
"哥白尼时刻"与学术品味

问题往往一体两面,概念在对比中确立边界。当我们讨论 AI 能干什么时,我们其实在重新讨论:人在研究中的独特性究竟在哪里。
在学术界,一种越来越常见的说法是:当 AI 成为科研助手后,科研品味会变得更重要。但我一直对使用品味这个词感到抵触。
- 一方面,这个词太模糊,和做研究时“把事情说清楚、说明白、说通俗”的要求背道而驰;
- 另一方面,这种模糊地带虽然能提供某种灵活的处事经验,却也很容易异化为幸存者偏差,身份政治式的居高临下。
如果一定要谈论品味,我们就必须把这个词语说清楚,而不是刻意模糊、回避,绕过来绕过去。
最近,陶哲轩在与油管博主 Dwarkesh Patel 的访谈里,给了我新的灵感:也许我们平时说的“科研品味”,其实混在了两个并不相同的问题层次里。
- 宏观层面:真理究竟是如何被发现的?
- 微观层面:什么样的理论会被优先选择、传播和投资?
宏观上,科研品味并不构成真理的来源;微观上,科研品味依然存在,但更像一种生存机制与共同体文化。
- 油管原视频:《Terence Tao – How the world’s top mathematician uses AI》
- 国内各种文字版转载可参考:量子位、网易、51CTO。
回顾“哥白尼时刻”
严格地说,文中的“哥白尼时刻”,更接近于开普勒真正修正天体运动规律的时刻。
哥白尼提出日心说,但仍然坚持行星做完美的圆周运动。
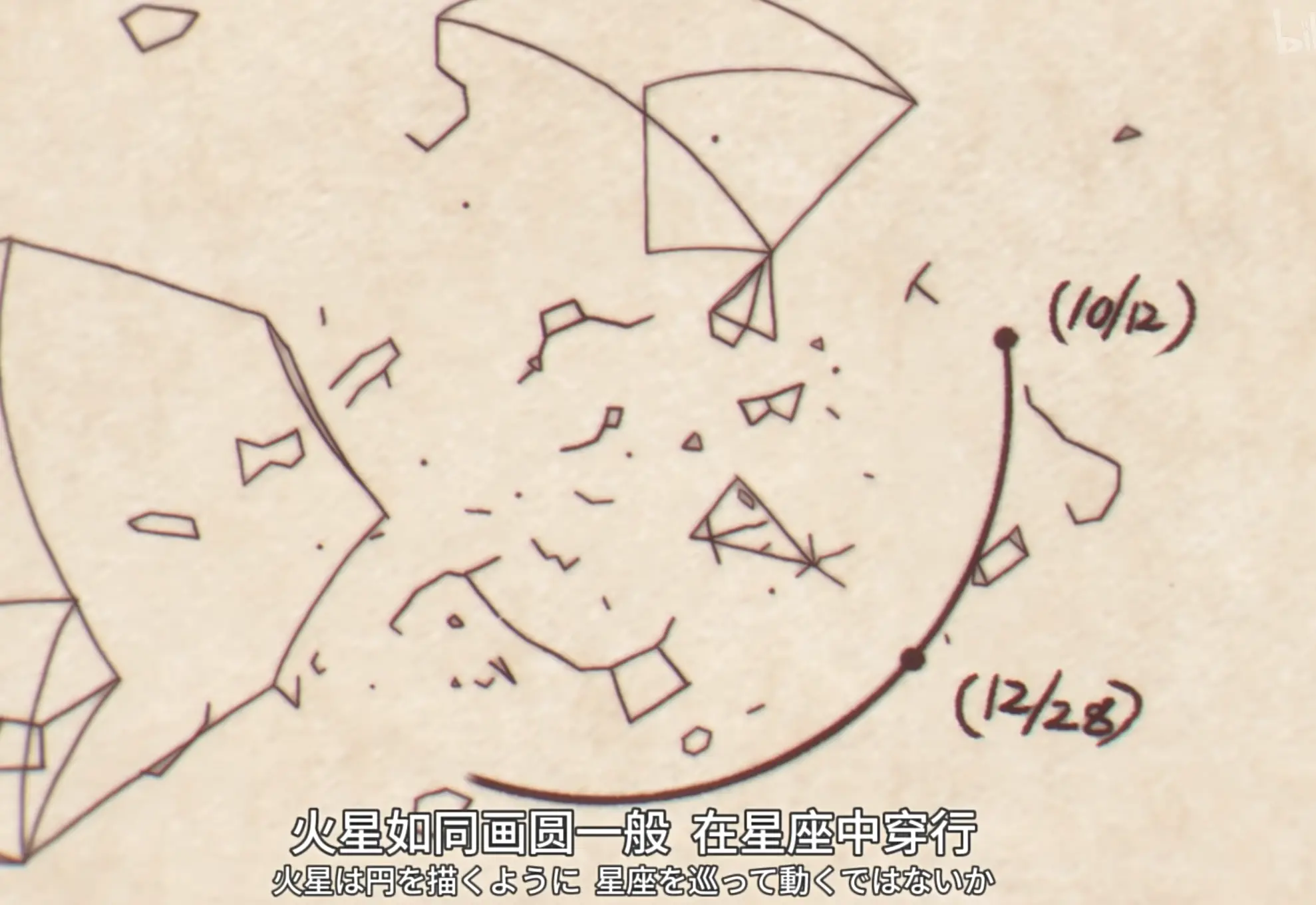
开普勒一度相信行星轨道应当符合某种高度和谐的几何结构,甚至与柏拉图立体有关。然而他缺乏高质量的观测数据集,因此开普勒从第谷·布拉赫那里获取了高质量的观测数据集。
宇宙行行星并不是按照圆或者正多边体规则来运行的。开普勒多年来进行了各种尝试,例如挪动圆的位置,但始终无法满足。最终开普勒通过数据驱动的方式,发现了椭圆可能才是正确答案。
用更现代的实证过程来说,这个过程其实是这样的:
- 高质量数据:第谷的长期观测记录;
- 模型假设:圆形轨道、几何和谐等先验假设;
- 残差分析:模型无法解释火星轨道中的关键偏差;
- 反复修正:不断移动圆、修改参数、尝试不同结构;
- 放弃旧假设:承认“圆”本身可能就是错的;
- 抽象出新规律:椭圆轨道与更一般的行星运动定律。
科学史往往容易放大那个“发现瞬间”,却低估了发现之前漫长的失败、试错与数据积累。就这个意义上说,宏观上的求真过程,从来都不只是“品味好的人一眼看穿本质”,而是 拥有更好的数据、更长的试错、更敢于删除旧假设的人,最终逼近了真相。
品味与试错成本?
学术界常说科研品味、科研直觉,在作用上无非为了一个目的——降低试错成本。
每天科学家们有无限的理论假设和有限的检验精力,因此需要同行评议制度筛选成更加可靠的科学理论。但是在数据驱动和 ai 发展的环境下,验证成本正在无限趋于 0。因此,目前的研究优势其实变成了:
- 谁拥有更高质量的数据;
- 谁能更快暴露旧模型的漏洞;
- 谁愿意承认自己珍视的假设其实是错的;
- 谁能在大量失败中保留那一点粗糙但正确的东西。
这本质上很容易联想到著名的社会科学问题—— 为什么工业革命没有发生在中国 (亚洲) ?这个问题在不同学科,不同时期有着不同的名字,李约瑟之问、韦伯之问、大分流、钱学森之问………
林毅夫的经典回答 是:科学的本质是提高生产力。中国劳动力丰富,资本稀缺,欧洲则相反。因此欧洲有科学激励动机,中国则发展出了科举。中国早期的发展源于人口密度的经验总结。而工业革命则需要一个激励精英到科学事业中的制度环境。
一个关键的引申问题是—— 推动工业革命的主体到底是人民还是精英 ? 时间上当然容易看作辩证唯物的时代浪潮,空间上的不平等却暗示着没有这么简单。如果我们假设科学发展存在瓶颈期,是否这才是 ai 与工业革命的理论依据?试错成本和人口素质的倒 U 形关系:
当试错成本很低时,数量与广泛尝试更重要;当试错成本很高时,精英筛选与高度训练更重要;而当 AI 开始显著降低部分认知试错成本时,原本依赖少数人“品味”来维持的筛选结构,可能就会发生松动。宏观层面上真正变化的,不是“真理开始依赖品味”,而是:我们逼近真理所需的试错组织方式,正在发生变化。
品味与选择机制
遗憾的是,科学家并不活在宏观历史里的,科学家活在今天、活在截稿日期之前、活在基金申请和同行评议之中1。
刘慈欣在短篇科幻小说《诗云》里写过一个很漂亮的比喻:高等文明可以穷举所有汉字组合,却仍然不知道哪一首诗会在未来真正超越李白。问题不只是“能不能生成”,而是“该相信哪一个”。
理论世界也一样。我们往往很难在当下就知道,哪个理论会在未来变得重要,因为理论的价值从来不只取决于它在此刻是否优雅、成熟、完整,也取决于它能否在未来被证明更有解释力。
经济思想史里有很多类似例子。很多人当年并不能接受奥古斯丁·古诺(Augustin Cournot)在《财富理论的数学原理》中使用数学来表达价格—需求关系;拉姆齐(Ramsey)在索洛增长模型之前就已触及储蓄率内生化的问题,但其重要性也是在后来的理论框架中才真正显现出来。“品味”在这里的含义更像是:
- 对当下问题的敏感;
- 对一个理论未来解释力的朦胧预判;
- 对“粗糙的正确”与“精致的错误”之间的忍耐能力。
粗糙的正确与精致的错误
陶哲轩有一段话非常精彩:
科学总是在不断推进的。当你只得到了部分解答时,它看起来可能不如一个虽然错误但已经被完善到足以回答所有问题的理论。牛顿理论里有很多谜团,这些问题直到几个世纪后,才通过一种概念上完全不同的方法被解决。进步的实现往往不是通过增加更多理论,而是通过删除你头脑中的某些假设。
这段话其实正好能解释,为什么“品味”在微观上会被不断提起。
因为现实中的研究者,经常同时面对两类东西:
- 非常成熟的错误理论;
- 非常粗糙的正确理论。
如果从历史终局看,时间可能最终会替正确理论作证;但如果从当下的职业生涯、学科分工和资源配置看,研究者必须在证据尚不完备时做出选择。于是,“品味”就不是一种神圣能力,而是一种现实中的下注能力。
品味与叙事
如果只看到“数据越来越多、模型越来越强”,人很容易产生一种错觉:既然机器能更快生成假设、检验模式,那么理论竞争会不会最终退化为纯粹的数据竞赛?
陶哲轩对此的回答恰恰是否定的:
阐释的艺术、论证的组织、构建叙事,这些也是科学的重要组成部分。数据当然有帮助,但人们需要被说服,否则他们不会去推进这个方向。他们需要做出初始投资来学习你的理论并真正去探索它。
这段话点出了微观层面的另一个事实:科学不只是发现过程,也是组织过程。
数据不会自动说服人。一个理论即便在某种意义上更接近真理,也仍然需要被解释、被传播、被学习、被纳入课程、被写进论文、被投入新的研究资源。即便在实证经济学中,p 值也只是诸多必要条件中的一个检验参数2;我们真正需要说服别人的,是这些必要条件的组合为什么足够可信。参见《经济学的修辞》和《实证经济学:符合直觉≠显而易见》。
请不要神化品味这个词,微观层面的“品味”往往带着明显的共同体色彩。它不仅是个人判断,也是一种学科内部的俱乐部文化:什么问题值得做,什么证据算关键,什么表达算严肃,什么假设被认为“自然”,这些都不是纯粹个人决定的。
用更极端一点的例子说:对于劳动经济学家,性别可能是分析社会结构时的基本维度;但某些研究 LGBT 议题的社会学家,未必会接受同样的问题设定。新结构经济学家可能把禀赋视为首要约束,制度经济学家则会强烈反对。这里的分歧,不完全是谁“更真”,而是谁所在的共同体优先关注什么、如何组织问题、如何分配注意力。
所以,微观上“科研品味”确实存在,但它更像一种俱乐部词汇3。
AI 与问题
宏观上,品味其实是个虚无的词汇。错误理论可以非常成熟,正确理论可以非常粗糙;决定长期胜负的,仍然是数据、解释力、试错与时间。
微观上,品味又确实很重要。因为研究者不可能等到“历史审判结束”再决定今天该读什么、做什么、投什么、教什么。有限资源迫使每个共同体都要形成自己的预筛选规则,而“品味”常常就是这种规则的日常名称。
也因此,AI 带来的变化,不应简单说成“科研品味更重要了”或“科研品味不重要了”。更准确的说法也许是:
- 技术性试错成本正在下降。AI 可以帮助生成备选思路、搜索文献、检查推导、进一步压缩低层次劳动;
- 社会性验证成本并没有消失。数据质量、理论可解释性、同行说服、训练门槛、制度激励,依然是 ai 不能达到的地方;
- 品味的载体正在变化。过去它更多体现为少数专家的个人判断;现在它也越来越嵌入数据集、引用网络、模型权重、推荐系统与共同体反馈之中。
科研品味不是通向真理的捷径。宏观上,真理未必由品味决定;微观上,品味仍是有限资源下的生存策略。AI 改变的,不是求真本身,而是真理被发现、筛选、传播和投资的方式。
也许,这才是更接近今天处境的“哥白尼时刻”。