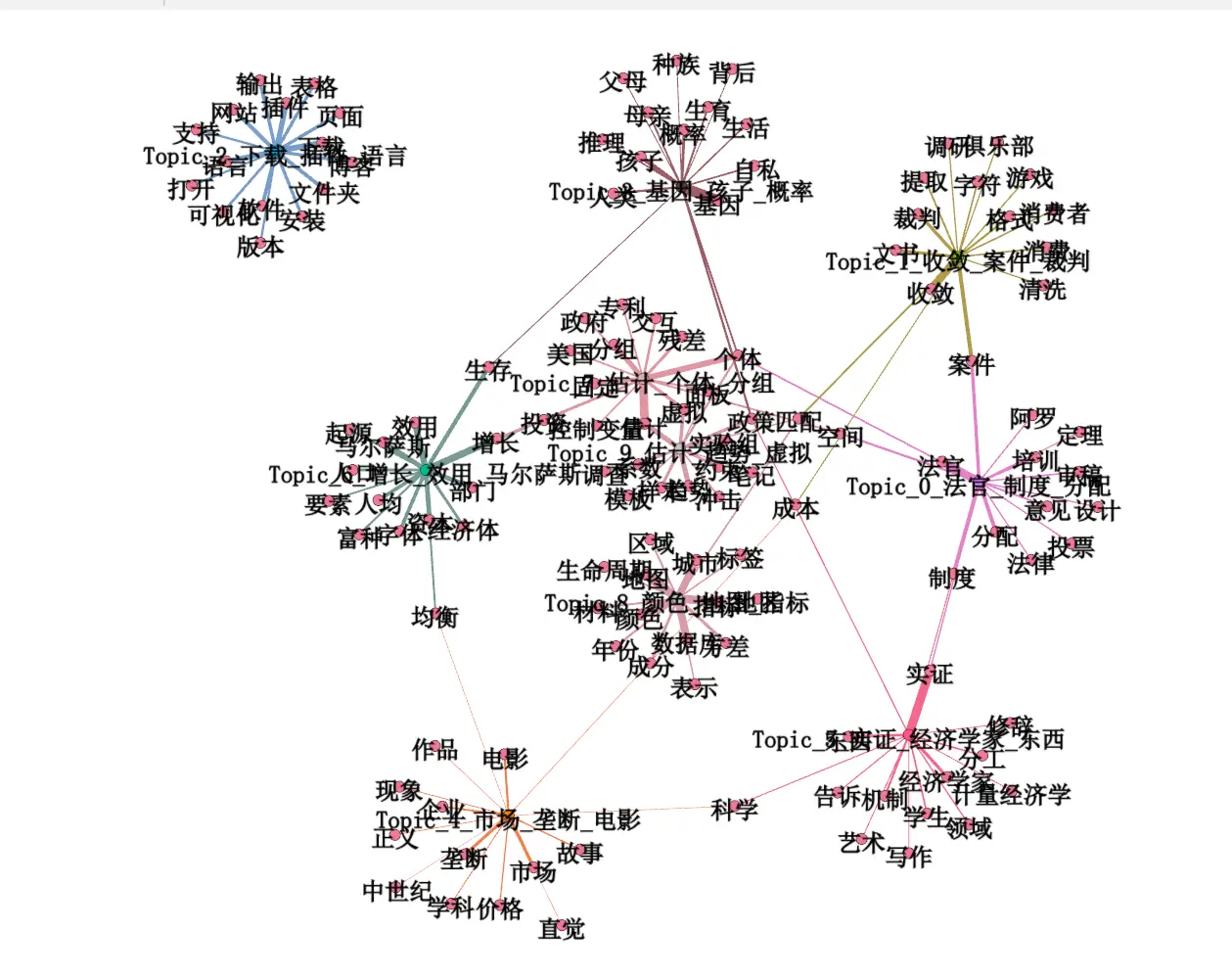
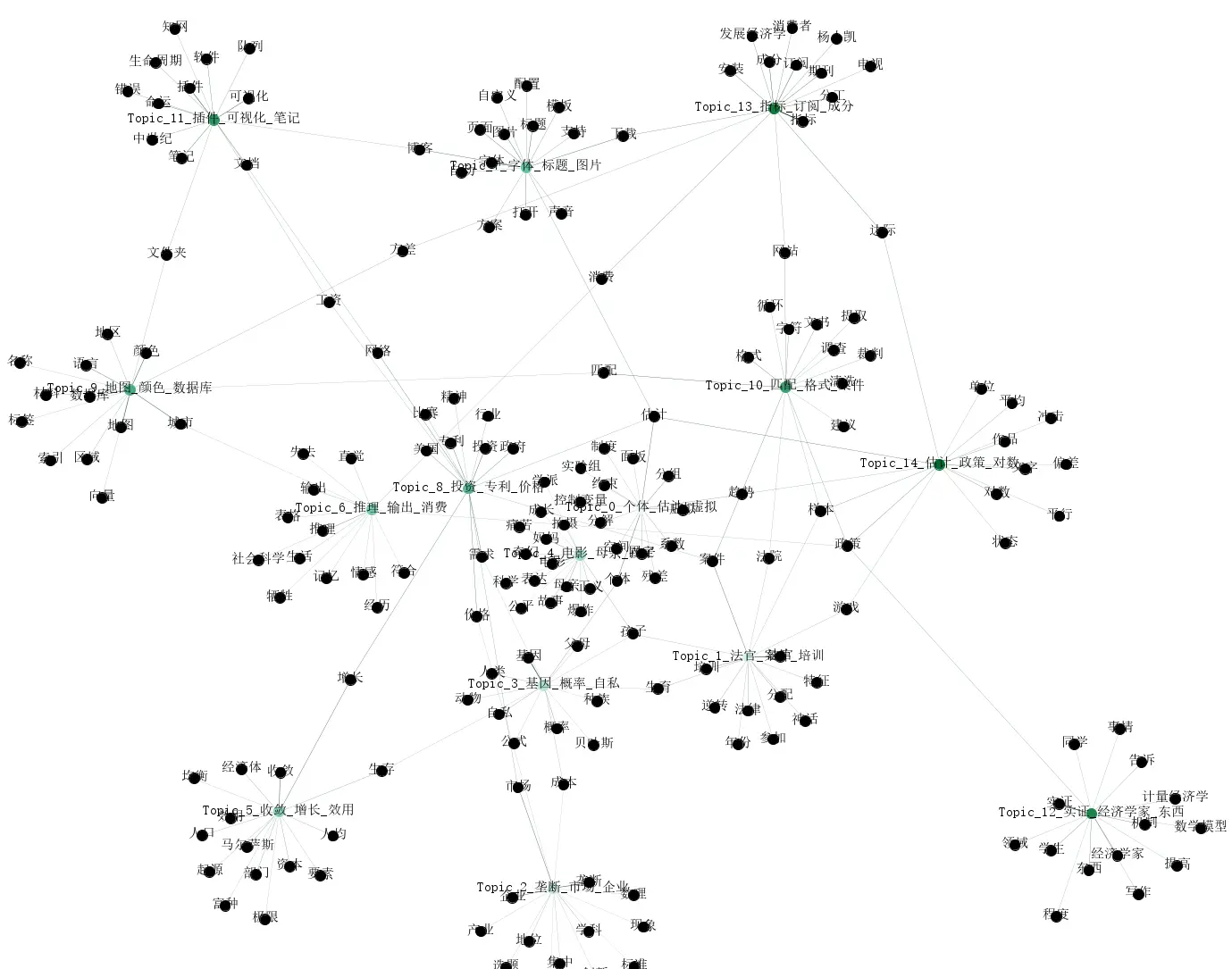
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
|
# -*- coding: utf-8 -*-
"""
优化 LDA 管道:支持 Markdown (.md) 文档、自动停用词、词性过滤
- 使用 LdaMulticore 多线程训练
- 支持豁免词强制保留为主题关键词
- 可直接生成 Gephi 二部图
"""
import os
import glob
import re
import jieba
import jieba.posseg as pseg
import pandas as pd
import networkx as nx
from collections import defaultdict
from gensim import corpora
from gensim.models.ldamulticore import LdaMulticore
# Markdown 解析
try:
import markdown
from bs4 import BeautifulSoup
except ImportError:
print("错误:缺少必要库,请执行 'pip install markdown beautifulsoup4'")
exit()
# -------------------- 配置 --------------------
DOCS_GLOB = "/root/博客分析/数据/原始博客/*.md"
STOPWORDS_PATH = "/root/博客分析/数据/设置/分词stop.txt"
OUTPUT_DIR = "/root/博客分析/数据/结果输出"
# 词典和语料参数
NO_BELOW = 3 # 词语至少出现的文档数
NO_ABOVE = 0.8 # 词语在文档中出现比例上限
KEEP_N = 100000 # 词典最大词数
# LDA 模型参数
NUM_TOPICS = 10 # 主题数
TOPN = 15 # 每个主题显示的关键词数量
PASSES = 20 # LDA训练轮数
WORKERS = 28 # 多线程数(建议 = CPU核心数 - 1)
CHUNKSIZE = 5000 # 每批处理文档数量
BATCH = True # 是否使用小批量训练
# 分词与停用词
USE_POS_FILTER = True
POS_BLACKLIST = set(['x', 'c', 'u', 'd', 'p', 't', 'm', 'q', 'r'])
USE_AUTO_DF_STOPWORDS = True
AUTO_DF_THRESHOLD = 0.8
AUTO_DF_TOPK = 200
# 额外停用词
ADDITIONAL_STOPWORDS = set([
'什么', '推荐', '获取', '点击', '生成', '绘制',
'存在', '问题', '使用', '可以', '我们', '现在', '通过', '文章', '内容', '研究法', '人为', '保留', '来讲', '叫魂', '学家'
])
DEFAULT_STOPWORDS = set([
'的', '了', '和', '是', '在', '就', '都', '而', '及', '与', '或', '一个',
'我', '你', '他', '她', '它', '我们', '你们', '他们', '她们', '这', '那', '其', '又', '被', '上', '中', '对', '所', '为', '于'
])
# 豁免词(强制保留为主题关键词)
WHITELIST_WORDS = set(['经济', '国家', '政府', '政策', '文学'])
# 文本清理正则
RE_CLEAN = re.compile(r"[\s\d\u0000-\u007F]+")
# -------------------- 函数 --------------------
def extract_text_from_markdown(md_content):
html = markdown.markdown(md_content)
soup = BeautifulSoup(html, 'html.parser')
for tag in soup(['pre', 'code']):
tag.decompose()
return soup.get_text(separator=' ')
def load_stopwords(path):
sw = set()
if os.path.exists(path):
with open(path, 'r', encoding='utf-8', errors='ignore') as f:
for line in f:
w = line.strip()
if w:
sw.add(w)
combined = set(DEFAULT_STOPWORDS) | set(ADDITIONAL_STOPWORDS) | sw
return combined
def load_documents(glob_pattern):
docs, filenames = [], []
file_list = sorted(glob.glob(glob_pattern, recursive=True))
if not file_list:
print(f'未找到文件: {glob_pattern}')
return filenames, docs
print(f'找到 {len(file_list)} 个文件')
for fp in file_list:
try:
with open(fp, 'r', encoding='utf-8', errors='ignore') as f:
raw_text = f.read().strip()
if raw_text:
clean_text = extract_text_from_markdown(raw_text)
docs.append(clean_text)
filenames.append(os.path.basename(fp))
except Exception as e:
print(f'读取失败 {fp}: {e}')
return filenames, docs
def auto_find_generic_terms(tokens_list, threshold=AUTO_DF_THRESHOLD, top_k=AUTO_DF_TOPK):
n_docs = len(tokens_list)
if n_docs == 0:
return set()
df = defaultdict(int)
for tokens in tokens_list:
for t in set(tokens):
df[t] += 1
df_ratio = {t: cnt / n_docs for t, cnt in df.items()}
high_df = {t for t, r in df_ratio.items() if r >= threshold}
if len(high_df) < top_k:
sorted_by_df = sorted(df.items(), key=lambda x: x[1], reverse=True)
high_df |= {t for t, _ in sorted_by_df[:top_k]}
return high_df
def preprocess(text, stopwords, use_pos_filter=USE_POS_FILTER, pos_blacklist=POS_BLACKLIST):
if not isinstance(text, str):
return []
text = RE_CLEAN.sub(' ', text)
if use_pos_filter:
words = []
for w, flag in pseg.cut(text):
short_flag = flag.split()[0] if flag else flag
if (short_flag in pos_blacklist or w in stopwords or len(w) <= 1) and w not in WHITELIST_WORDS:
continue
words.append(w)
return words
else:
tokens = [t for t in jieba.lcut(text) if (t not in stopwords or t in WHITELIST_WORDS) and len(t) > 1]
return tokens
# -------------------- 主流程 --------------------
def main():
os.makedirs(OUTPUT_DIR, exist_ok=True)
print('加载停用词...')
stopwords = load_stopwords(STOPWORDS_PATH)
print(f'加载了 {len(stopwords)} 个停用词')
print('加载 Markdown 文档...')
filenames, docs = load_documents(DOCS_GLOB)
print(f'成功处理 {len(docs)} 篇文档')
if len(docs) == 0:
return
print('文本预处理...')
texts = [preprocess(d, stopwords) for d in docs]
if USE_AUTO_DF_STOPWORDS:
print('自动检测高频泛用词...')
detected = auto_find_generic_terms(texts)
detected -= WHITELIST_WORDS # 豁免词不加入停用词
if detected:
print(f'检测到 {len(detected)} 个泛用词,加入停用词重新处理')
stopwords |= detected
texts = [preprocess(d, stopwords) for d in docs]
total_tokens = sum(len(text) for text in texts)
print(f'共 {total_tokens} 个有效词汇')
print('构建词典与语料...')
dictionary = corpora.Dictionary(texts)
dictionary.filter_extremes(no_below=NO_BELOW, no_above=NO_ABOVE, keep_n=KEEP_N)
corpus = [dictionary.doc2bow(text) for text in texts]
print(f'文档数量: {len(corpus)}, 词典大小: {len(dictionary)}')
print('训练 LDA 模型 (多线程)...')
lda = LdaMulticore(
corpus=corpus,
id2word=dictionary,
num_topics=NUM_TOPICS,
passes=PASSES,
workers=WORKERS,
chunksize=CHUNKSIZE,
batch=BATCH,
random_state=42,
per_word_topics=True
)
model_path = os.path.join(OUTPUT_DIR, 'lda_model.model')
lda.save(model_path)
print(f'LDA 模型已保存: {model_path}')
# 主题关键词
topics = lda.show_topics(num_topics=NUM_TOPICS, num_words=TOPN, formatted=False)
rows_kw = []
print('\n主题关键词:')
for tid, terms in topics:
topic_words = ', '.join([f'{w}({p:.4f})' for w, p in terms])
print(f'Topic {tid}: {topic_words}')
for rank, (word, prob) in enumerate(terms, start=1):
rows_kw.append({'topic': tid, 'rank': rank, 'word': word, 'weight': float(prob)})
pd.DataFrame(rows_kw).to_csv(os.path.join(OUTPUT_DIR, 'topic_keywords.csv'),
index=False, encoding='utf-8-sig')
# 文档-主题分布
rows_dt = []
for doc_id, bow in enumerate(corpus):
doc_topics = lda.get_document_topics(bow, minimum_probability=0.0)
for tid, weight in doc_topics:
rows_dt.append({'doc': filenames[doc_id], 'doc_id': doc_id, 'topic': int(tid), 'weight': float(weight)})
pd.DataFrame(rows_dt).to_csv(os.path.join(OUTPUT_DIR, 'doc_topic.csv'),
index=False, encoding='utf-8-sig')
print('文档-主题分布已保存')
# 构建 Topic-Term 二部图
print('构建 Topic-Term 二部图...')
G = nx.Graph()
for tid, terms in topics:
top_words = [w for w, _ in terms[:3]]
topic_label = f"Topic_{tid}_" + "_".join(top_words)
G.add_node(f'topic_{tid}', label=topic_label, type='topic', topic_id=tid)
for term, prob in terms:
if not G.has_node(term):
G.add_node(term, label=term, type='term')
G.add_edge(f'topic_{tid}', term, weight=float(prob))
nx.write_gexf(G, os.path.join(OUTPUT_DIR, 'gephi_topic_term.gexf'))
print('Topic-Term 二部图已保存')
# 输出文件信息
print('\n全部完成! 生成文件:')
for fn in ['lda_model.model', 'topic_keywords.csv', 'doc_topic.csv', 'gephi_topic_term.gexf']:
path = os.path.join(OUTPUT_DIR, fn)
if os.path.exists(path):
print(f' - {path} ({os.path.getsize(path)/1024:.1f} KB)')
if __name__ == '__main__':
main()
|