本文是《An Introductory Guide to Event Study Models 》的代码学习记录,第三部分要解决的是 stata 的代码部分。
本文将介绍 coefplot、eventplot、eventdd、 cnreg 命令在事件研究法中的画图代码。
先来点锐评
简单回顾事件研究法的概念
从操作上上讲 :回归一般估计的是平均处理效应,而事件研究法就是把平均效应按照时间切片。
从统计意义上讲 :每个虚拟时间段就有了个系数,连起来就是平均处理效应的动态变化。
平均估计:
$$
y_{ij}=\beta X_i+\underbrace{\alpha_{i}+\delta_{i}}_{\text{面板固定效应}}+\underbrace{\beta\cdot X_{ij}}_{\text{ 控制变量}}+\epsilon_{ij}.
$$
时间切片以后:
$$
y_{ij}=\underbrace{\left(\sum_{j\in{-m,\ldots,0,\ldots,n}}\gamma_{j}\cdot D_{i,t-j}\right)}_{\text{事件时间虚拟变量}}+\underbrace{\alpha_{i}+\delta_{i}}_{\text{面板固定效应}}+\underbrace{\beta\cdot X_{ij}}_{\text{ 控制变量}}+\epsilon_{ij}.
$$
平行趋势检验只是事件研究法的特例 。比如 A、B 两个县城,A 县城实施了乡村振兴,B 没有,然后 A 富起来了。
我们不能轻易地说就是乡村振兴导致了 A 县城富起来——例如 A 县可能条件本来就得天独厚——风景很美、土质肥沃、矿产资源丰富…… A 和 B 一直都有发展差距。为了验证在乡村振兴以前 A、B 两个村子的数据是几乎相等的,这样 DID 的事件对两个县城来说才是外生的 。
简单来说,平行趋势是想论证——实验组和对照组在事件发生以前几乎没差异。
村庄在事件发生以前的遗漏变量会导致内生性
顺便一提——面板数据一般默认使用双向固定,三期以上的平行趋势检验的系数偏差一直是研究热点。
核心纠结点在于异质性的分解 ,有些变量有时间趋势,而有一些没有;事前趋势形状不同,约束也应当不同。
但真正运用时,这些总体情况也没人知道。
顶刊的事件研究法运用
在我读到的 top5 期刊论文中,已经有一个趋势——能用图展示的都加上图表。因此事件研究法的运用已经越加频繁。
比如可以参考博文《政府一次性投资与制造业长期增长 》
这里举我喜欢的论文其中灵活运用事件研究法的例子。
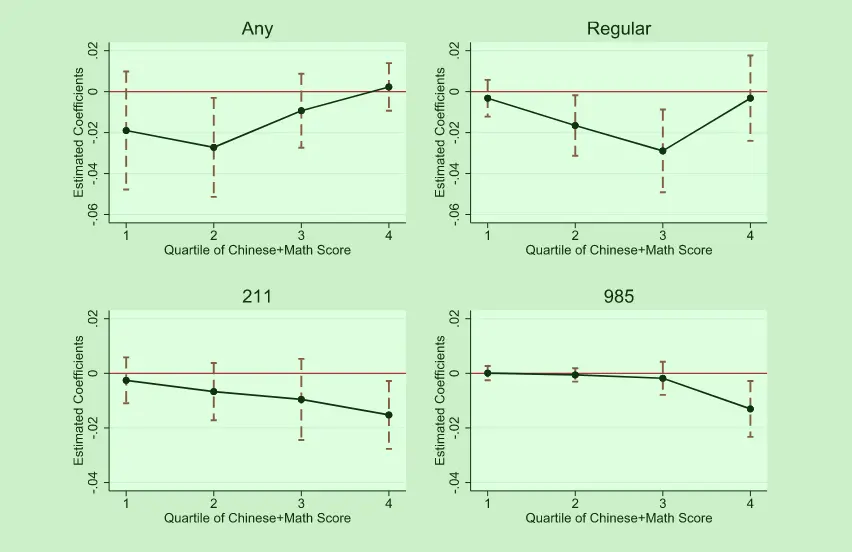
JDE 的《English language requirement and educational inequality: Evidence from 16 million college applicants in China》使用事件分析法,论证英语听力考试加剧了城乡教育不平等。
里面通过事件分析法展现了高考学生分层的异质性——从 985 到一本录取率,影响效果越来越大。
JDE《English language requirement and educational inequality: Evidence from 16 million college applicants in China》
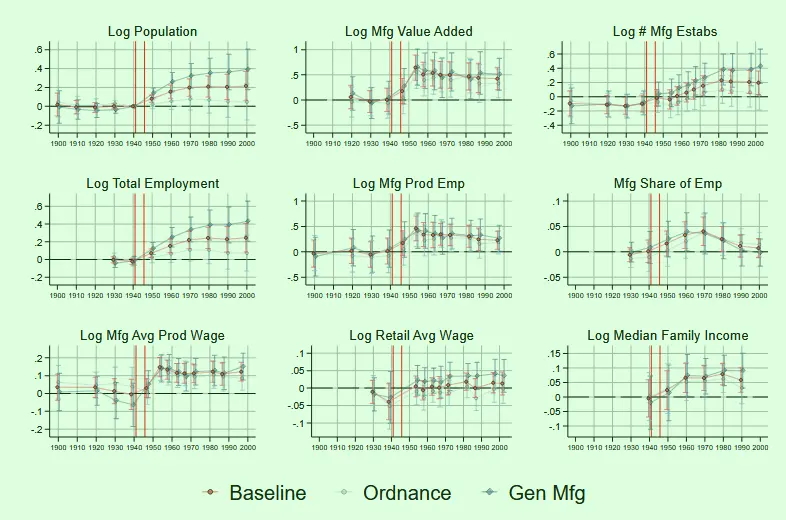
QJE 的《The Long-Run Impacts of Public Industrial Investment on Local Development and Economic Mobility: Evidence from World War II》使用事件分析法,论证冷战时期,美国分散建厂提升了当地儿童的未来工资。
通过多变量更换的动态比较,可以看出当地公司数量没怎么变,但就业人数增长明显,因此是规模效应导致的就业提升而不是企业数量增长。
QJE 的《The Long-Run Impacts of Public Industrial Investment on Local Development and Economic Mobility: Evidence from World War II》
后面还通过人口流动面板论证了工资提升来自本地工作待遇提升而非人力资本提升或者迁入效应。
Stata 代码
以下示例数据为中国工业经济的《创新驱动政策是否提升城市创业活跃度——来自国家创新型城市试点政策的经验证据 》。
其实我也想用自己收集的数据举例子,奈何一个也不显著! 🤧
数据都在官网附件中,直接进去下载即可。这篇论文也应该是国内较早公开整个双重差分流程代码的论文。城市面板数据用来学习任何代码都好使。
平行趋势检验的两种方式
coefplot 命令
coefplot 命令可以获取回归系数,我们只需要生成时间虚拟变量,进行回归,然后通过命令储存系数然后画图即可。
步骤概括:
定义面板数据
设置事件时间,年份减去事件时间,然后依次生成对应时间切片的虚拟变量
回归
储存系数,画图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
clear all
use "F:\桌面\事件研究法发学习代码\数据.dta" , clear
xtset city year
* 生成相对时间变量 di当年年份 - 改革年份
gen di = year - branch_reform
sum di // 目前是 - 14 到 10 期,太长,可以缩短窗口期,可以缩短或者合并
* 去掉或者合并两段的数据
replace di = - 10 if di < - 10
replace di = 10 if di > 10
* 生成提前到虚拟变量 d_1和d_10
forvalues i = 1 / 10 {
gen d_ ` i '=(di==-`i' )
}
* 生成提前到虚拟变量 d1和d10
forvalues i = 1 / 10 {
gen d ` i '=(di==`i' )
}
* 回归
xtreg entre_activation d_2 - d_10 d1 - d9 di i . year lnagdp indust_stru finance ainternet market i . city # c . di , fe r
xtreg entre_activation d_2 - d_10 d1 - d9 di i . year lnagdp indust_stru finance ainternet market i . city # c . di , fe r
# delimit ; // 自定义换行符号,也就是 ; 才是换行。这样便于画图命令。
;
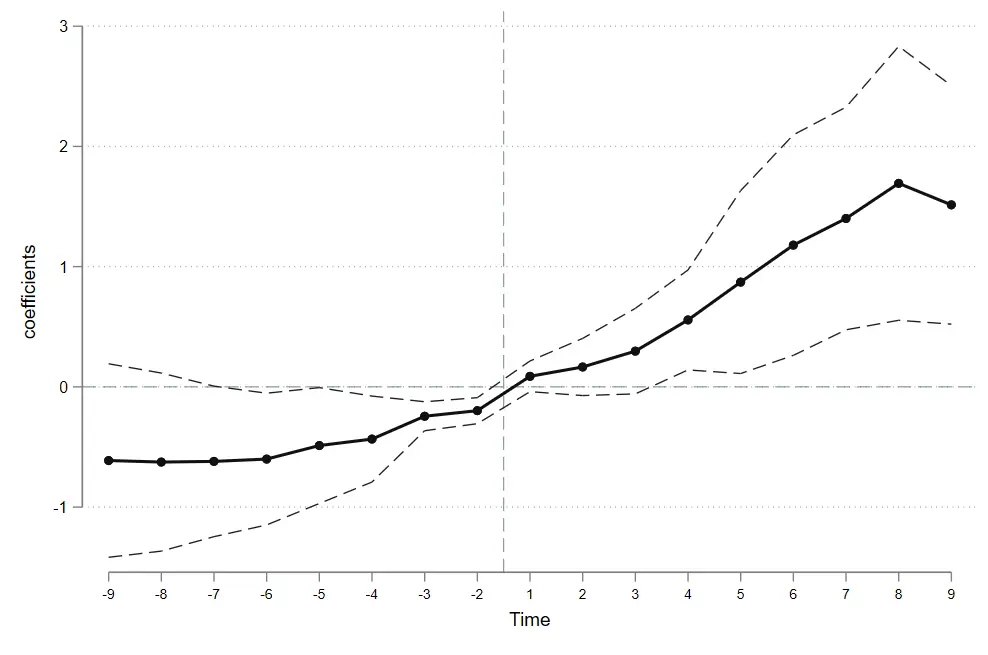
coefplot ,
baselevels
keep ( dd_10 d_9 d_8 d_7 d_6 d_5 d_4 d_3 d_2 d1 d2 d3 d4 d5 d6 d7 d8 d9 )
order ( d_10 d_9 d_8 d_7 d_6 d_5 d_4 d_3 d_2 d1 d2 d3 d4 d5 d6 d7 d8 d9 )
vertical // 转置图形
coeflabels (
d_10 =- 10 d_9 =- 9 d_8 =- 8 d_7 =- 7 d_6 =- 6 d_5 =- 5 d_4 =- 4 d_3 =- 3 d_2 =- 2 d_1 =- 1
d1 = 1 d2 = 2 d3 = 3 d4 = 4 d5 = 5 d6 = 6 d7 = 7 d8 = 8 d9 = 9 d10 = 10
)
yline ( 0 , lwidth ( vthin ) lpattern ( dash ) lcolor ( teal ))
xline ( 8 . 5 , lwidth ( vthin ) lpattern ( dash ) lcolor ( teal ))
ylabel (, labsize ( * 0 . 85 ) angle ( 0 )) xlabel (, labsize ( * 0 . 75 ))
ytitle ( "coefficients" )
xtitle ( "Time" )
msymbol ( O ) msize ( small ) mcolor ( gs1 ) // 点样式
addplot ( line @ b @ at , lcolor ( gs1 ) lwidth ( medthick )) // 连线
ciopts ( recast ( rline ) lwidth ( thin ) lpattern ( dash ) lcolor ( gs2 )) // 置信区间样式 rarea rline rcap
graphregion ( color ( white )); // 底色设置
# delimit cr // 还原换行符号
coefplot 命令
Eventdd 命令
Eventdd 命令可以一步到位画图,参照下面代码输入对应参数即可。
Eventdd 后面直接跟变量就是对应的回归。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
clear all
use "F:\桌面\事件研究法发学习代码\数据.dta" , clear
set scheme white_tableau
xtset city year
# delimit ;
;
gen di = year - branch_reform ;
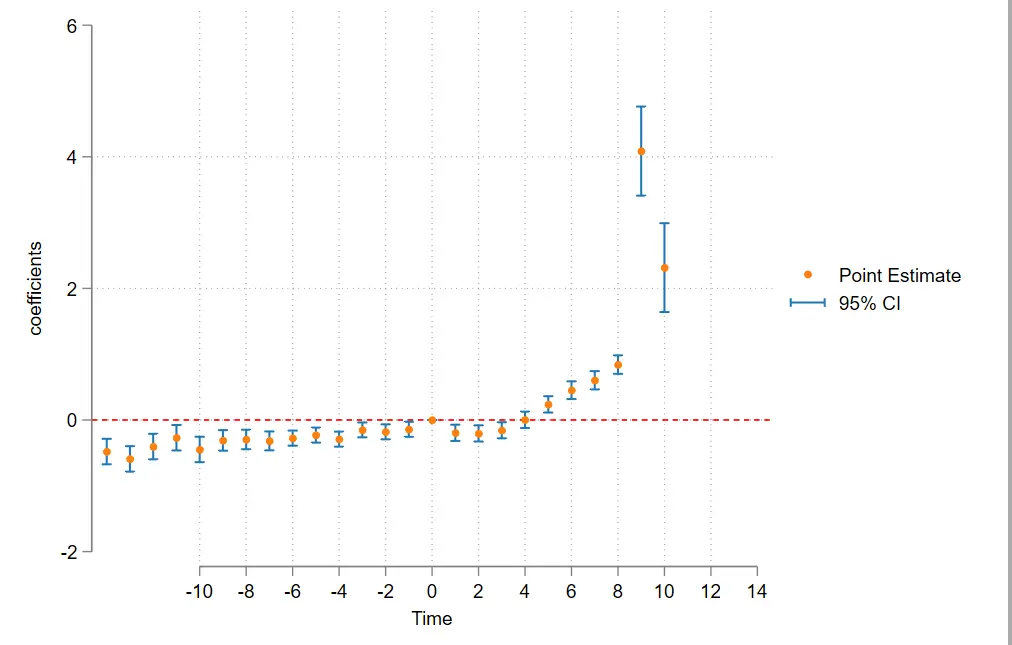
eventdd entre_activation i . year lnagdp indust_stru finance ainternet market ,
timevar ( di ) // 定义时间虚拟变量
ci ( rcap ) // 误差条
noline // 不绘制 - 1 期的置信区间条
method ( fe ) // 如果要添加自相关聚类—— method ( fe , cluster ( 自相关聚类 ))
baseline ( 0 ) // 基础年份为 0
level ( 95 )
graph_op ( ytitle ( "coefficients" ) xtitle ( "Time" ) xlabel ( - 10 ( 2 ) 14 )); // 取消自定义换行
# delimit cr
Eventdd
关于平行趋势的回归提示
我选择的回归式子是:
1
xtreg entre_activation d_2 - d_10 d1 - d9 di i . year lnagdp indust_stru finance ainternet market i . city # c . di , fe r
其中 i.city#c.di 是额外控制了每个个体的时间趋势(时间效应分解的是截距,这里分解的是斜率)。
舍去了 d_1 期,一方面是省略做基准值,另一方面也可以避免共线性。
有些文章会减去系数均值,让图看起来更美观,但并非必要操作。
平行趋势虽然偏差争议大,但是不做上面几点也没人仔细关注,只是做了可能更好。
有约束的回归
参照《An Introductory Guide to Event Study Models 》的代码,我们可以对回归加上约束。
使用 cnsreg 代码即可。在 计量:事件研究法 2 中我已做过说明。在 coefplot 命令中将回归换成有约束的回归即可。
constaint 命令设置约束条件,在回归中加 c (1-5) 就是把五条 约束全部加上去,你悟 了吗?
1
2
3
4
5
6
7
constraint 1 d_1 = d_2 // 对应系数相等
constraint 2 d_2 - d_1 = d_4 - d_3 // 对应斜率相等
constraint 3 d_1 = d_2 * 0 . 5
constraint 4 d_1 = d_2 + d_2
cnsreg entre_activation d_2 - d_10 d1 - d9 di i . year lnagdp indust_stru finance ainternet market i . city # c . di , c ( 2 ) r
同一个图上展现多组回归系数
twoway 命令也可以做到,但是太麻烦,所以这里不再介绍。
Coefplot 命令
还是使用 coefplot 命令,其他参数依旧可以添加——但是无法设置线条参数 (addplot)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
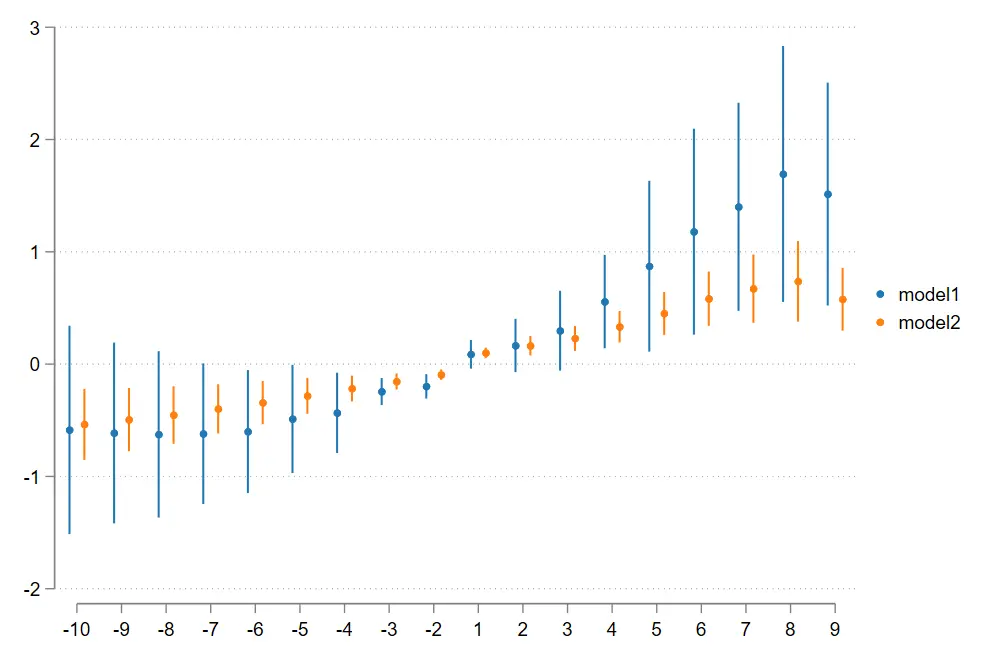
// 运行第一个回归模型
xtreg entre_activation d_2 - d_10 d1 - d9 di i . year lnagdp indust_stru finance ainternet market i . city # c . di , fe r
estimates store model1 // 保存第一个模型
// 运行第二个回归模型(可以是不同的变量或设定)
xtreg produserv d_2 - d_10 d1 - d9 di i . year lnagdp indust_stru finance ainternet market i . city # c . di , fe r
estimates store model2 // 保存第二个模型
// 画平行趋势图
set scheme white_tableau
# delimit ;
;
coefplot model1 model2 , // coefplot model1 || model2
baselevels
keep ( d_10 d_9 d_8 d_7 d_6 d_5 d_4 d_3 d_2 d1 d2 d3 d4 d5 d6 d7 d8 d9 )
order ( d_10 d_9 d_8 d_7 d_6 d_5 d_4 d_3 d_2 d1 d2 d3 d4 d5 d6 d7 d8 d9 )
vertical
coeflabels (
d_10 =- 10 d_9 =- 9 d_8 =- 8 d_7 =- 7 d_6 =- 6 d_5 =- 5 d_4 =- 4 d_3 =- 3 d_2 =- 2 d_1 =- 1
d1 = 1 d2 = 2 d3 = 3 d4 = 4 d5 = 5 d6 = 6 d7 = 7 d8 = 8 d9 = 9 d10 = 10
);
yline ( 0 , lwidth ( vthin ) lpattern ( dash ) lcolor ( teal ))
xline ( 8 . 5 , lwidth ( vthin ) lpattern ( dash ) lcolor ( teal ))
ylabel (, labsize ( * 0 . 85 ) angle ( 0 )) xlabel (, labsize ( * 0 . 75 ))
ytitle ( "coefficients" ) xtitle ( "Time" )
msymbol ( O ) msize ( small ) mcolor ( gs1 )
ciopts ( recast ( rcap ) lwidth ( thin ) lpattern ( dash ) lcolor ( gs2 )) // rarea rline rcap
legend ( order ( 1 "entre_activation" 2 "produserv" ) region ( lstyle ( none )) position ( 6 ))
graphregion ( color ( white ));
多个图
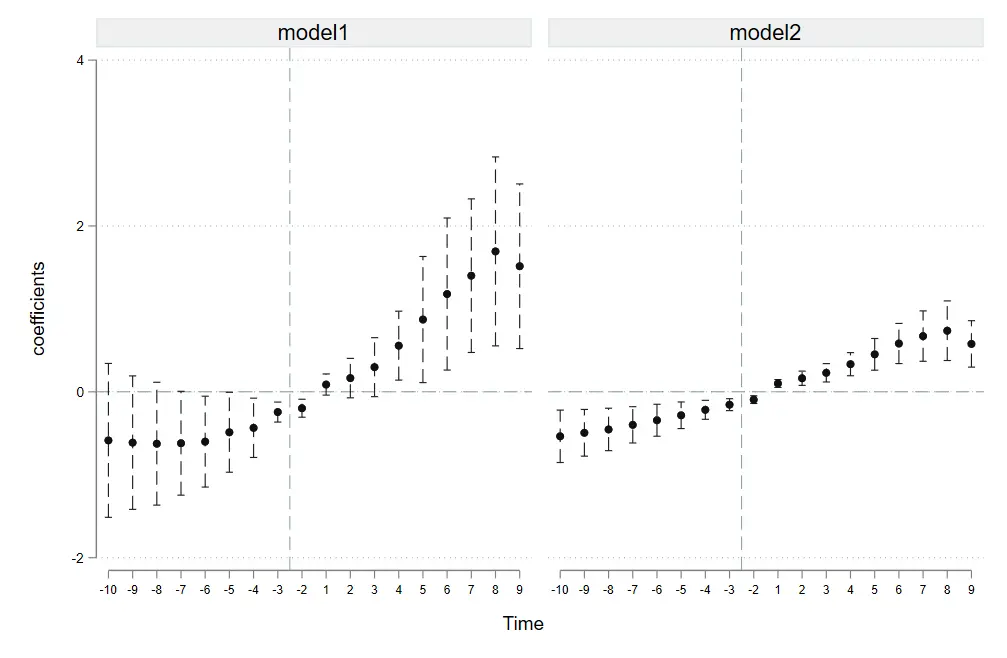
如果不在一个图上展示,和其他命令设置一样,加入分隔符 即可。
1
coefplot model1 || model2,
不在同一个图上
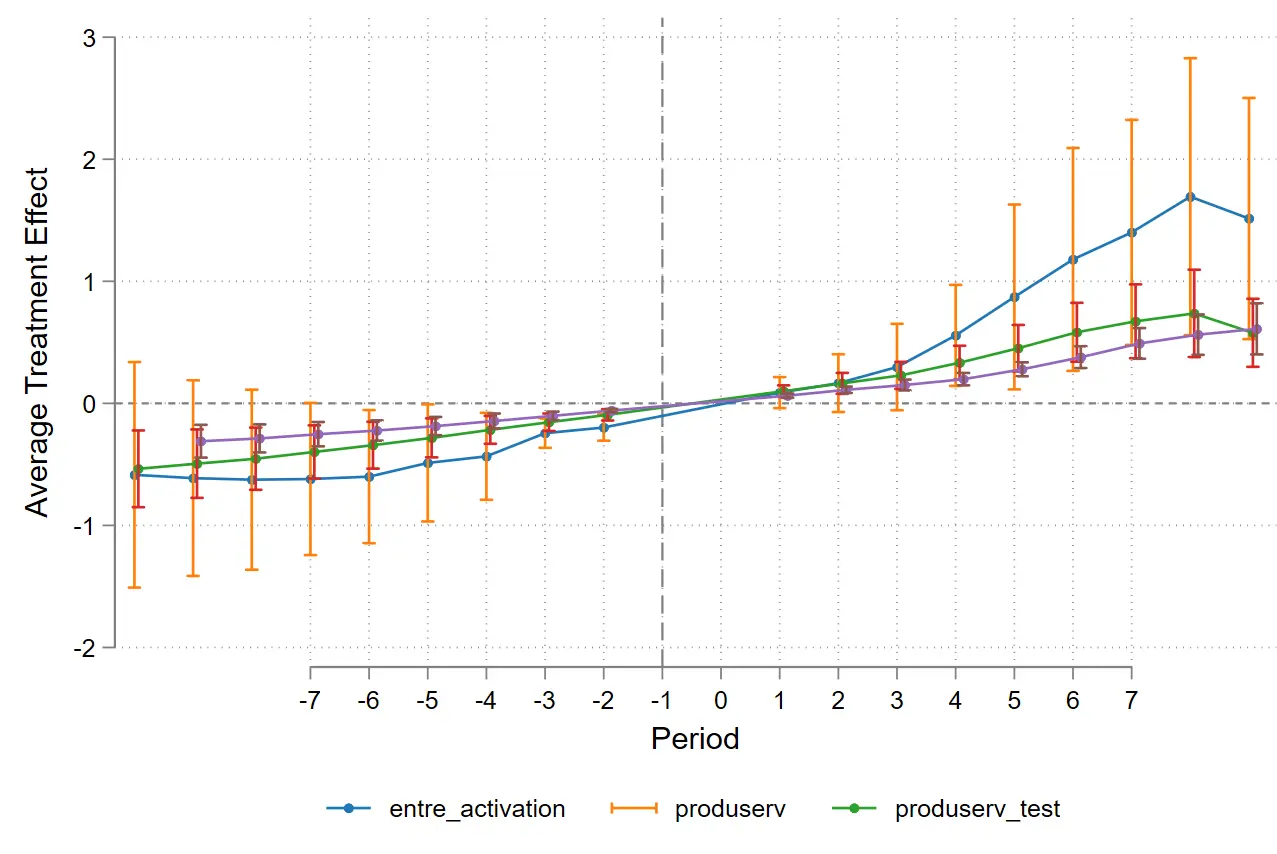
Event plot 命令
我估计大部分刊物存在连线的图,如果用的不是 R 语言,应该都是是 event plot 命令画出来的。
这个命令好处是可以设置不同的改革年份进行比较,而且支持连线点图。该命令似乎针对双重差分有很多很好的子命令。
估计本文提到的 QJE 那一篇是用的这个命令画的图。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
clear all
use "F:\桌面\事件研究法发学习代码\数据.dta" , clear
set scheme white_tableau
xtset city year
// 生成相对时间 : 当年年份 - 改革年份
gen di = year - branch_reform
sum di // m目前是 - 11 到 12 期,太长,可以缩短窗口期,可以缩短或者合并
* 去掉或者合并两段的数据
replace di = - 10 if di < - 10
replace di = 10 if di > 10
* 生成提前到虚拟变量 d_1和d_10
forvalues i = 1 / 10 {
gen pre_ ` i '=(di==-`i' )
}
* 生成提前到虚拟变量 d1和d10
forvalues i = 1 / 10 {
gen post ` i '=(di==`i' )
}
gen testi = di + 1
* 生成提前到虚拟变量 d_1和d_10
forvalues i = 1 / 10 {
gen fpre_ ` i '=(testi==-`i' )
}
* 生成提前到虚拟变量 d1和d10
forvalues i = 1 / 10 {
gen fpost ` i '=(testi==`i' )
}
// 运行第一个回归模型
xtreg entre_activation pre_2 - pre_10 post1 - post9 di i . year lnagdp indust_stru finance ainternet market i . city # c . di , fe r
estimates store model1 // 保存第一个模型
// 运行第二个回归模型(可以是不同的变量或设定)
xtreg produserv pre_2 - pre_10 post1 - post9 di i . year lnagdp indust_stru finance ainternet market i . city # c . di , fe r
estimates store model2 // 保存第二个模型
// 运行第二个回归模型(可以是不同的变量或设定)
xtreg produserv fpre_2 - fpre_10 fpost1 - fpost9 di i . year i . city # c . di , fe r
estimates store model3 // 保存第二个模型
# delimit ;
;
event_plot model1 model2 model3 ,
stub_lag ( post # post # fpost # ) stub_lead ( pre_ # pre_ # fpre_ # )
plottype ( connected ) ciplottype ( rcap ) together noautolegend
graph_opt ( xtitle ( "Period" , size ( middle )) ytitle ( "Average Treatment Effect" , size ( middle )) xlabel ( - 7 ( 1 ) 7 ,) legend ( order ( 1 "entre_activation" 2 "produserv" 3 "produserv_test" )
rows ( 1 ) position ( 6 ) region ( style ( noe ))) xline ( - 1 , lcolor ( gs8 ) lpattern ( dash )) yline ( 0 , lcolor ( gs8 ))
graphregion ( color ( white )) bgcolor ( white ) ylabel (, angle ( horizontal )));
plottype(connected ) 处就是设置既有连线又有点。
Stub_lag (post# post# fpost#) stub_lead (pre_# pre_# fpre_#) 如果三个模型共享一个横坐标,只需要输入共享的横坐标符号即可。但是此处我为了测试,提前了其中一年(model 3)的改革年份, 因此需要一一对应,即便是同一个坐标也要重复写出来。
Event plot
总结
计量就像这图一样,看起来复杂,但核心思想总是一句话就能说清。
就操作上的理解来看——事件研究法只是系数可视化罢了 ,但组合起来可以形象地展示更多东西——异质性、结构比较、平行趋势、组间差异、长期效应…… 其实更重要的还是分组回归的设计思想与经济意义的考察分析。