
R 语言基础 1:界面介绍与语法结构

记录下 R 语言学习过程。个人感觉作为只跑回归的经济学学习者, Stata 完全够用了1,不足的部分一般都用 Python 的轮子,即便是算 DSGE 用的也是 Matlab 的 Dynare 插件。对于计量经济学来说 R 语言回归表格样式和导出都不太友好,比较劝退。
虽然目前对我没啥用,但学习原因有三:
- 支持开源2,所以想浅浅学习下 R 语言;
- 个人目前在用 Rstudio 写博客文件;
- 看了下快手、字节、腾讯、百度等大厂的分析师类型实习招聘,一般都是要求用 R 语言处理 SQL 数据库。
教程推荐
个人推荐
-
论坛:统计之都
-
在线即可运行 R 语言代码:菜鸟编程
-
国外版本的菜鸟编程:w3schools
-
推荐博客网站
-
强烈推荐:《数据科学中的 R 语言》王敏杰老师写的电子讲义
-
强烈推荐:《Introduction to Econometrics with R》教材互动感极强!
-
由于 R 语言可以生成网站,国内外很多老师都把自己的课写成了在线电子讲义。
写博客是积累,写讲义是用心,这样的老师越来越多,中国以后也会越来越好吧。
可以参见 R 语言电子图书大集合 bookdown
大部分老师的电子讲义都会推荐的一本
-
R 语言项目: mounment 的 github仓库
-
国内教程3推荐:
个人喜欢快速入门且关键处足够细致的教程,本文笔记也主要来源于该视频:
看完视频语法介绍之后建议直接开看电子讲义了。
后面视频讲复杂了,没必要。
电子讲义教材
表格出处:【精心整理】2022年各专业领域全网最新最顶级的R语言新书
| 专业领域 | TOP-R 书籍或资源 | 作者 | 书籍地址 |
|---|---|---|---|
| R 编程 | R 语言编程:基于 tidyverse | 张敬信 | https://zhuanlan.zhihu.com/p/467134727 |
| R 编程 | R 语言教程 | 李东风 | https://www.math.pku.edu.cn/teachers/lidf/docs/Rbook/html/_Rbook/index.html |
| R 编程 | Advanced R | Hadley | https://adv-r.hadley.nz/ |
| R 编程 | Efficient R programming | Colin Gillespie, Robin Lovelace | https://csgillespie.github.io/efficientR/ |
| R 可视化 | ggplot 2: Elegant Graphics for Data Analysis | Hadley | https://ggplot2-book.org/ |
| R 可视化 | Interactive web-based data visualization with R, plotly, and shiny | Carson Sievert | https://plotly-r.com/ |
| R 可视化 | 现代统计图形 | 赵鹏,谢益辉,黄湘云 | https://bookdown.org/xiangyun/msg/ |
| R 可视化 | rstudio:: conf 2020 data visualization workshop | Kieran Healy | https://github.com/rstudio-conf-2020/dataviz |
| R 可视化 | R Graphics Cookbook, 2 nd edition | Winston Chang | https://r-graphics.org/ |
| R 可视化 | R 语言数据可视化之美 | 张杰 | https://gitee.com/easyshu/Beautiful-Visualization-with-R |
| 文档沟通 | R Markdown Cookbook | 谢益辉 | https://bookdown.org/yihui/rmarkdown-cookbook/ |
| 文档沟通 | R Markdown: The Definitive Guide | 谢益辉 | https://bookdown.org/yihui/rmarkdown/ |
| 文档沟通 | bookdown: Authoring Books and Technical Documents with R Markdown | 谢益辉 | https://bookdown.org/yihui/bookdown/ |
| 开发 R 包 | R Packages | Hadley | https://r-pkgs.org/ |
| Shiny | Mastering Shiny | Hadley | https://mastering-shiny.org/ |
| Shiny | Engineering Production-Grade Shiny Apps | Colin Fay, Sébastien Rochette, Vincent Guyader and Cervan Girard | https://engineering-shiny.org/ |
| Shiny | JavaScript for R | John Coene | https://javascript-for-r.com/ |
| 应用统计 | Statistical Inference via Data Science | Chester Ismay and Albert Y. Kim | https://moderndive.com/ |
| 应用统计 | Introduction to Modern Statistics | Mine Çetinkaya-Rundel | https://openintro-ims.netlify.app/ |
| 应用统计 | 现代应用统计与 R 语言 | 黄湘云 | https://bookdown.org/xiangyun/masr/ |
| 应用统计 | 统计学与 R 语言 (课件) | 张敬信 | tidy-R 语言 2 群(222427909)群文件 |
| 实验设计 | The Grammar of Experimental Designs | Emi Tanaka | https://emitanaka.org/edibble-book/ |
| 贝叶斯 | Doing Bayesian Data Analysis in brms and the tidyverse | A Solomon Kurz | https://bookdown.org/content/3686/ |
| 贝叶斯 | Introduction to Bayesian Econometrics: A GUIded tour using R | Andrés Ramírez-Hassan | https://bookdown.org/aramir21/IntroductionBayesianEconometricsGuidedTour/ |
| 贝叶斯 | An Introduction to Bayesian Reasoning and Methods | Kevin Ross | https://bookdown.org/kevin_davisross/bayesian-reasoning-and-methods/ |
| 贝叶斯 | Statistical rethinking with brms, ggplot 2, and the tidyverse: Second edition | A Solomon Kurz | https://bookdown.org/content/70a06054-8138-4d90-aaa0-895f57aab1b4/ |
| 数据科学 | R for Data Science | Hadley | https://r4ds.had.co.nz/ |
| 数据科学 | Tidyverse Skills for Data Science in R | Carrie Wright, Shannon Ellis, Stephanie Hicks, and Roger D. Peng | https://leanpub.com/tidyverseskillsdatascience |
| 数据科学 | 数据科学中的 R 语言 | 王敏杰 | https://bookdown.org/wangminjie/R4DS/ |
| 数据科学 | Data Science Live Book | Pablo Casas | https://livebook.datascienceheroes.com/ |
| 数据科学 | R 语言实战(第三版) | Rob Kabacoff | https://livebook.manning.com/book/r-in-action-third-edition/ |
| 数据科学 | Modern Data Science with R (2 nd) | Benjamin S. Baumer, Daniel T. Kaplan, and Nicholas J. Horton | https://mdsr-book.github.io/mdsr2e/ |
| 机器学习 | mlr 3 book | 官方出品 | https://mlr3book.mlr-org.com/ |
| 机器学习 | Tidy Modeling with R | MAX KUHN AND JULIASILGE | https://www.tmwr.org/index.html |
| 机器学习 | Hands-On Machine Learning with R | Bradley Boehmke & Brandon Greenwell | https://bradleyboehmke.github.io/HOML/ |
| 机器学习 | Feature Engineering and Selection: A Practical Approach for Predictive Models | Max Kuhn and Kjell Johnson | http://www.feat.engineering/ |
| 机器学习 | An Introduction to Statistical Learning with R | Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani | https://trevorhastie.github.io/ISLR/ |
| 机器学习 | R 机器学习:基于 mlr 3 verse (课件) | 张敬信 | tidy-R 语言 2 群(222427909)群文件 |
| 深度学习 | Deep Learning with R, Second Edition | François Chollet with Tomasz Kalinowski and J. J. Allaire | https://www.manning.com/books/deep-learning-with-r-second-edition |
| 文本挖掘 | Supervised Machine Learning for Text Analysis in R | EMIL HVITFELDT AND JULIA SILGE | https://smltar.com/ |
| 文本挖掘 | QUANTEDA TUTORIALS | Kohei Watanabe and Stefan Müller | https://tutorials.quanteda.io/ |
| 文本挖掘 | Text Analysis Tutorials | LADAL | https://slcladal.github.io/index.html |
| 计量 | Introduction to Econometrics with R | Christoph Hanck, Martin Arnold, Alexander Gerber, and Martin Schmelzer | https://www.econometrics-with-r.org/ |
| 计量 | Beyond Multiple Linear Regression: Applied Generalized Linear Models and Multilevel Models in R | Paul Roback and Julie Legler | https://bookdown.org/roback/bookdown-BeyondMLR/ |
| 计量 | Mixed Models with R Getting started with random effects | Michael Clark | https://m-clark.github.io/mixed-models-with-R/ |
| 时间序列 | Forecasting: Principles and Practice (3 rd ed) | RobJHyndman | https://otexts.com/fpp3/ |
| 时间序列 | 金融时间序列分析讲义 | 李东风 | https://www.math.pku.edu.cn/teachers/lidf/course/fts/ftsnotes/html/_ftsnotes/index.html |
| 金融 | Tidy Finance with R | Christoph Scheuch, Stefan Voigt, and Patrick Weiss | https://tidy-finance.org/ |
| 空间数据分析 | Geocomputation with R | Robin Lovelace, Jakub Nowosad, Jannes Muenchow | https://geocompr.robinlovelace.net |
| 空间数据分析 | Spatial Data Science with applications in R | Edzer Pebesma, Roger Bivand | https://keen-swartz-3146c4.netlify.app/ |
| 空间数据分析 | NHH ECS 530 2021 course: Spatial data analysis (with R) | Roger Bivand | https://rsbivand.github.io/ECS530_h21/ |
| 因果推断 | The Effect: An Introduction to Research Design and Causality | Nick Huntington-Klein | https://theeffectbook.net/ |
| 因果推断 | Causal Inference: The Mixtape | Scott Cunningham | https://mixtape.scunning.com/index.html |
| 社会科学 | Data Analytics for the Social Sciences Applications in R | G. David Garson | |
| 社会科学 | A Business Analyst’s Introduction to Business Analytics | Adam Fleischhacker | https://www.causact.com/ |
| 社会科学 | Computing for the Social Sciences | Benjamin Soltoff | https://cfss.uchicago.edu/notes/intro-to-course/ |
| 网络分析 | Methods for Network Analysis | Mark Hoffman | https://bookdown.org/markhoff/social_network_analysis/ |
| 网络分析 | Handbook of Graphs and Networks in People Analytics: With Examples in R and Python | Keith McNulty | https://ona-book.org/ |
| 网络建模 | workshop 2020_Network Modeling for Epidemics | http://statnet.org | https://statnet.org/nme/d1.html |
| 模型计算 | Model Estimation by Example Demonstrations with R | Michael Clark | https://m-clark.github.io/models-by-example/ |
| 模型计算 | Computer-age Calculus with R | Daniel Kaplan | https://dtkaplan.github.io/RforCalculus/ |
| 大数据 | Mastering Spark with R | Javier Luraschi, Kevin Kuo, Edgar Ruiz | https://therinspark.com/ |
| 元分析 | Doing Meta-Analysis in R: A Hands-on Guide | Harrer, M., Cuijpers, P., Furukawa, T.A., & Ebert, D.D | https://bookdown.org/mathiasHarrer/Doing_Meta_Analysis_in_R/ |
| 生存分析 | Applied Survival Analysis Using R | Dirk F. Moore |
R 语言下载
个人环境:
R 语言(本体)+ Rstuido(IDE)+ Rtools(插件包管理,win 系统限定)
下载很简单,都是点点点一路 yes 即可。
R 语言本体:https://cran.r-project.org/
Rstudio 桌面软件:https://posit.co/download/rstudio-desktop/
R 语言本体自带中文支持,但是 Rstudio 没有中文支持,有汉化github项目,但是不好用,也不推荐去用,产生闪退、不兼容 bug 就麻烦了。
R studio 界面与准备
界面介绍
菜单目录进入页面设置:tools - global option - Pane Layout
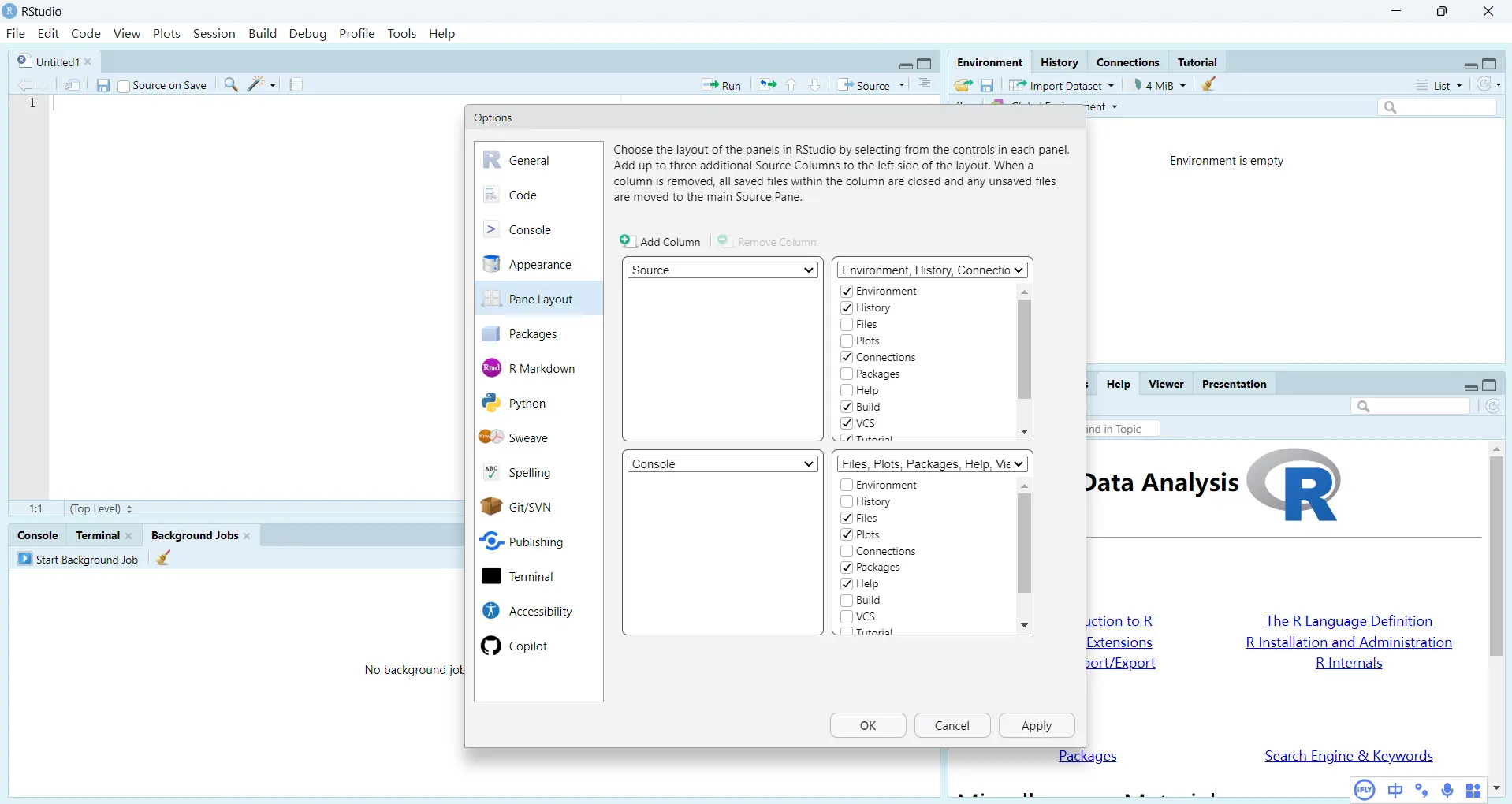
此时,
左上角的 source(新建 R script 项目后)页面代表代码编写部分。
左下角的 console 代表结果展示部分。
右侧上下部分就是自定义栏目,例如 history 代表代码运行历史;environment 代表变量环境,可以在里面通过 import Dataset 导入 stata、excel 等数据;file 代表运行环境的电脑目录。
包的管理与下载
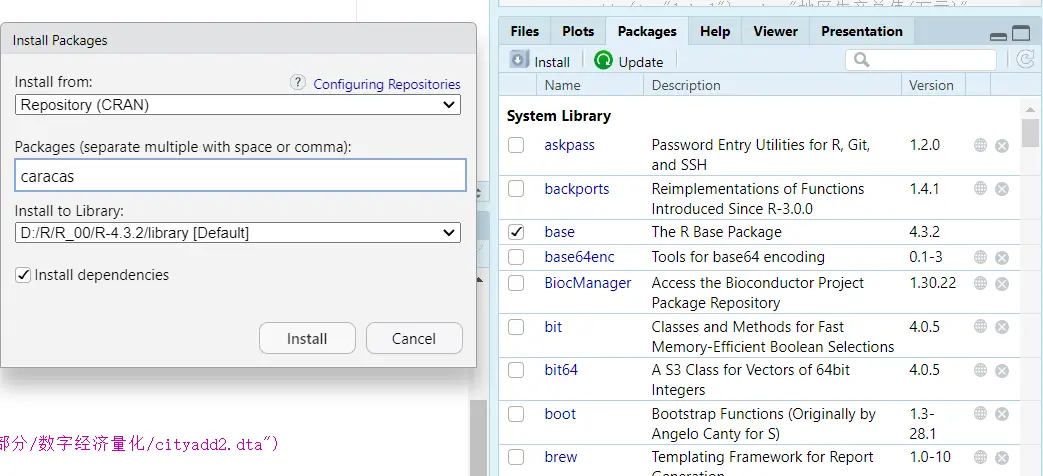
手动安装
持续使用 R 语言很考验电脑内存,因为要不断地下载包。
win 系统上使用 R 语言,一般使用 Rtools 管理。最新版的 R 语言应该自带这个工具包,没有的话去官网安装即可,安装 .exe 的软件即可。
在包含 file 的部分,其中包含 Packages 部分,点击其中的 install 即可安装。
命令安装、加载
R 语言作为统计学家的语言,个人感觉本体程序语法不太优雅,但开源加载适合的包后就无比痛快了。
例如我们要安装 car 这个包,可以使用以下命令
|
|
由于包与包之前可能存在同样的函数名,在调用两个包产生冲突时,后面的包的同名函数将覆盖前一个包
设置工作目录
|
|
载入数据
Stata 一个页面只能加载一个数据库,但是 R 语言可以加载多个。
|
|
语法知识
数据类型
| 类型 | 示例或描述 | 类型 |
|---|---|---|
| 数值 | 2333 233.3 | numeric |
| 字符 | ‘下一个就是你了’ “JOJO” “2333” | character |
| 逻辑 | TRUE T FALSE F | logical |
| 缺失值 | 例如强行把文字转化为数字会转换失败 | NA |
| 空白值 | NULL | |
| 非数 | Not a Number 非数值 | NaN |
| 无穷大 | “Infinite”的缩写 | Inf |
|
|
数据结构
赋值与向量
常规介绍顺序:赋值、索引、切片
|
|
矩阵
矩阵相关就是向量命令的叠加
|
|
列表
不同于向量和矩阵,列表可以是不同数据类型和结构的组合
|
|
数据框
特殊的列表,也就是我们常常处理的面板数据、时间序列,使用 Data frame 构建。
|
|
基本运算和函数
基本运算
|
|
向量函数运算
|
|
数据框和矩阵运算
数据框
|
|
矩阵
|
|
字符函数
|
|
分布函数
|
|
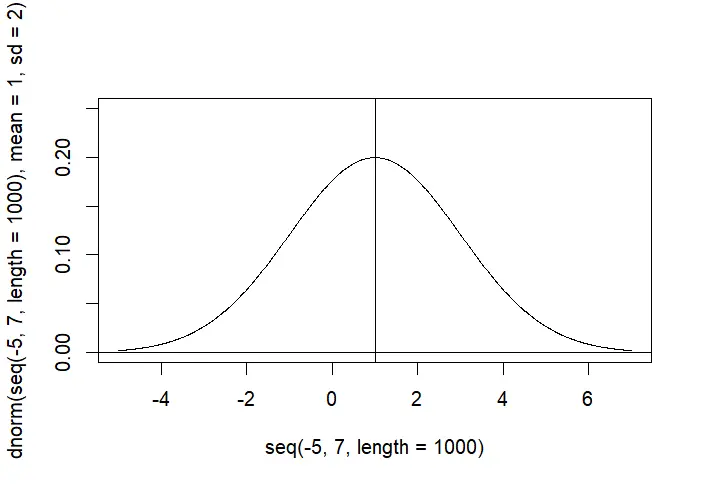
基本语法
循环
stata 简化为了 local、global 结合 foreach 进行变量循环,缺点是不便于行间的加减。
|
|
条件
If else 老生常谈了,这里不再过多举例
|
|
函数构建
|
|
数据整理
tidyverse 包的官网:https://www.tidyverse.org/
测试数据集可以在这里下载:https://moxingjiqi.shinyapps.io/dataset/
tidyverse 包的 haven 支持读取 spss、stata、SAS
文件路径最好别包括中文名,不然容易导入乱码失败
导入和导出
表格出处:《数据科学中的 R 语言》
| 格式 | 命令 |
|---|---|
| .txt | read.table() |
| .csv | read.csv() and readr::read_csv() |
| .xls and .xlsx | readxl::read_excel() and openxlsx::read.xlsx() |
| .sav (SPSS files) | haven::read_sav() and foreign::read.spss() |
| .Rdata or rda | load() |
| .rds | readRDS() and readr::read_rds() |
| .dta | haven::read_dta() and haven::read_stata() |
| .sas 7 bdat (SAS files) | haven::read_sas() |
| Internet | download.file() |
|
|