随着“自主知识体系构建”思潮兴起,中文期刊排版要求越来越严格,例如表格变量不能出现英文名称。还有一如既往的要求,图片中文使用宋体,英文使用 times 字体。
Stata 图像框只支持统一设置一种字体,因此中英文字体需要在代码中额外设置下。
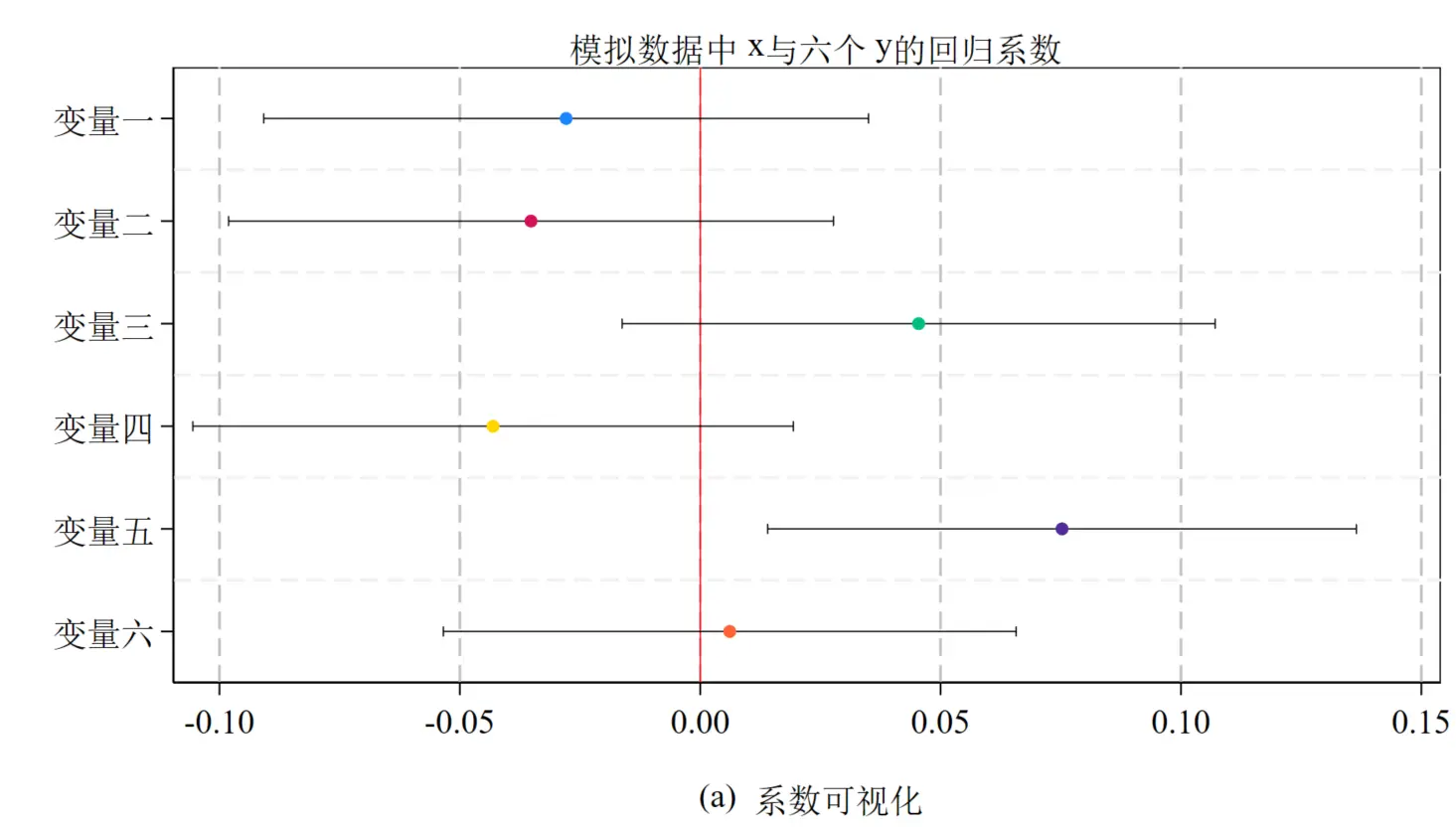
回归系数可视化与中英文字体
使用 local 暂元命令储存下字体命令。
1
2
|
local zh1 `"fontface "SimSun":"' // 宋体
local en1 `"fontface "times":"' // times
|
然后在图像中进行对应的设置,例如:
1
|
title(`"{`zh1' 模拟数据中}{`en1' x}{`zh1'与六个}{`en1' y}{`zh1'的回归系数}"', size(medium))
|
具体代码,
- 生成六个 y 变量
- 生成一个 x 变量
- 六个 y 分别对 x 回归(六次回归)
- 系数可视化
绘图风格为 stata18 新加入的默认风格 stcolor。个人喜欢全包围的方框。推荐标签和字体大小都设置 medium, 不然后续图片组合难以看清。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
clear
set seed 20250707
set obs 1000
* 解释变量 x
gen x = rnormal(0, 1)
* 六个被解释变量 y1–y6(各自系数接近 0)
gen y1 = 0.01*x + rnormal(0, 1)
gen y2 = -0.02*x + rnormal(0, 1)
gen y3 = 0.015*x + rnormal(0, 1)
gen y4 = -0.005*x + rnormal(0, 1)
gen y5 = 0.012*x + rnormal(0, 1)
gen y6 = 0.00*x + rnormal(0, 1)
local ys y1 y2 y3 y4 y5 y6
foreach y of local ys {
reg `y' x
estimates store m_`y'
}
local zh1 `"fontface "SimSun":"' // 中文字体
local en1 `"fontface "times":"' // 英文和数字字体
* 绘制图形
coefplot ///
(m_y1, rename(x = `"{`zh1' 被解释变量1}"')) ///
(m_y2, rename(x = `"{`zh1' 被解释变量2}"')) ///
(m_y3, rename(x = `"{`zh1' 被解释变量3}"')) ///
(m_y4, rename(x = `"{`zh1' 被解释变量4}"')) ///
(m_y5, rename(x = `"{`zh1' 被解释变量5}"')) ///
(m_y6, rename(x = `"{`zh1' 被解释变量6}"')), ///
keep(x) ///
drop(_cons) ///
horizontal ///
xline(0, lcolor(red) lpattern(solid) lwidth(vthin)) ///
xlabel(-0.15(0.05)0.15, labsize(medium) grid glcolor(gs12) format(%4.2f)) ///
ylabel( ///
1 `"{`zh1'变量一}"' ///
2 `"{`zh1'变量二}"' ///
3 `"{`zh1'变量三}"' ///
4 `"{`zh1'变量四}"' ///
5 `"{`zh1'变量五}"' ///
6 `"{`zh1'变量六}"', ///
labsize(medium) nogrid) ///
ytitle("", margin(small)) ///
xtitle(`"{`en1' (a)}{`zh1' 系数可视化}"', size(medium) margin(medium)) ///
title(`"{`zh1' 模拟数据中}{`en1' x}{`zh1'与六个}{`en1' y}{`zh1'的回归系数}"', size(medium)) ///
legend(off) ///
scheme(stcolor) ///
recast(scatter) ///
ciopts(recast(rcap) lcolor(black) lwidth(vthin)) ///
graphregion(color(white) lcolor(black) lwidth(vthin)) ///
plotregion(lcolor(black) lwidth(vthin))
|
 如图,这种图常常在外生性检验、异质性检验中被用到
如图,这种图常常在外生性检验、异质性检验中被用到
图中这种可视化检验也在变得越来越常见。例如一个城市政策(01 二元变量)是否是外生冲击的呢?就使用城市 gdp、城市人口、城市经济增速这些相对于研究外生且代表城市特征的变量对政策选择回归。此时回归系数的理论含义就是试点与非试点的平均差异,不显著则说明差异不大,一定程度上检验政策实施具有外生性。
中英文混排还有个问题就是 times 字体会偏高一些(例如图中标题的 x、y、(a)), 因此最好避免在标题使用中英文混排。
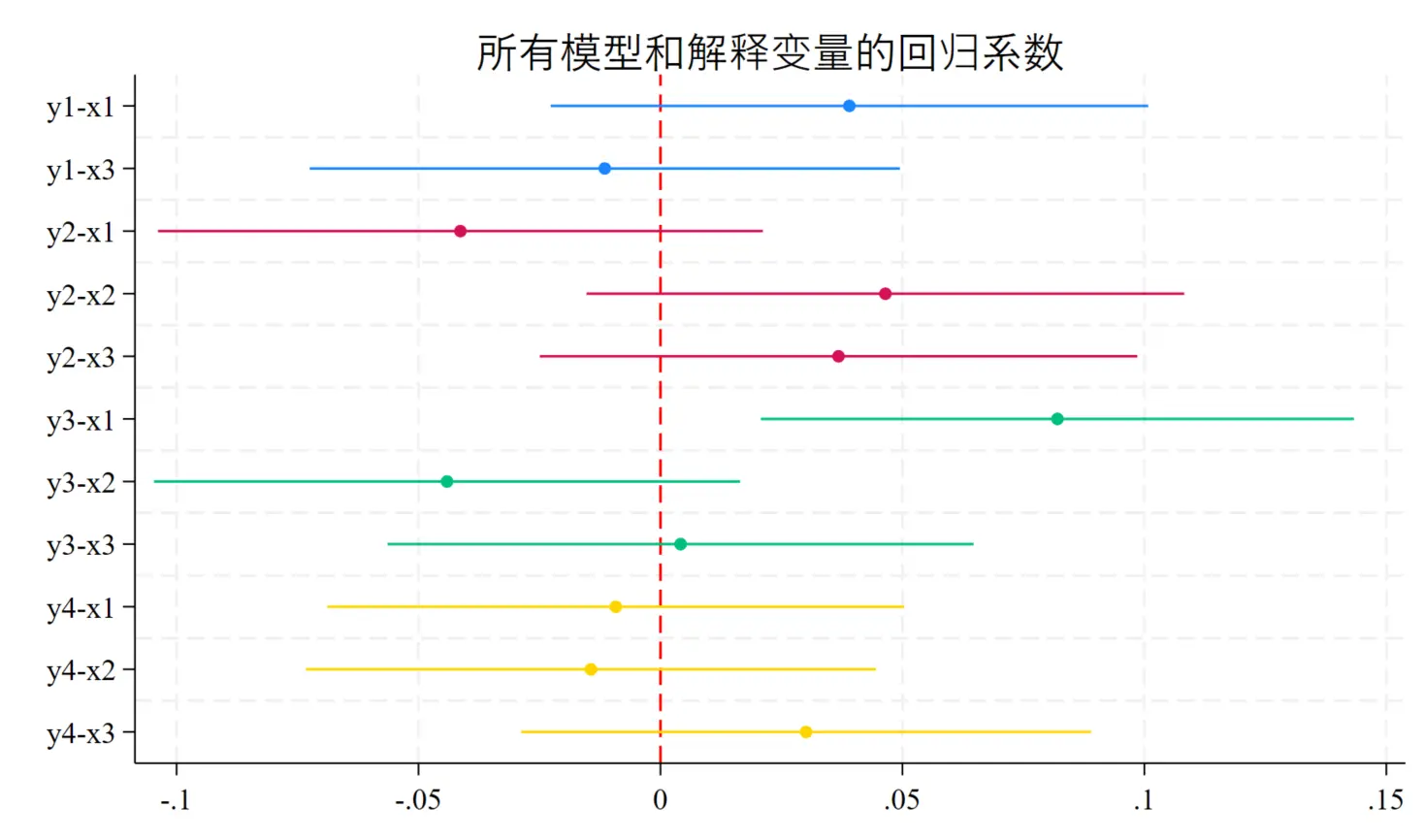
如果想要在多个回归,展示不同系数项,使用 keep 命令限制相关系数即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
clear
set obs 1000
set seed 20250707
* 生成解释变量 x1-x3
forvalues i = 1/3 {
gen x`i' = rnormal(0, 1)
}
* 生成被解释变量 y1-y4,系数随机接近0
gen y1 = 0.01*x1 - 0.02*x2 + 0.015*x3 + rnormal(0,1)
gen y2 = -0.005*x1 + 0.012*x2 + 0.008*x3 + rnormal(0,1)
gen y3 = 0.02*x1 - 0.01*x2 + 0.00*x3 + rnormal(0,1)
gen y4 = -0.015*x1 + 0.01*x2 - 0.005*x3 + rnormal(0,1)
local ys y1 y2 y3 y4
local xs x1 x2 x3
foreach y of local ys {
reg `y' `xs'
estimates store m_`y'
}
*keep 子命令可以保留每个回归想要展示的系数项
coefplot ///
(m_y1, keep(x1 x3) rename(x1="y1-x1" x3="y1-x3")) ///
(m_y2, rename(x1 = "y2-x1" x2 = "y2-x2" x3 = "y2-x3")) ///
(m_y3, rename(x1 = "y3-x1" x2 = "y3-x2" x3 = "y3-x3")) ///
(m_y4, rename(x1 = "y4-x1" x2 = "y4-x2" x3 = "y4-x3")), ///
drop(_cons) ///
horizontal ///
xline(0, lcolor(red)) ///
title("所有模型和解释变量的回归系数") ///
legend(off)
|
keep子命令可以保留每个回归想要展示的系数项
关于 coefplot 命令在事件研究法中的应用可参见“ 平行趋势检验的两种方式”。
顺便一提, coefplot 命令是 Ben Jann 教授开发的,他还开发了一系列很火的命令包。
Ben Jann 教授开发的其他包
额外讨论:不同学科绘图差异?
我的室友是电子信息专业的,每次看到我的回归图片都会觉得发论文,图像怎能这么简洁? 不过确实如此,比起生物统计、信息统计、卫生统计各种花里胡哨的图片,经济学最复杂的图片除去 GIS 之外,或许就是事件研究图的系数可视化了,剩余的都是大片表格。
这也能审美内卷?
不过,似乎有这样一个趋势——回归系数可视化正在变的越来越常见。
再来看看发表在 nature、science 的经济学文章。我的很多老师吐槽这些论文是发不了经济学领域顶刊的,却能发在 nature 和 science 上——这是不是意味着经济学科的崩坏?我个人觉得就是吃了学科交叉的空子,环境资源经济学尤其容易获得这种红利。
这些论文的图片风格也完全不同,更贴近理工科的绘图风格与分析范式。
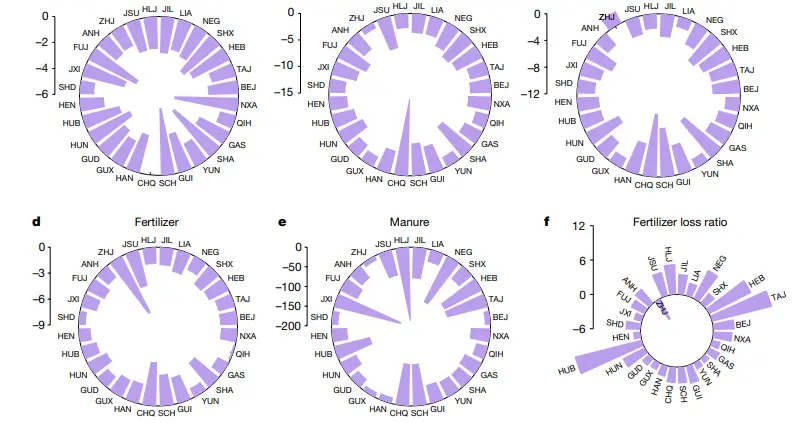
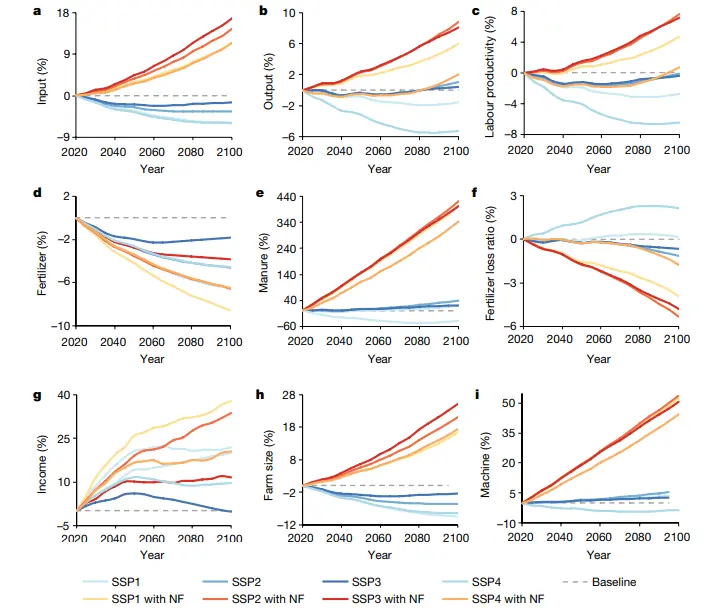
例子:发表在 nature 的《 Ageing threatens sustainability of smallholder farming in China》。
本文基于面板模型,利用中国 3 万多户农村家庭的调查数据,探讨了农村人口老龄化(家庭层面 65 岁以上人口比例)与农业可持续性之间的关系。总共选取了九个指标来说明农业可持续性,包括农场规模、农民教育程度、劳动生产率、农业总投入和产出、成本利润率、机械投入、化肥投入和肥料使用效率(FUE)。
如图,发表在nature的《 Ageing threatens sustainability of smallholder farming in China》
如图,发表在nature的《 Ageing threatens sustainability of smallholder farming in China》
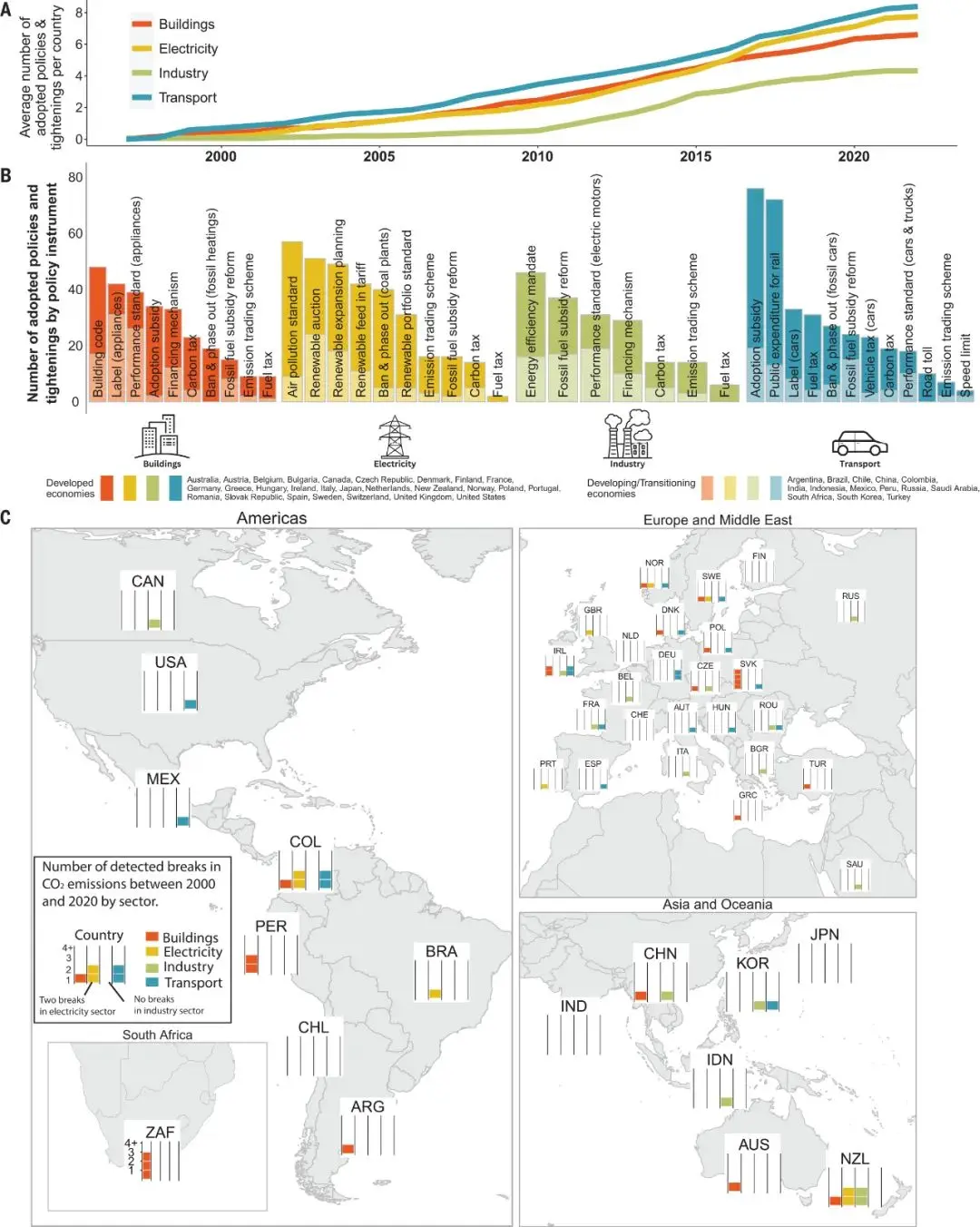
例子 2:发表在 science 的《Climate policies that achieved major emissionrecuctions: Global evidence from two decades》
(类似的中国环境经济学的在上面的还有不少)
本文通过全球性的系统性事后评估,以确定在 1998 年至 2022 年期间在六大洲 41 个国家实施的 1500 项气候政策中实现大幅减排的政策组合。我们的方法将全面的气候政策数据库与基于机器学习的常见双重差分方法的扩展相结合。我们确定了 63 项成功的政策干预措施,总减排量在 6 亿至 18 亿公吨 CO2 之间。我们对有效但很少被研究的政策组合的见解强调了基于价格的工具在精心设计的政策组合中的重要作用,以及缩小排放差距所需的政策努力。
如图,发表在 science 的《Climate policies that achieved major emissionrecuctions: Global evidence from two decades》