引入
何谓爬虫?即“可见即可得”的抓取。每一个网站都有源代码,源代码中自然就包含了网站显示的信息。抓取源代码时,数据和代码混杂在一起,我们再进行清洗就可以得到干净的数据。 stata 代码附件放在结尾。爬虫代码复用性并不高,本文主要是记录爬虫学习过程。
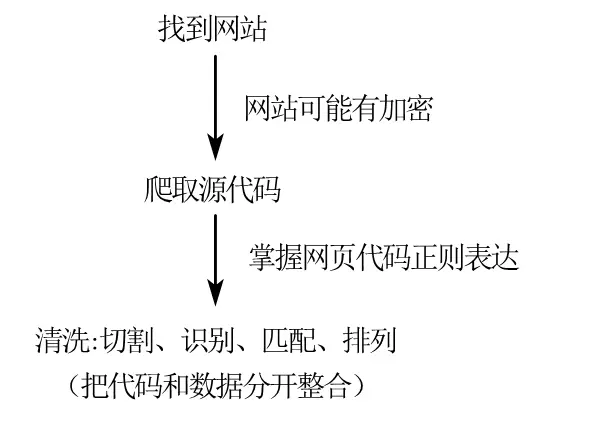
爬虫流程
从整个爬虫过程来说,获取网站源代码是最关键的一步 。对于严格加密的网站(例如"中国裁判文书网"),还要伪装 ip,进行多账号切换,突破文字加密等,遗憾的是这些 stata 都做不到。Stata 擅长的是对没有防备的网站爬取然后快速清洗,处理数据。虽然 stata 擅长的这部分——“切分代码和数据"只是熟练度的问题,不过对于个人来说,使用 stata 进行爬虫的初步学习还是挺友好的。
一、抓取网页源代码
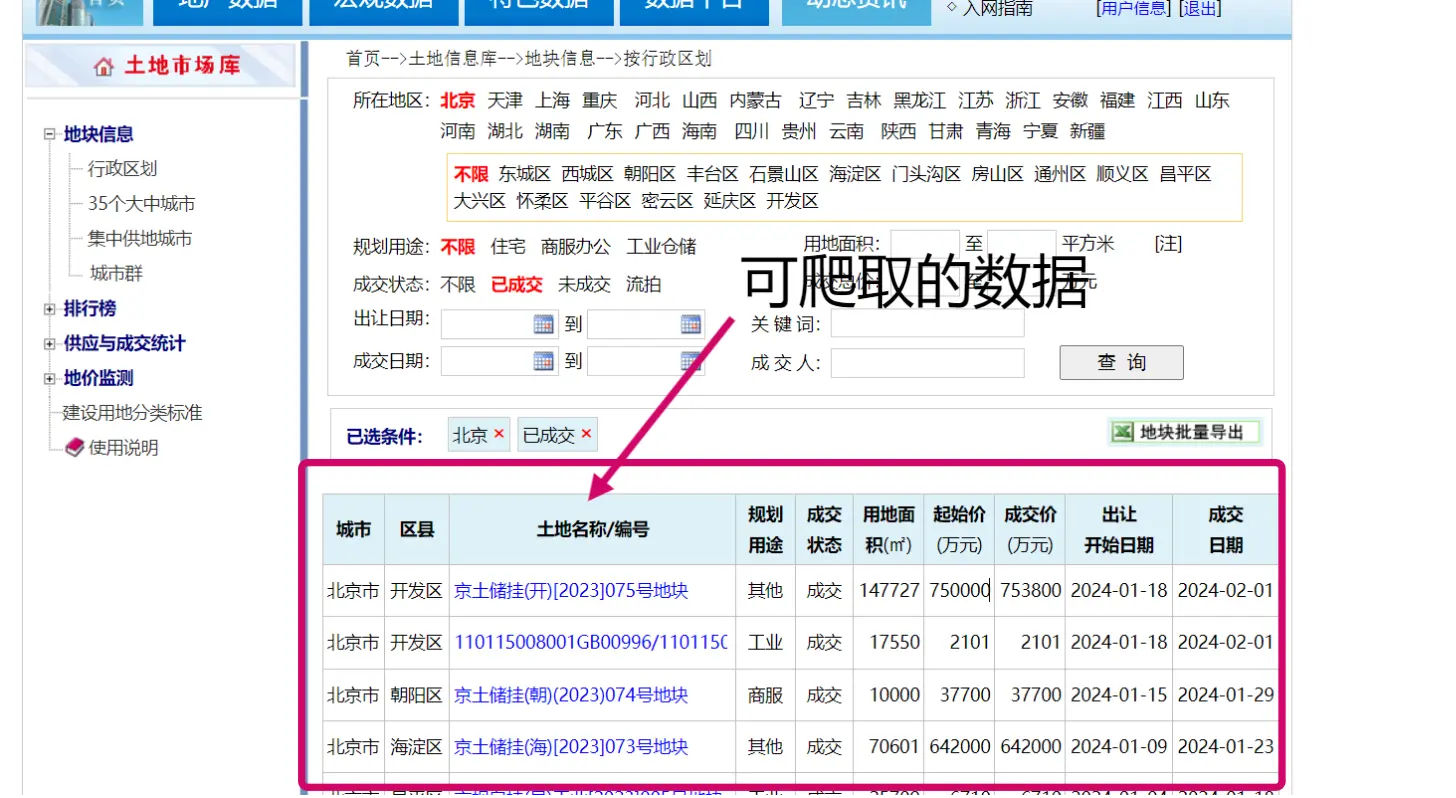
数据网站:国信房地产信息网-土地市场库网站页面如下:
部分学校购买了该数据库,可以看看能否 ip 登陆。
使用 python 能伪装 ip 登陆,stata 目前似乎不行,本文只做学习分享。
网站
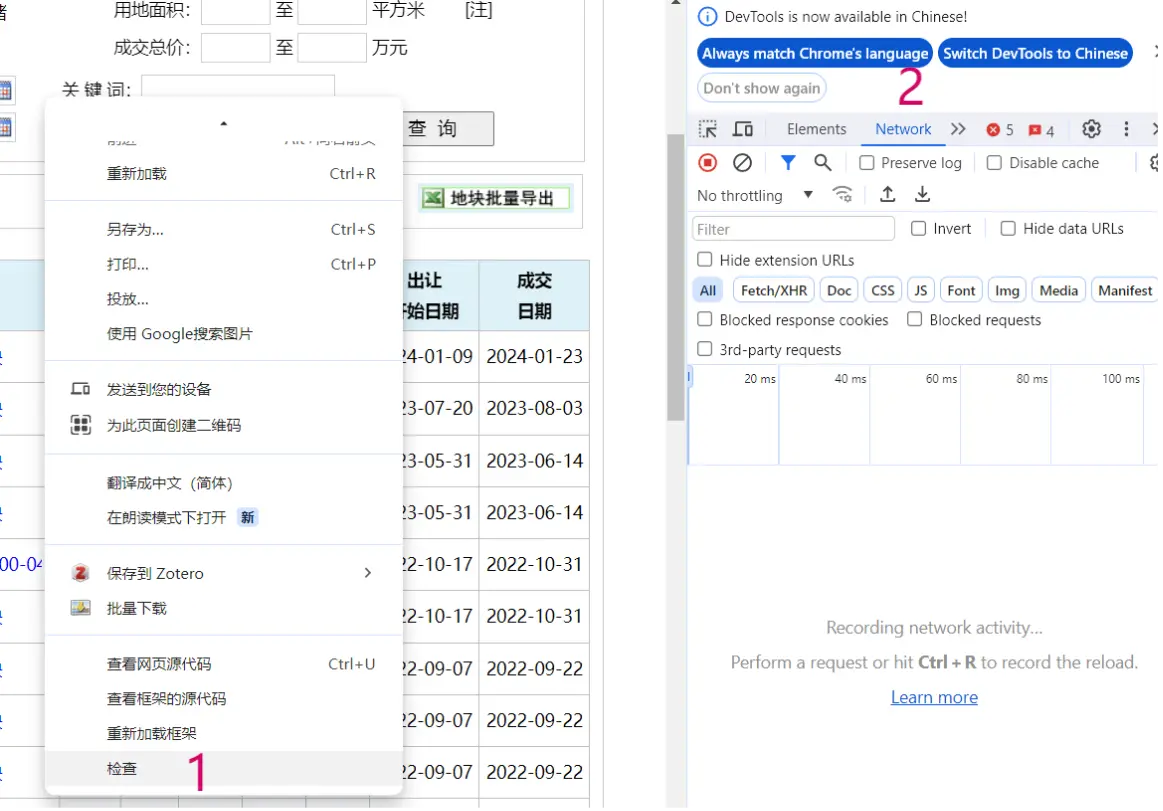
右键——检查——右侧网站查看界面——点击进入“Network”
如图
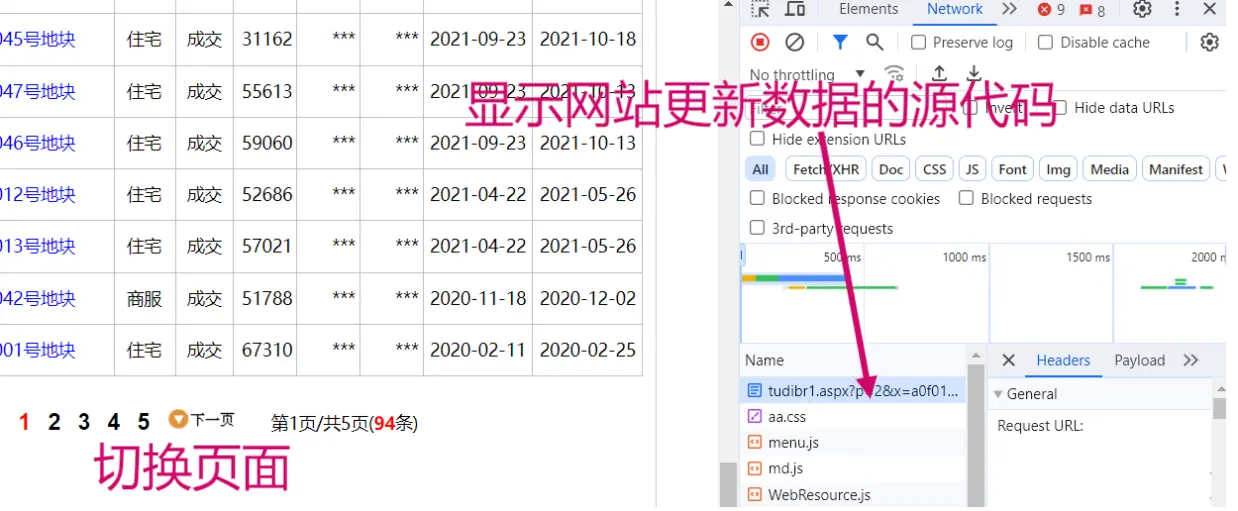
之后我们切换网站的页数,这时候网站自然会更新数据,于是我们在右侧得到对应的数据变化源代码
源代码
页面变化的是代码是 p=2 。同理,当 p=1 时,对应的是第一页的数据页面。遇上加密网站时,这个工作会很困难。
1
http://www.crei.cn/tudi/tudibr1.aspx?p=2& x=a0f010000& k=& k1=& k2=& k3=& k4=& c=& j1=0& j2=0& m1=0& m2=0
二、stata 爬虫
1、网站导入
先设定工作路径:
1
2
3
4
5
6
7
8
*-网站:国信房地产交易网:http://www. crei. cn/tudi/index . aspx
*-时间:2024年2月
*-设置工作路径
clear all
global path "F:\桌面\stata土地网爬虫"
global prcs "$path\process"
cd "$D"
set scheme s2color //绘图风格
再导入网站,使用 stata 的 copy 命令将源代码导入。
看情况使用 unicode 进行编码防止乱码。
1
2
3
4
5
6
7
8
9
10
11
12
*-[1 ]url导入
copy "http://www.crei.cn/tudi/tudibr1.aspx?p=1 &x =a0f000000 &k = &k1 = &k2 = &k3 = &k4 = &c = &j1 =0 &j2 =0 &m1 =0 &m2 =0 " "test.txt" , replace
*-Note:设置字体格式防止乱码,最后强制删除备份文件
*-Note:储存1到第200000个字符并标记为变量v
local file = "test.txt"
unicode analyze "`file'"
unicode encoding set gb18030
local file = "test.txt"
unicode translate "`file'" , transutf8
unicode erasebackups, badidea
local file = "test.txt"
infix strL v 1-200000 using "`file'" ,clear
可在 stata 里面对比网页源代码(进入对应网站后,右键查看网页源代码即可) ,可见下图:
stata
2、初步切割
keep 命令: 保留 stata 数据的哪些行split 命令: 将表格的内容按照某个符号进行切割,分为多个单元格。sxpose 命令: 数据转置重排
结合网页源代码可以发现我们要的数据都在<font face="宋体">那一行。地产信息间有<tr onmouseover=this....分割。结尾代码</table><br><center>也应删掉。切割后转置一下。
1
2
3
4
5
6
7
8
9
10
11
12
*-[2]初步数据切割
*-Note:使用 spit 函数对保留后的数据进行切割,这部分需要了解正则表达式
*-Note:观察网页源代码,保留所需数据所在的行,这里注意到数据使用了宋体
keep if index (v,`"<span id="bra1"><font face="宋体">"')
split v ,p(`"<tr onmouseover=this.style.background='#BDDFFF' onmouseout=this.style.background='#ffffff' style='background:#ffffff' ><td style='height:35px'><div class=td1 style='width:42px; text-align:center'>"' )
*-Note:额外去除下这段代码结尾的多余部分 v 211 v 212
split v 21 ,p(`" </table><br><center> "')
*</table><p align=left>
Drop v v 1 v 212 v 21
Rename v 211 v 21
Sxpose ,clear
*-Note:sxpose 数据转置重排
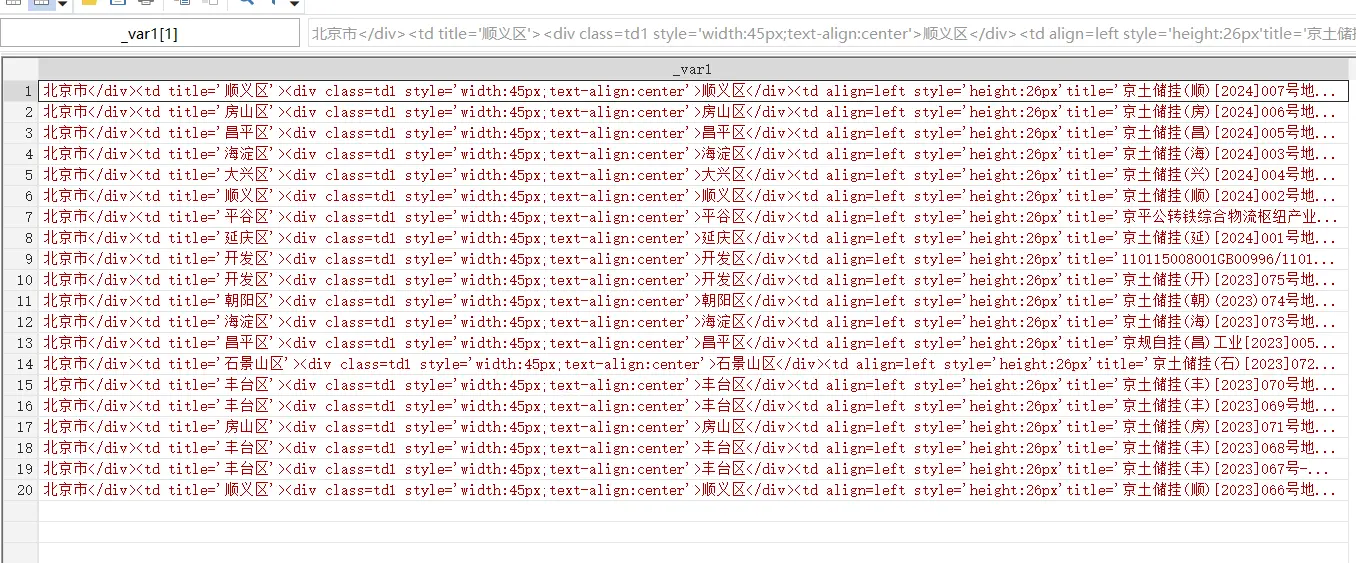
如图,到目前位置,第一页前 20 条数据已经被爬取下来并且进行了初步切割。
切割
3、进一步切割
replace: 将要切割的代码换成“滑翔闪”或者"“表示删除,然后一次性切割。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
*-[3]进一步切割数据
*-Note:把不要的中间字符换成知乎用户“滑翔闪”吧!
replace _var = subinstr (_var,`"</div><td title='"',"滑翔闪",.)
replace _var = subinstr (_var,`"'><div class=td1 style='width:45px; text-align:center'>"' ,"滑翔闪" ,.)
replace _var = subinstr (_var,`"</div><td align=left style='height: 26 px'title='"',"滑翔闪",.)
Replace _var = subinstr (_var, `"//"' ,"" , .)
replace _var = subinstr (_var, `"'><div class=td1 style='width:220px'><a href=http:www.crei.cn/tudi/tdbr.aspx?id="' ,"滑翔闪", .)
Replace _var = subinstr (_var, `" target=_blank class=tdbrw>"' ,"滑翔闪" , .)
replace _var = subinstr (_var,`"</a></div></td><td title='"', "滑翔闪",.)
replace _var = subinstr (_var,`"' ><div class=td1 style='width:40px;text-align:center' >"'," 滑翔闪",.)
replace _var = subinstr (_var,`" </div><td width=40 >"'," 滑翔闪",.)
replace _var = subinstr (_var,`" </td><td align=right>"'," 滑翔闪",.)
Replace _var = subinstr (_var,`" <td align=right title ='"' ,"滑翔闪" ,.)
replace _var = subinstr (_var,`"'> *** </td><td align=right title='"',"滑翔闪",.)
replace _var = subinstr (_var,`"' > *** </td><td nowrap>"'," 滑翔闪",.)
replace _var = subinstr (_var,`" <td nowrap>"'," 滑翔闪",.)
replace _var = subinstr (_var,`"'> *** </td>"' ,"" ,.)
*-Note:就当是为了我,对字符“滑翔闪”使用炎拳吧!
Split _var ,p(`"滑翔闪"')
Drop _var 1
4、整理保存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
*-[4 ]添加变量标签
Ren _var 11 城市
Ren _var 12 ID
Ren _var 13 ID 2
Ren _var 14 地块
Ren _var 15 代码
Ren _var 16 地块 2
Ren _var 17 类型
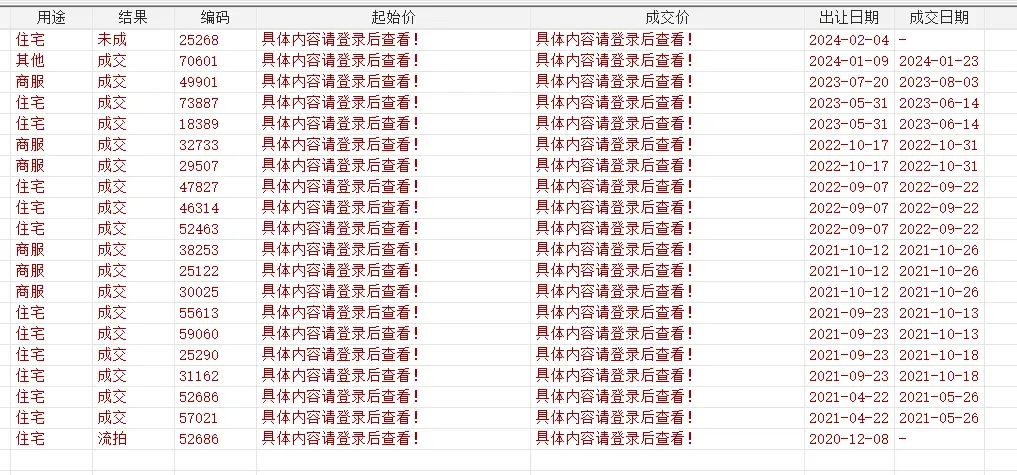
Ren _var 18 用途
Ren _var 19 结果
Ren _var 110 编码
Ren _var 111 起始价
Ren _var 112 成交价
Ren _var 113 出让日期
Ren _var 114 成交日期
*-[5 ]保存数据
Save "$path\爬虫土地. Dta" , replace
起始价和交易价部分使用的 js 进行加密,所以无法爬取,本文主要是记录爬虫原理和流程。
起始价和交易价部分使用的js进行加密,所以无法爬取,本文主要是记录爬虫原理和流程
Stata 无法使用 ip 和账号登入,所以无法爬取价格
5、多页爬取
Forvalues:stata 循环函数,我们将源代码的p=1 换成 p=`i’ 即可实现循环爬取。
注意很多时候第一页和第二页以后爬取情况不同,例如本网站中结尾页码代码不同。由于土地市场网实行了加密,所以 stata 只能爬取第一页和第二页。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
*======================================
* Part 2 爬取多页 (共 133 页)
* 数据来源:国信房地产交易网-土地市场数据
*======================================
Forvalues i = 2/133{ //利用循环爬取 2-133 页并与第 1 页合并
Di `i'
Clear
*-[1]url 导入
qui copy "http://www.crei.cn/tudi/tudibr1.aspx?p=`i'&x=a 00000000&k=&k 1=&k 2=&k 3=&k 4=&c=&j 1=0&j 2=0&m 1=0&m 2=0" "test`i'. Txt", replace
*-Note:设置字体格式防止乱码,最后强制删除备份文件
*-Note:储存 1 到第 200000 个字符并标记为变量 v
Qui local file`i' = "test`i'. Txt"
Qui unicode analyze "`file`i''"
Qui unicode encoding set gb 18030
Qui unicode translate "`file`i''", transutf 8
Qui unicode erasebackups, badidea
Qui infix strL v 1-200000 using "test`i'. Txt", clear
*-[2]初步数据切割
*-Note:使用 spit 函数对保留后的数据进行切割,这部分需要了解正则表达式
*-Note:观察网页源代码,保留所需数据所在的行,这里注意到数据使用了宋体
qui keep if index (v,`"<span id="bra1"><font face="宋体">"')
qui split v ,p(`"<tr onmouseover=this.style.background='#BDDFFF' onmouseout=this.style.background='#ffffff' style='background:#ffffff' ><td style='height:35px'><div class=td1 style='width:42px; text-align:center'>"' )
*-Note:额外去除下这段代码结尾的多余部分 v 211 v 212
qui split v 21 ,p(`"</table><p align=left>"')
Qui drop v v 1 v 21
Qui rename v 211 v 21 ylyih
Qui sxpose ,clear
*-Note:sxpose 数据转置重排
*-[3]进一步切割数据
*-Note:把不要的中间字符换成知乎用户"滑翔闪"吧!
qui replace _var = subinstr (_var,`"</div><td title='"',"滑翔闪",.)
qui replace _var = subinstr (_var,`"'><div class=td1 style='width:45px; text-align:center'>"' ,"滑翔闪" ,.)
qui replace _var = subinstr (_var,`"</div><td align=left style='height: 26 px'title='"',"滑翔闪",.)
Qui replace _var = subinstr (_var, `"//"' ,"" , .)
qui replace _var = subinstr (_var, `"'><div class=td1 style='width:220px'><a href=http:www.crei.cn/tudi/tdbr.aspx?id="' ,"滑翔闪", .)
Qui replace _var = subinstr (_var, `" target=_blank class=tdbrw>"' ,"滑翔闪" , .)
qui replace _var = subinstr (_var,`"</a></div></td><td title='"', "滑翔闪",.)
qui replace _var = subinstr (_var,`"' ><div class=td1 style='width:40px;text-align:center' >"'," 滑翔闪",.)
qui replace _var = subinstr (_var,`" </div><td width=40 >"'," 滑翔闪",.)
qui replace _var = subinstr (_var,`" </td><td align=right>"'," 滑翔闪",.)
Qui replace _var = subinstr (_var,`" <td align=right title ='"' ,"滑翔闪" ,.)
qui replace _var = subinstr (_var,`"'> *** </td><td align=right title='"',"滑翔闪",.)
qui replace _var = subinstr (_var,`"' > *** </td><td nowrap>"'," 滑翔闪",.)
qui replace _var = subinstr (_var,`" <td nowrap>"'," 滑翔闪",.)
qui replace _var = subinstr (_var,`"'> *** </td>"' ,"" ,.)
*-Note:就当是为了我,对字符"滑翔闪" 使用炎拳吧!
Qui split _var ,p(`"滑翔闪"')
Qui drop _var 1
*-[4]添加变量标签
Qui ren _var 11 城市
Qui ren _var 12 ID
Qui ren _var 13 ID 2
Qui ren _var 14 地块
Qui ren _var 15 代码
Qui ren _var 16 地块 2
Qui ren _var 17 类型
Qui ren _var 18 用途
Qui ren _var 19 结果
Qui ren _var 110 编码
Qui ren _var 111 起始价
Qui ren _var 112 成交价
Qui ren _var 113 出让日期
Qui ren _var 114 成交日期
*-[5]保存数据
Qui append using "$path\爬虫土地. Dta"
Qui save "$path\爬虫土地. Dta", replace
}
三、附件和参考资料:
1、参考资料
百度网盘
进阶就是了解 R、python、CURL 的爬虫命令,流程和原理都类似。Python 好处是多线并进,同时有灵活的轮子可以使用。
本文爬取的土地交易网由于使用了 js 加密无法爬取,但是他们没有关掉旧版源码入口,于是旧版依旧毫无防备 ——可以参考下面这篇文章的代码爬取旧源码的数据。
1
http://www.crei.cn/tudi/lawbr.aspx?p=1& a=1& jyzt=& crfs=& tdlx=& rq1=& rq2=& rq3=& rq4=& key=& ren=& cs=%C8%AB%B2%BF
教你用 Stata 抓取全国土地交易数据
Stata:批量获取经纬度数据-空间计量
Stata爬虫:爬取地区宏观数据
正则表达式
2、一些论文
工业用地价格与企业产能利用率: 爬取土地数据,发现工业土地交易聚集和产能过剩的关系
最低工资与异质性人力资本需求:基于招聘网站数据的研究: 爬取招聘信息,研究劳动力需求侧特征
工业机器人应用与劳动关系:基于司法诉讼的实证研究 ——爬取法律文书,研究机器人应用与劳工纠纷