
The Copernican Moment and Academic Taste

When we talk about what AI can do, we are really circling back to an older question: what, exactly, is irreducibly human about research?
A refrain that keeps getting louder in academia goes something like this: now that AI has become a research assistant, academic taste will matter more than ever. I find that phrase — “academic taste” — deeply contradictory.
- On one hand, it is maddeningly vague. It runs against everything research is supposed to be: making things clear, making things precise, making things accessible.
- On the other, that very vagueness, while it can encode genuine practical wisdom, slips all too easily into survivor bias and the kind of condescension that comes wrapped in institutional identity.
A recent conversation between Terence Tao and the YouTuber Dwarkesh Patel gave me a fresh angle on this. Maybe what we casually call “academic taste” really is a phantom category — just one that operates at different levels.
- Macro level: How is truth actually discovered?
- Micro level: Which theories get picked up, propagated, and funded first?
At the macro level, academic taste has nothing to do with where truth comes from. At the micro level, taste is real enough — but it functions less as a faculty of judgment and more as in-group shorthand.
- Original interview: Terence Tao – How the world’s top mathematician uses AI
- Chinese summaries: 量子位, 网易, 51CTO.
Revisiting the “Copernican Moment”
Strictly speaking, the “Copernican moment” I am talking about here belongs more to Kepler — the one who actually corrected the model of planetary motion.
Copernicus proposed heliocentrism, sure. But he never let go of perfect circles.
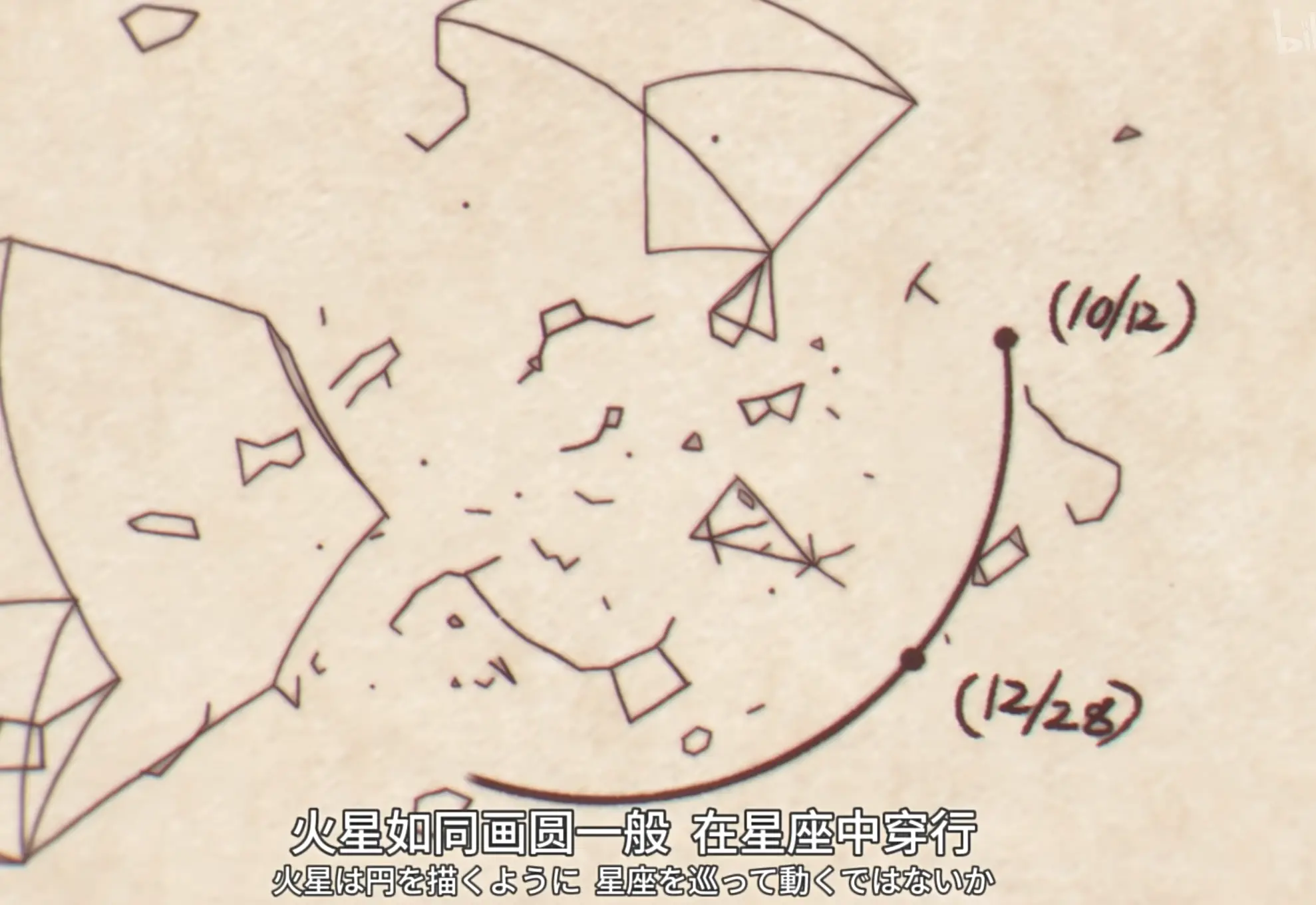
Kepler, for a long time, believed planetary orbits had to conform to some deeply harmonious geometric structure — Platonic solids, even. What he lacked was a high-quality observational dataset. So he got one from Tycho Brahe.
The planets do not move in circles. They do not trace out regular polyhedra. Kepler spent years trying everything: shifting the circle’s center, tweaking parameters, searching for a fit that would not come. What finally broke the impasse was data: the ellipse was the shape that worked.
Translated into the language of modern empirical science, the process looks like this:
- High-quality data: Tycho’s long-run observational records.
- Model assumptions: circular orbits, geometric harmony, and other prior commitments.
- Residual analysis: the model could not account for a crucial deviation in Mars’s orbit.
- Iterative revision: shifting circles, adjusting parameters, trying new geometries.
- Abandoning the old assumption: accepting that “the circle” itself might be wrong.
- Abstracting a new law: elliptical orbits, and eventually the general laws of planetary motion.
The history of science tends to magnify the “moment of discovery” while shrinking the long, grinding stretch of failure, trial, and data accumulation that came before it. In that light, the macro-level pursuit of truth is less about “a person of taste seeing through to the essence at a glance” and more about who has better data, who can afford a longer chain of failed attempts, and who is willing to delete an old assumption — until the truth finally comes into view.
Taste and the cost of trial and error
Why does academia keep invoking taste and intuition? Strip away the mystique, and they serve a single function: lowering the cost of trial and error.
Every day, scientists face an infinite space of theoretical conjectures and a finite budget of attention. Peer review exists to filter that space into something more tractable. But in a world shaped by data-driven methods and AI, the cost of verification is racing toward zero. That shifts the advantage toward whoever can:
- marshal higher-quality data;
- expose the weaknesses of old models faster;
- admit that a cherished assumption is wrong;
- hold onto something rough but right through a long sequence of failures.
This naturally calls to mind that perennial question in the social sciences: why didn’t the Industrial Revolution happen in China (or Asia more broadly)? The question travels under different names in different fields — the Needham Question, the Weber Thesis, the Great Divergence, the Qian Xuesen Question —
Justin Yifu Lin’s classic answer runs like this: science, at bottom, raises productivity. China had abundant labor and scarce capital; Europe had the reverse. Europe therefore had incentives to invest in science, while China developed the imperial examination system. China’s early growth came from empirical know-how accumulated at population scale. The Industrial Revolution needed something else: an institutional environment that steered elites toward scientific enterprise.
A sharper follow-up: was the Industrial Revolution driven by the masses or by elites? In the long arc of history, it is tempting to see it as a dialectical wave of its time — yet spatial inequality hints that the story is not so tidy. If we suppose that scientific development has bottleneck phases, could that be where AI and the Industrial Revolution share a theoretical logic? There seems to be an inverted-U relationship between trial-and-error cost and population quality:
When the cost of trial and error is low, volume and breadth of attempts matter most. When the cost of trial and error is high, elite selection and intensive training matter most. And when AI starts driving down the cognitive cost of certain kinds of trial and error, the filtering structures that once relied on the “taste” of a small number of people may begin to crack. What is really changing at the macro level is not that truth has suddenly become a matter of taste — it is that the organizational form through which we approach truth, through trial and error, is transforming.
Taste and selection mechanisms
The uncomfortable fact is that scientists do not live inside macro-history. They live inside today: inside deadlines, inside grant cycles, inside peer review.1
Liu Cixin wrote a beautiful metaphor for this in his short story “The Poetry Cloud.” An advanced alien civilization brute-forces every possible combination of Chinese characters — and still cannot tell which poem will, in some future age, truly surpass Li Bai. The problem is not just can it be generated. It is also which one should be believed.
The world of theory is the same. We can rarely tell, in the present, which theory will matter later — because a theory’s value is never just about whether it looks elegant, mature, or complete right now. It also depends on whether it turns out, in the future, to carry more explanatory power.
The history of economic thought is full of such cases. Many contemporaries could not accept Augustin Cournot’s use of mathematics in Researches into the Mathematical Principles of the Theory of Wealth to express the price–demand relationship. Ramsey touched on the endogenization of the savings rate long before the Solow growth model, but his insight only became visible inside a later theoretical frame. In these examples, “taste” starts to look more like:
- sensitivity to the questions of one’s own time;
- a rough, pre-theoretical hunch about a theory’s future explanatory reach;
- tolerance for the gap between “roughly right” and “elegantly wrong.”
Roughly right and elegantly wrong
Terence Tao put this wonderfully:
Science is always advancing. When you only have a partial answer, it can look worse than a theory that is wrong but has been refined to the point where it seems to answer everything. Newton’s theory was full of puzzles — puzzles that took centuries to resolve, and only through a conceptually different approach. Progress often comes not from adding more theory but from deleting an assumption you have been carrying in your head.
This passage explains, almost exactly, why “taste” keeps getting invoked at the micro level.
Because researchers, in practice, are constantly staring at two kinds of things:
- a very polished wrong theory;
- a very rough right theory.
Seen from the endpoint of history, time may eventually vindicate the right theory. But seen from the middle of a career — with its disciplinary divisions, its resource constraints, its professional incentives — researchers have to choose before the evidence is complete. Taste, then, is not some sacred faculty. It is the capacity to place a bet.
Taste and narrative
If all you see is “more data, stronger models,” it is easy to drift into the illusion that theoretical competition will eventually collapse into a pure data race.
Tao pushes back:
The art of exposition, the organization of arguments, the construction of a narrative — these are also essential parts of science. Data helps, of course. But people need to be persuaded, or they will not invest in moving a direction forward. They need to make that initial investment to learn your theory and really explore it.
This gets at something real about the micro level: science is not only a process of discovery; it is also a process of organization.
Data does not persuade on its own. A theory can be, in some sense, closer to the truth — and still need to be explained, transmitted, learned, put into curricula, written into papers, and funded for further exploration. Even in empirical economics, a p-value is just one check among many necessary conditions;2 what we really need to convince others of is why the combination of those conditions is credible enough. See “The Rhetoric of Economics” and “Empirical Economics: Intuitive ≠ Obvious.”
Take a single topic — say, the idea that long-term AI use erodes cognitive ability (or skills, or attention). You can find versions of this same question across statistics, economics, life sciences, and medicine. Different methods, different narrative angles. Some people manage to wrap it into a top-tier publication; others end up in a low-tier journal. The gap between them is bigger than anything the word “taste” can capture.
Academic taste at the macro level carries a built-in contradiction. The spirit of science we absorb growing up is that behind any seemingly trivial phenomenon lies a deep mystery. Taste, meanwhile, is easily co-opted into something cruder: the impulse to dismiss an entire line of inquiry as simply boring.
At the micro level, “taste” takes on an unmistakably communal flavor. It is not just individual judgment. It is club culture inside a discipline: which questions are worth asking, which evidence counts as decisive, which style of expression reads as serious, which assumptions feel “natural” — none of these are purely personal decisions.
In that club setting, academic taste is less about a topic being boring or uninteresting. It is more about the research being out of step with the group.
To sharpen the point: for a labor economist, gender may be a fundamental dimension for analyzing social structure. A sociologist working on LGBT issues may not accept the same framing at all. A new structural economist may treat endowments as the primary constraint; an institutional economist will push back hard. The disagreement here is not simply about who is “more right.” It is about which community prioritizes what, how they organize questions, and how they allocate attention.
So yes — at the micro level, “academic taste” exists. But it functions mostly as club vocabulary.3
AI and the question
At the macro level, taste is an empty word. Wrong theories can be exquisitely polished; right theories can be embarrassingly rough. Taste has never had anything to do with truth — because even with peer review as refined as it is today, important research does not automatically rise to the top.
At the micro level, taste is genuinely consequential. No researcher can wait for “the verdict of history” before deciding what to read today, what to work on, what to submit, what to teach. Finite resources force every community to develop its own pre-filtering rules — and “taste” is often just the everyday name for those rules.
That is why the change AI brings is not “academic taste matters more” or “academic taste no longer matters.” A more precise way to put it might be:
- The technical cost of trial and error is falling. AI can help generate candidate ideas, search the literature, check derivations, and further compress low-level labor.
- The social cost of verification has not gone away. Data quality, theoretical interpretability, peer persuasion, training barriers, institutional incentives — AI does not reach any of these.
- The carrier of taste is shifting. It used to be embodied disproportionately in the individual judgment of a small number of experts. Now it is increasingly embedded in datasets, citation networks, model weights, recommendation systems, and community feedback loops.
Consider how canonical literature used to form: an author reads papers, cites them, and gets discovered by others through search. Now people may ask an AI to recommend papers, or have an AI read them. Should we expect that, going forward, papers in formats more legible to AI — those shipping with code libraries, Markdown documentation, reproducible GitHub repositories — will carry more weight? The real-world influence of literature and its AI-mediated influence may split into two interlocking but distinct systems.
Academic taste is not a shortcut to truth. At the macro level, truth is not decided by taste. At the micro level, taste remains a survival strategy under finite resources. What AI is changing is not the pursuit of truth itself, but the way truth is discovered, filtered, propagated, and invested in.
Maybe that, more than anything, is the Copernican moment we are actually living through.
Further reading
- Teaching Econometrics in the Age of AI
- Some Thoughts on AI and Research
- The Consequences of Abundant Intelligence
- Can Mathematical Taste Be Quantified?
- If the Primary Audience for Papers Is No Longer Human
- Does Scientific Progress Depend on “Outliving” the Old Guard? A Science Study Reveals Academia’s Brutal Truth
-
Keynes: in the long run, we are all dead. ↩︎
-
A fun philosophical experiment: can statistical evidence serve directly as legal evidence? What exactly is the difference between how mathematical models and probabilistic models “prove” something? ↩︎
-
At the very least, my own feeling is that evaluating whether a question is worth studying requires a certain humility — a posture of restraint. ↩︎