
1、VLOOKUP 函数
用多了就觉得 stata 比 Excel 快多了。例如我做个一个任务是关描述统计乡村振兴水平,其中要展示各项指标平均值以上的村数,如果是 excel 还是比较麻烦的,涉及判断的(如果没有掌握 VBA 语言的话),stata 处理会更加快速。
1
2
3
4
5
6
7
8
9
global $ xlist x1 x2 x3 x4 x5
foreach i in $ xlist {
egen b = mean ( ` i ')
gen a = 1 * ( b < ` i ') + 0 * ( b >= ` i ')
egen sum_ ` i ' = sum ( a )
drop a
drop b
}
经济最好找数据和分析的肯定是城市面板数据了,
请参考:链接 里还贴心地附上了城市代码,强烈感谢!
使用 vlookup 函数时,还可能遇见的一种情况 ,excel 的格式设置真是千奇百怪!
2、数据透视表
简单清洗计数 和相对复杂的分组求和 时用。
插入-数据透视,Excel 现在这个功能还挺智能的,主要是清洗一些需要累计的面板数据时非常好用。
注意:数据透视表的“累加函数”需要 excel 格式为“数值”,“计数函数”则不限定格式。
img
3、字符拆卸
就经济学的计量而言,目前顶流方案当属 DID。
比如拆试点城市的集合“北京,重庆,天津,上海”,
可以选中该空格,$数据\Rightarrow分列$,
“文本分列向导”对话框选择“分隔符号”,点击“下一步”,勾选“分隔符号”中的“,”。
此时就可以完成分行。再结合 VLOOKUP 函数匹配即可。
4、删改字符
巧妙运用 vlookup 已经能应对大多数情况,但依旧不够!数据清洗之坑防不胜防
有些 Excel 文件 cityid 是 1100,有些是 110000市 !
Excel 去字符操作:A 2=LEFT (A 1,LEN (A 1)-1)
Excel 加字符操作:A 2=A 1&“市”
5、数据库合并
请看大屏幕 !
六、结束
这几天经管之家关闭了,
发觉好多 stata 的基础问题都找不到问的地方,,,,,
90%的问题都是从知乎、经管之家、B 站找到的解决方法。
可谓前人之述备矣,我只浅踩了几个坑。
参考