
Econometrics: Is the log(y+1) transformation reliable?

Is the log(y+1) transformation reliable?
Abstract
| Title: Logs with Zeros? Some Problems and Solutions |
|---|
| Authors: Jiafeng Chen; Jonathan Roth |
| Journal: The Quarterly Journal of Economics (2024/3/30) |
| DOI: 10.1093/qje/qjad054 |
| Translated abstract: When studying an outcome variable $Y$ that can equal 0 (for example, earnings), many researchers estimate the average treatment effect (ATE) after applying a transformation that behaves like $\log(Y)$ when $Y$ is large and is defined at zero by using $\log(1+Y)$. Our paper shows that the average treatment effect under this kind of log-like transformation should not be interpreted as a percentage effect, because the estimate depends on the units in which the outcome is measured. In fact, we show that one can obtain treatment effects of arbitrary magnitude simply by changing the units of $Y$ before applying the transformation. This happens because, for observations whose outcome moves from zero to nonzero, the individual-level percentage effect is not well defined, and the units of the outcome implicitly determine how much weight the transformed ATE places on the extensive margin. More generally, we uncover an “impossibility triangle”: when the outcome variable can equal zero, one cannot simultaneously have an estimand that is an average treatment effect, is invariant to the units of $Y$, and is point identified. We discuss several alternative approaches that may be reasonable in settings with both intensive and extensive margins, including (1) estimating average treatment effects in levels and then expressing them in percentage terms afterward (for example, with Poisson regression), (2) explicitly calibrating the weight placed on the intensive and extensive margins, and (3) estimating intensive-margin and extensive-margin treatment effects separately (for example, with Lee bounds). We illustrate these methods in three empirical applications. |
The short version
This post asks whether log transformations with zeros, such as $log(1+y)$ and $arcsinh(y)=\sqrt{1+y^2}+y$, are actually reliable.
A code example
The output below shows that when the data contain zeros, changing the units of $y$ before taking logs can change the statistical significance of the regression.
|
|
Explanation
How we usually interpret log transformations
The standard view is that, once you take logs, the coefficient has a percentage interpretation.
After taking logs, we usually read the coefficient as a percentage change. For example, with lnGDP, the coefficient in a regression is often read as the percentage change in GDP. If the model is reg lny lnx, then the coefficient is an elasticity. See What taking logs means.
For the regression below, $$ \ln y_n=\alpha+\beta x_n +\varepsilon $$ the coefficient has the following economic meaning: $$ \begin{align} \beta & = \frac{\ln Y_{n+1}-\ln Y_{n}}{X_{n+1}-X_{n}}\ &=\frac{\ln \frac{Y_{n+1}}{Y_{n}}}{X_{n+1}-X_{n}}= \frac{\ln (1+\frac{Y_{n+1}-Y_{n}}{Y_{n}})}{\Delta X}\ &= \frac{\ln (1+\Delta Y \% )}{\Delta X} \approx\frac{\Delta Y \% }{\Delta X} \end{align} $$ Sometimes researchers also take logs because the data are long-tailed, and logging them makes the distribution more compact.
The limits of log transformations
The paper’s main point is this: when the data contain zeros and the unit of measurement changes (for example, hourly wages, monthly wages, and weekly wages in labor economics), the estimated effect from the log transformation changes too, which makes the result hard to trust.
We usually think the treatment effect after logging is a kind of percentage effect and should not depend on the scaling parameter $\alpha$. $$ \small ATE=E[\log(1+aY(1))-\log(1+aY(0))]=E\left[\log\left(\frac{1+aY(1)}{1+aY(0)}\right)\right] $$
But once we look more carefully at the structure of the data, things change: $$ \begin{aligned} \lim_{a\to\infty}\log\left(\frac{1+aY(1)}{1+aY(0)}\right)=\begin{cases}\log\left(\frac{Y(1)}{Y(0)}\right)&\text{if }Y(1)>0,Y(0)>0\ 0&\text{if }Y(1)=0,Y(0)=0\ \infty&\text{if }Y(1)>0,Y(0)=0\ -\infty&\text{if }Y(1)=0,Y(0)>0 \end{cases} \end{aligned} $$ The last three cases show exactly where the treatment-effect estimate can be distorted.
The paper’s discussion of this bias is somewhat similar to Local Average Treatment Effects (LATE).
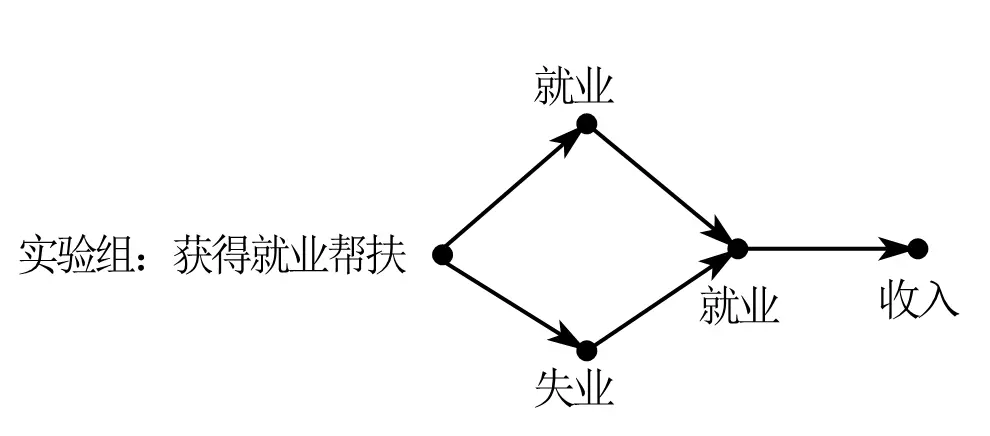
Take an employment policy as the example. The policy shock makes the treated group respond in different ways.
0 means unemployed, and 1 means employed.
Originally, the treated group contains both unemployed people (0) and employed people (1). After the policy shock, everyone ends up employed (1).
- If someone is already employed (1) and remains employed (1) after the shock, but income still rises, then the change in the variable comes directly from the policy shock. This is the intensive margin.
- If someone starts at 0 and moves to 1 after the shock, then the change in the variable comes not only from the policy shock but also from the change in status itself. This is the extensive margin.
So the treatment effect can be thought of like this:
So the average treatment effect is the sum of the expected values of those two margin effects:
$$ ATT=E(ATT^{int})+E(ATT^{ext}) $$
Now suppose we use $lg(1+x)$ and rescale the unit from thousands of yuan to yuan.
For the intensive margin, we have: $$ \begin{aligned} ATT_{1000}^{int}& =E{log(1000Y^{int}(1))-log(1000Y^{int}(0))} \ &=E{log(1000)+logY^{int}(1))-log(1000)-logY^{int}(0))} \ &=E{log(Y^{int}(1))-log(Y^{int}(0))}=ATT^{int} \end{aligned} $$ For the extensive margin, though,
This is the part that moves from 0 to 1. After applying the $ln(y+1)$ transformation, the observations that were originally 0 are still 0.
$$ \begin{aligned} ATT_{1000}^{ext} & =E{log(1000Y^{ext}(1))-log(1000Y^{ext}(0))} \ &=E{log(1000)+logY^{ext}(1))-0} \ &=ATT^{ext}+\color{red}{log(1000)} \end{aligned} $$
The overall treatment effect is the sum of the expected values of those two parts: $$ \begin{align} ATT&=P \times ATT^{ext}+(1-P)\times ATT^{int}\ &=ATT+\color{blue}{P\times log(a)} \end{align} $$ where $\color{blue}{P\times log(a)}$ is the bias term created by changing the measurement unit.
That is why many papers treat the handling of zeros as part of their robustness checks.
The paper also discusses more complicated cases, but honestly, I couldn’t really follow those parts.
Conclusions and possible fixes
Main takeaway
When you’re dealing with a sample where the variable being transformed contains zeros:
A lot of social-media summaries overstate what this paper says. The paper is criticizing log transformations when the variable contains zeros, and the real issue is an impossibility triangle in treatment-effect estimation.
Possible fixes
Each method below amounts to making a trade-off within that impossibility triangle.
- Use standard normalization or standardization to remove unit effects.
- Use Poisson regression with maximum likelihood.
- Drop the zero-value observations.
- Work out the sample distribution more carefully and separate the intensive and extensive margins.
- Use other approaches such as Lee bounds (I still haven’t figured out exactly how to do this one).
References
- One of the authors’ blog
- Maybe your teacher has been teaching this wrong all along: stop using log(Y+0.0000000001)
- A top-5 paper questioned for using log(1+x), fixed effects, and event-study DiD: maybe the conclusions are not reliable
- Top-5 journals now reject log(y+1) and arcsinh(y): absolutely reject them!
- Taking logs: how to deal with zeros and negative values
- The day logs died
- Causal effects
- A quick read: QJE and the end of log transformations
- How to deal with non-positive values
- Code for the “logs with zeros” paper