
双剑合璧:智能体时代的 Stata 实证

当 ai 打败柯洁时,人们依旧认为 ai 离自己的事业很遥远,正如柯洁看到 ai 打败李世石时的年少轻狂。直到 2026 年,实证学习者们才开始围绕 ai 建立一种"自动化"的恐惧。
最近 David Yanagizawa-Drott 教授启动了智能体实证分析项目(APEP 项目);陶哲轩建立了智能体对 Erdős 数学问题集贡献的项目(AI contributions to Erdős problems)。计算机领域热词也层出不穷——agent、skill、vibecoding、mcp、ABM model……1
就具体研究而言,再比如两个具体例子2:
- 《A dataset on the spatiotemporal distributions of street and neighborhood crime in China》:使用 LLM 提取裁判文书刑事案件的变量。
- 《Decoding China’s Industrial Policies》: 使用 LLM 对海量政策进行编码解析。
不严谨的概括:让 ai 成为一个(具备某些特点的)操控主体(agent),能操控自己电脑上的软件(mcp 能力),也就完成了一种自动化编程流程(vibecoding)。结合 ai 的 api 和 VSCode 插件。这里我们可以建立一个粗糙的环境简单体验一二。
让 ai 操控软件
最简单的集成版本—— cusor、claudecode3。
但是我们也可以通过 VSCode 实现 all in one。
需要以下软件:
- VSCode:代码编写环境
- Git:版本控制,文件传输管理
- Node.js:可以写后端、操作文件、控制硬件。
- cc Switch: 调用集成 ai 的 api。
针对国内环境,推荐参考以下视频:
当实现以后,就可以在 VSCode 中调用 ai 的 api 直接操作编辑页面。
若是第一次使用 VSCode, 操作记得先建立一个新文件夹,然后打开 VSCode, 点击文件,打开新建的对应文件夹,剩下的就是在其中操作了。
进一步加入 stata 插件
StataMCP 插件
当你完成上一步操作后,你完全可以调用 ai 服务帮你开展其他设置操作😀。

我个人推荐在 VSCode 中下载这几个 stata 插件。
- Stata language:识别 stata 语法
- Stata Outline:让代码能识别大纲,标题格式为
**#。有几个#就是几级标题,最多六级标题。 - Stata MCP:核心,让 VSCode 具备控制 stata 的能力。
需要的额外设置也很简单,只需要在 stata MCP 的设置页面输入自己安装 stata 的文件夹目录:
例如我的就是 D:\stata。我使用的是 stata MP 版本4。
Stata MCP 插件会让页面出现以下按键,其实就对应着 stata 的运行。
让 ai 具有调用 stata 的权限
为了让 ai 具有操纵 stata 软件的能力,首先需要下载 mcp 协议桥梁 mcp-proxy。
|
|
直接在 powershell 窗口运行以下代码即可下载
|
|
Claude code 接入 statamcp
claude code 对 mcp 的管理比较谨慎,兼容不像 codex 那么便利。目前我似乎是通过在 .claude 下方添加以下 .json 文件实现了连接。
|
|
Codex 接入 statamcp
这种接入要求 stata 必须有许可证。如果用的 stata 破解版需要基于许可证的破解版。
接下来在 ai 的本地设置中,让 ai 知道我们已经打通了调用 stata 的权限。例如目前我使用的是 vscode+codex 的组合,本地配置文件就在 C:\Users\Administrator\.codex\config.toml
这一步直接让 ai 自己修改即可。
加入以下设置
|
|
最终 ai 就用有了自己运行代码的能力。
提示词:修改完善代码,基于sysuse auto进行一个实证分析。加入代码大纲层次,** # 为标题格式。 # 有几个代表几级标题,最多六级标题。
其他 statamcp 插件
LSE 的 Thomas Monk 教授也出了一个自己搭建的 statamcp 插件 Stata Workbench。不过我个人觉得没有 statamcp 插件好用。
关于选择哪家的本地 cli 编辑器。如果不止用 vscode, 个人推荐 claude code ,切换其他模型更便捷,跨平台推广更好。如果只在 vscode 上使用,个人推荐 codex,目前工程上的优化确实优于 claude code。
论文测试
目前我用这套流程测试产生了三篇论文:
- 第一篇:让 ai 自己清洗 csmar 的企业数据并进行分析《组织规模、人力资本结构与上市公司违规风险:来自中国上市公司的面板证据》
- 第二篇:测试 ai 的数理建模《走人户随礼、关系资本与跨期财富配置:一个关于中国礼物流动的经济学解释》
- 第三篇:测试 ai 的可视化程度《城市企业进入退出与营商活力:基于 2000-2023 年全国市级地区-年份面板的描述性研究》
Obsidian 加入 ai
同样,当你完成第一部——配置好 claude 调用 deepseek 的 api 后,你也可以在其他编辑器上实现同样的操作。例如 obsidian。
BRAT 是 Obsidian 用于安装测试版插件的工具。
-
安装 BRAT:
-
在 Obsidian 设置中,前往 Community plugins(第三方插件) -> Browse(浏览)。
-
搜索并安装 BRAT (Beta Reviewers Auto-update Tester)。
-
安装后点击 Enable(启用)。
-
-
添加 Claudian 仓库:
-
打开 BRAT 插件设置。
-
点击 Add Beta plugin。
-
在弹出窗口中输入 GitHub 地址:
YishenTu/claudian。 -
点击 Add Plugin。
-
我个人喜欢让其翻译本博客中文文档,适配英文版本。
推荐 api?
Api 平台
个人觉得国内 api,deepseek 的性价比最高。
以下大厂平台都送一些注册免费额度:
基于 api 消费数据看 llm 市场
最近已经有论文利用 api 提供市场进行分析。典型的就是国内也可以用的 OpenRouter。OpenRouter 也提供了一些免费的大模型。不过免费调用赚的是账户余额。
限制可以参考:limits
- 未充值或余额不足 10 美元的用户:每日 50 次请求。(以前为 200 次)
- 账户余额在 10 美元以上的用户:每日请求从之前的 200 次提高至 1000 次
- 每分钟 20 次请求:无论哪种用户,免费模型均维持每分钟最多 20 次请求的限制。
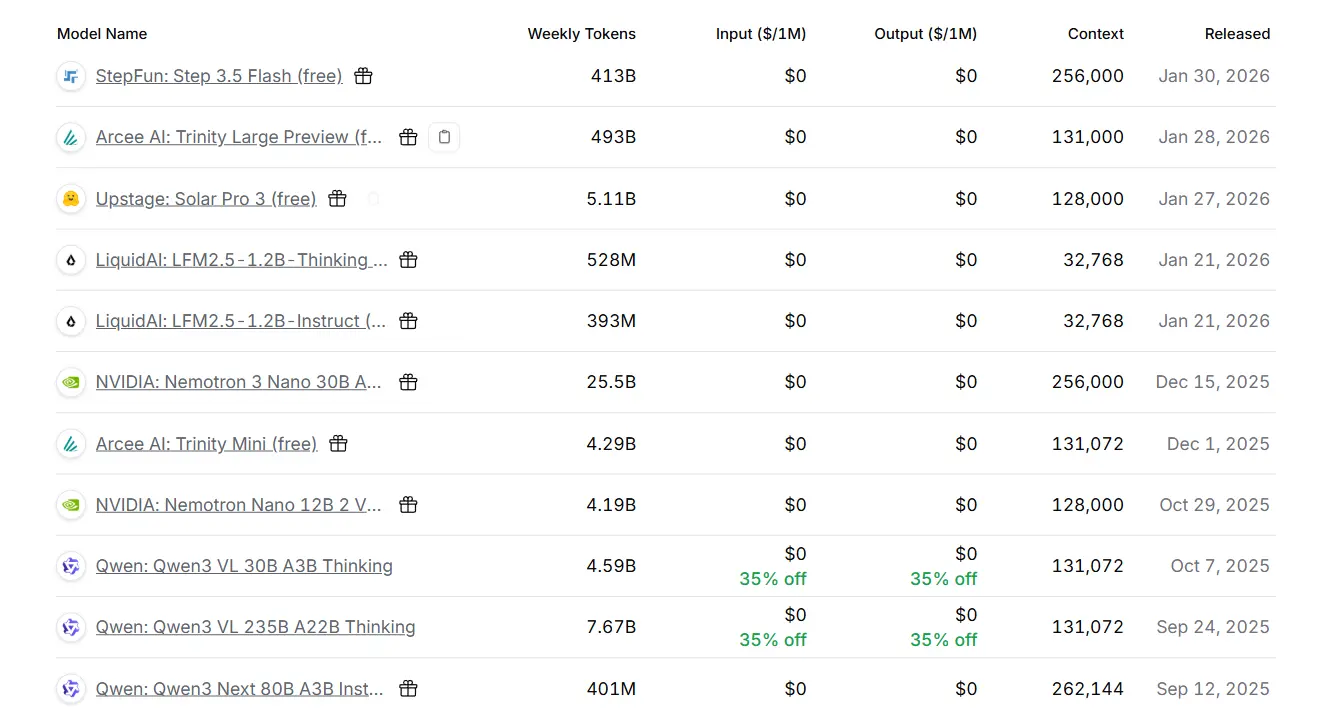
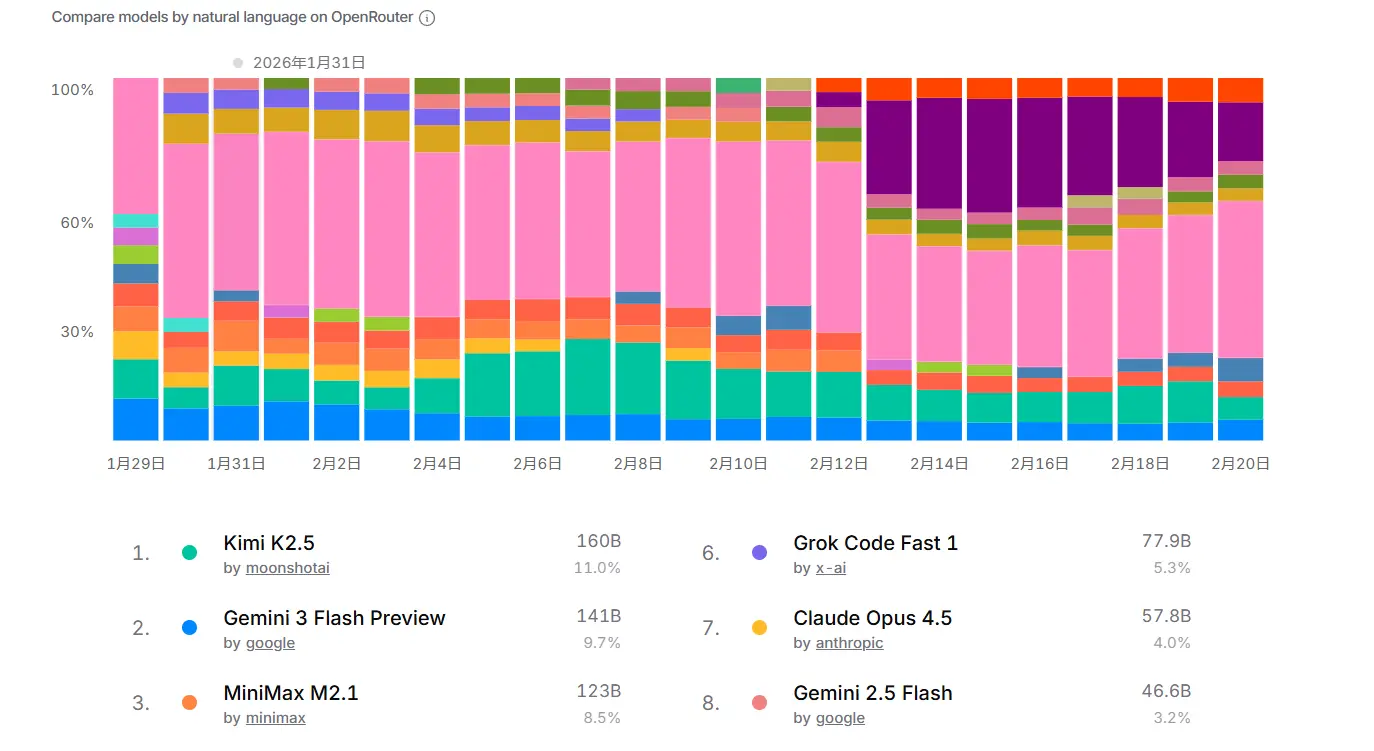
NBER 最近有篇论文爬取了 OpenRouter 网站的数据进行市场分析:
《The Emerging Market for Intelligence: Pricing, Supply, and Demand for LLMs》
最让我印象深刻的是下面这几个图:
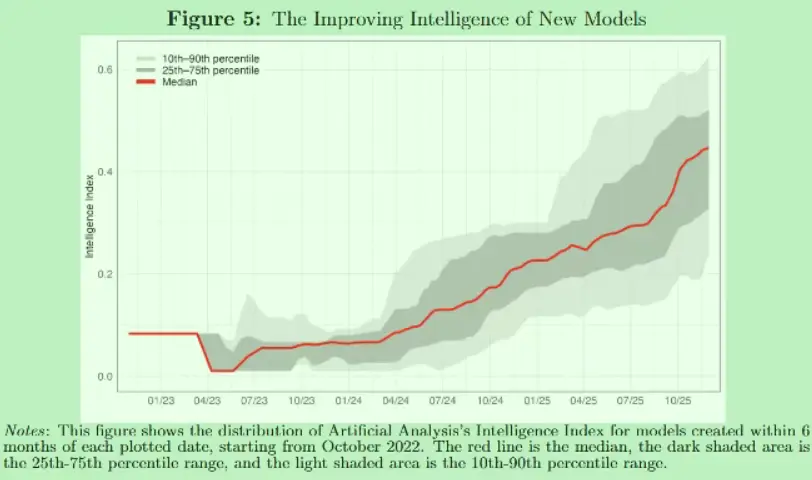
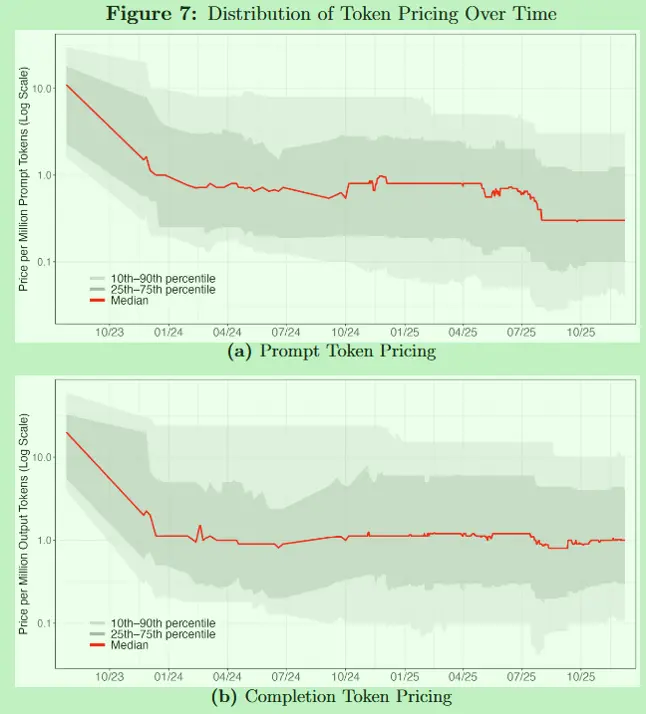
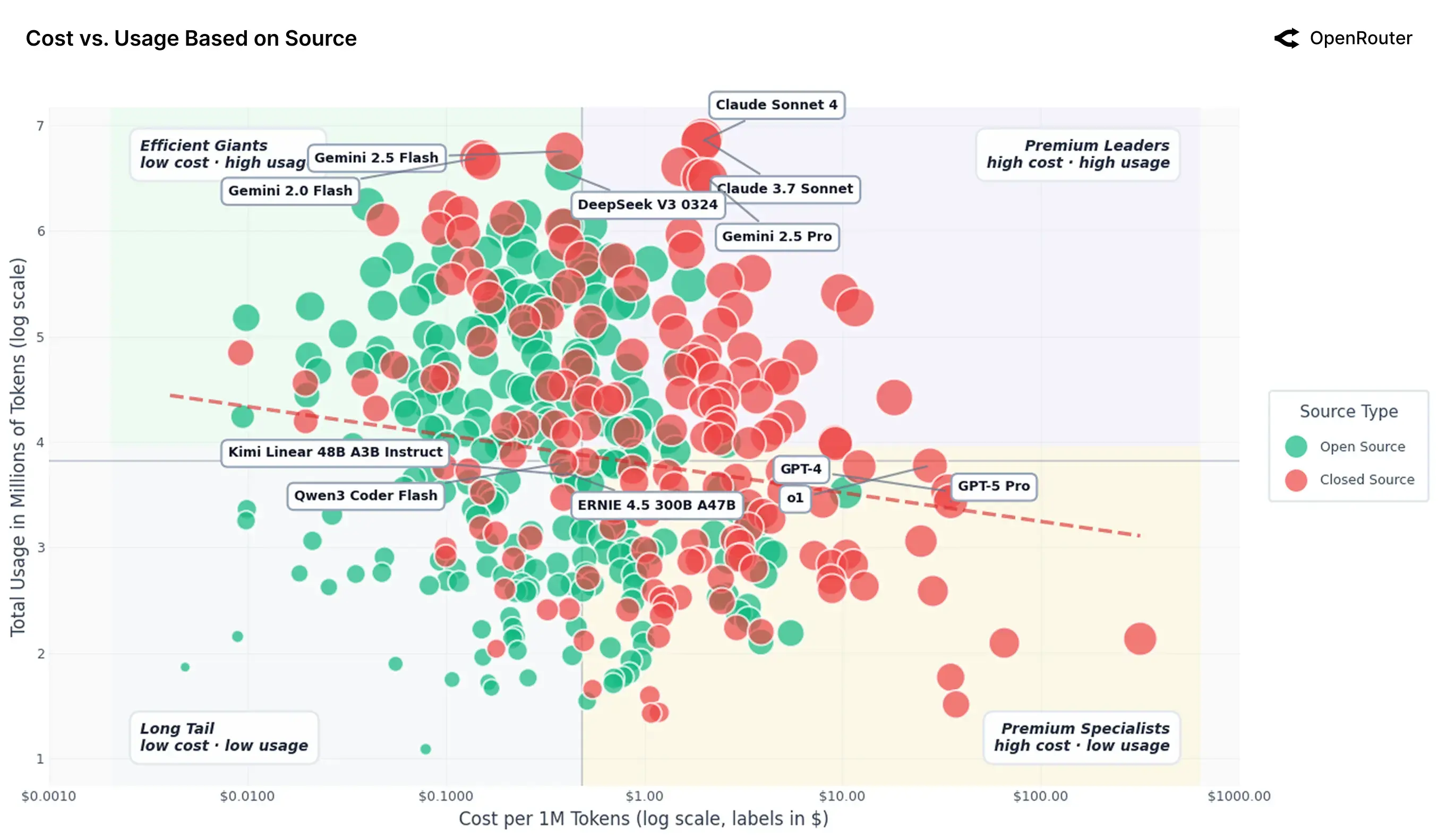
在 NBER 论文之前,其实 OpenRouter 团队自己就用数据做过分析,就在:
《An Empirical 100 Trillion Token Study with OpenRouter》
安装 skills
安装与说明
Skills 其实就是 ai 的指导说明书,指导其在具体场合具体怎么处理。在其中添加脚本或流程就能约束模型在特定场景下的输出结果。
关于 skill ,特别推荐阅读这位博主的文章进一步了解:
《上下文是稀缺资源|RAG、Memory、Skills 的设计哲学刍议》
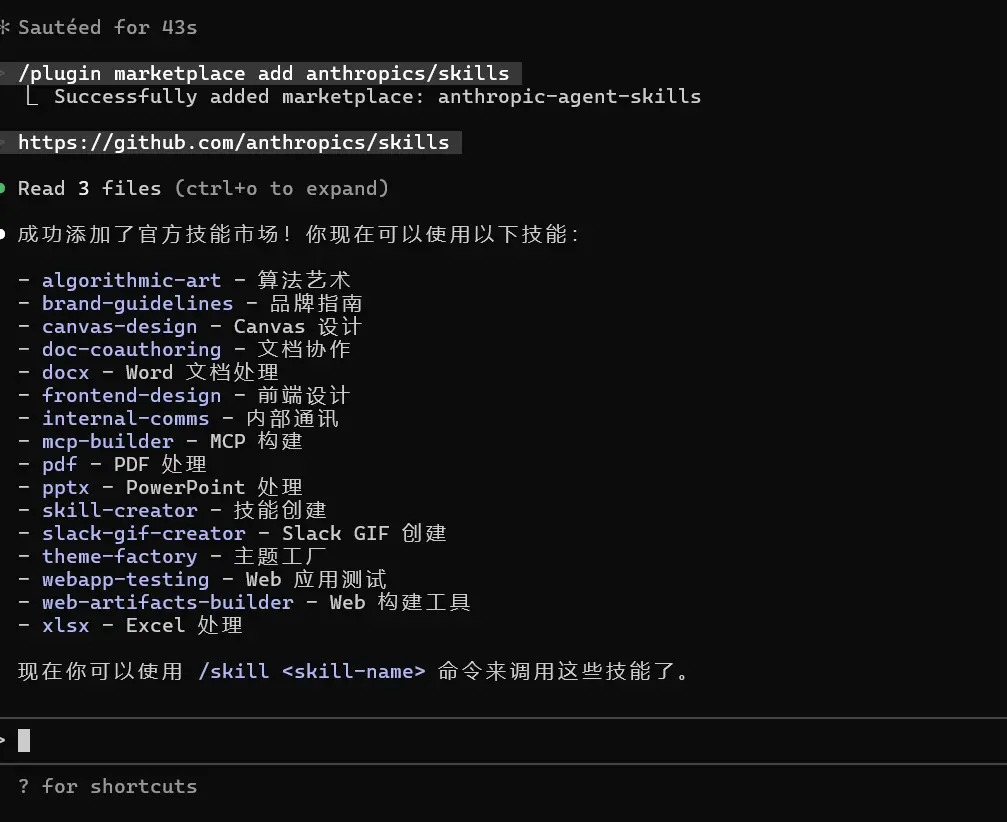
此时依次输入以下命令,就可以下载 claude 官方准备的 skills 包。
安装 skills 市场:
|
|
安装官方编写的一些 skills 包
|
|
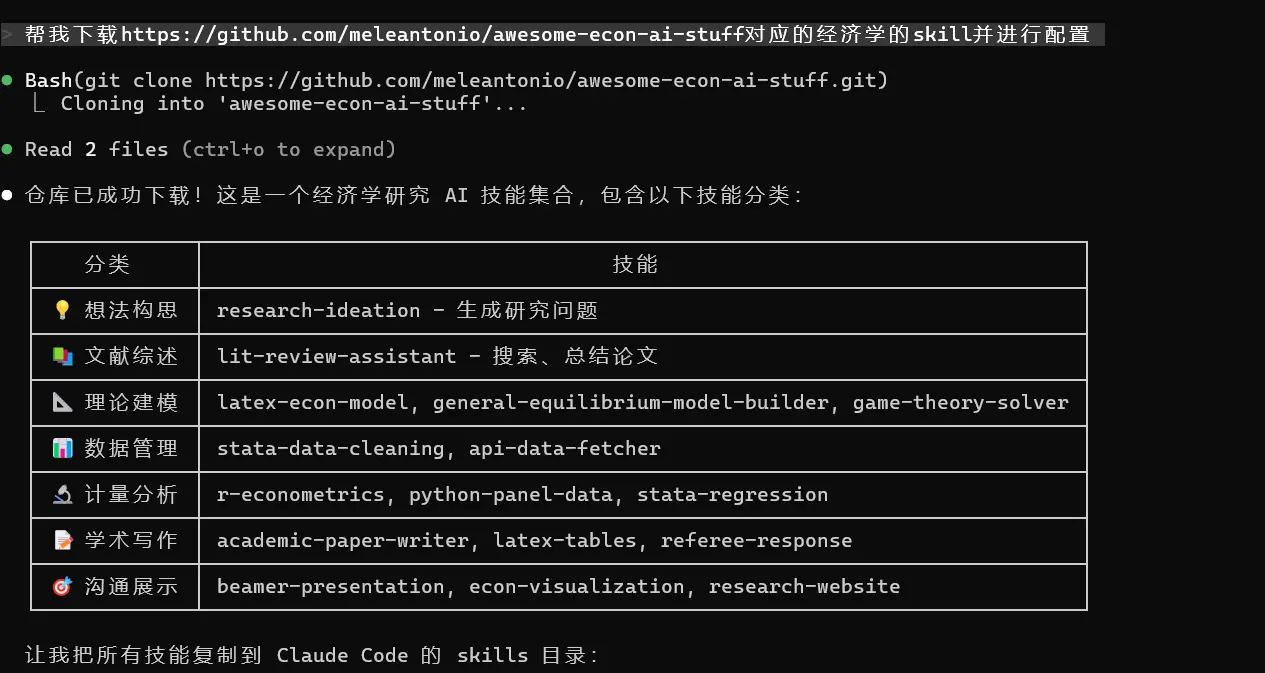
例如我直接将一个经济学 skills 的 github 发给 claude 让它自己下载:
|
|
例如,这是我在下载 obsidian 的 skills 后,让它绘制了一篇博客文章的思维导图:
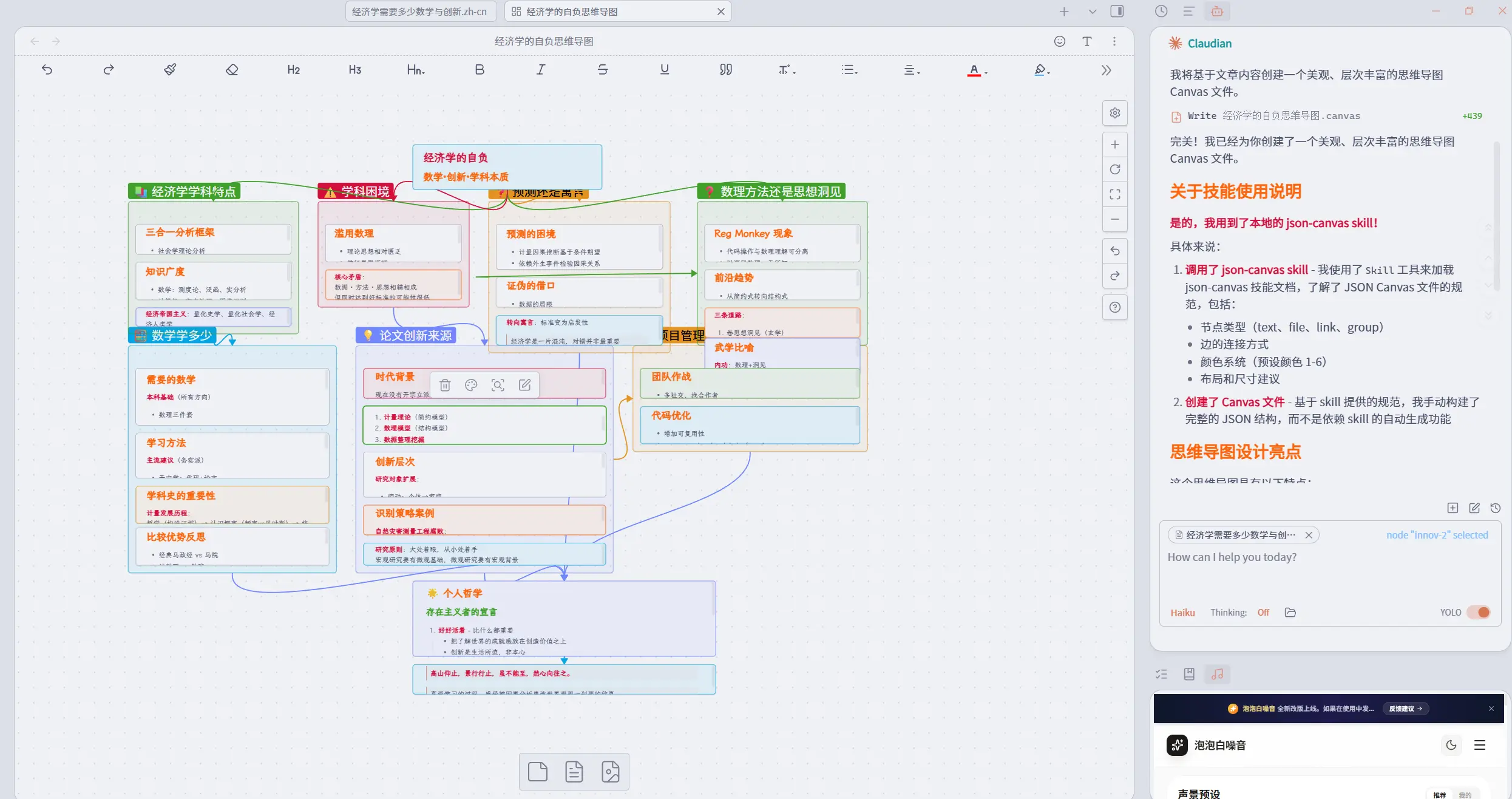
与 skill 形成配合的往往还有 hook。如果说 skill 是 ai 的指导书,让 ai 能快速地选择参考资料;hook 就是参考指南。简单的理解为——特定场景下强制执行的脚本。例如一旦阅读文献,执行一个给定的词云分析脚本。Hook 可以和 skill 匹配使用,形成指令判断-选择流程-执行脚本的过程。
Skill 资源
可以在以下网站寻找 skills 资源
- Skills. Sh (个人推荐,也推荐参考这里面的命令统一安装 skills )
- skillsmp.com
- awesome-agent-skills
首先推荐个寻找 skills 的命令,安装之后明显调用 skills 更顺畅准确率。
|
|

更深的自动化术语?
如果想要更深入地了解当今结合 ai 的自动化流程,或许可以进一步检索 vibecoding 相关术语。现在也有很多经济学家开始介绍自己的 stata+智能体编程。例如:
对标同样的 claude code ,openai 的是 codex,google 的则是 gemini cili6。如今正在早期竞争阶段,各家注册福利都不少。
现在估计每门计量经济学,甚至是经济学的开学第一课,都是自问怎么应对 ai 冲击。不过也别怕,工业革命之前还得是能源革命。现在 ai 烧钱烧资源性价比太低了,泛用注定是个大问题。但是,让人恐怖的不是 ai 的绝对值,而是进步的迭代速度,至少能让我们对变化的时代保持一种清醒。从另外一个角度讲,赛车早已超越了人类的极限,我们却依旧为百米赛跑感到刺激、恐惧、兴奋。若真如刘慈欣《诗云》那样7,某种文明能排列出所有的文字组合,我们对诗歌的感受才是更重要的事情。
