
计量:事件研究法 1

做过 DID 的必然对平行趋势检验不陌生。而平行趋势检验就是事件研究法的一种特殊运用。
最近老师让阅读学习论文《An Introductory Guide to Event Study Models》。
作者们也发过一个油管系列视频。 本文将基于这篇论文框架记录个人感悟。
代码还没有细看,这里先放上统计理论理解。
经济学如何研究事件冲击?
事件研究法就是研究特定事件是否对研究对象产生了影响 。这种方法最先在金融领域得到应用。例如分析公司改名,公司丑闻爆发,公司信息披露对股票波动的影响1。
这种方法当然需要更严谨地统计分析——例如某乎动不动就出现以下形式的问题:
政策实施 or 发布会后,苹果 or 英伟达公司股价第二天就蒸发 or 暴涨几十亿,原因是什么?
这种分析就是事件研究法的起点,但统计学上的检验还需要更严谨些。
被引入到计量经济学中,事件研究法主要用于研究动态处理效应。通过处理效应的时间分组切片,进一步讨论事件影响。
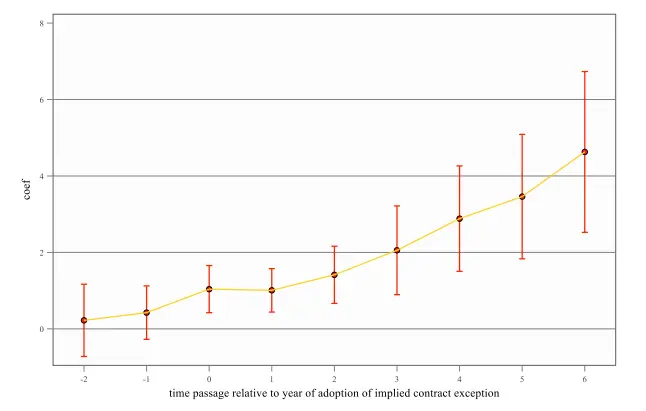
例如下图研究失业对收入2的影响中,根据每个人失业时间建立动态的时间虚拟变量:失业前一年(t-1)、失业后一年(t+1)、失业后两年(t+2)。其中包含了预期趋势和事后趋势。
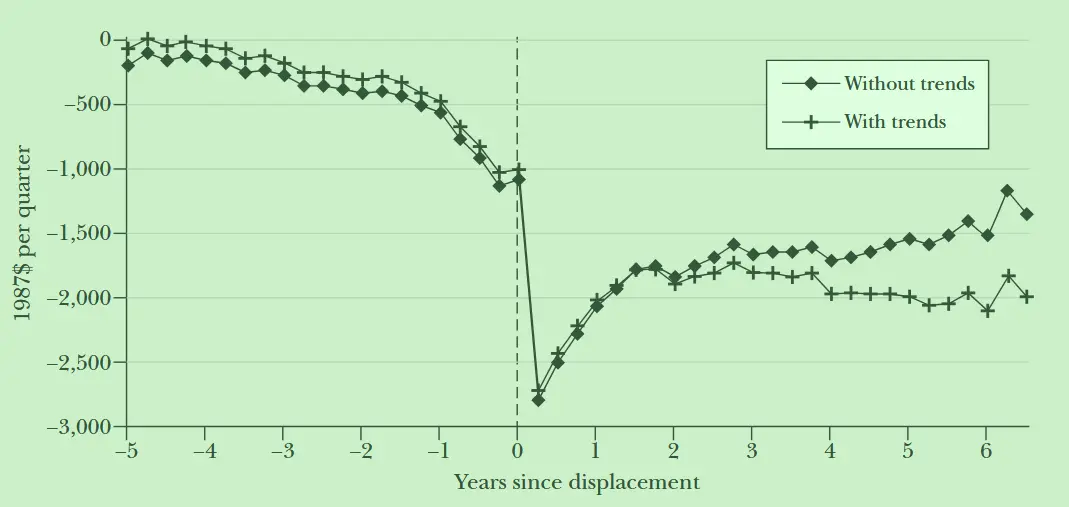
- 事前趋势:例如大家都预期失业潮要来了,在事件到来之前,可以看出就有缓慢下降的趋势,但在时间出现那一刻(横坐标为 0)的前后,冲击效果依旧明显。
- 事后趋势:随着时间冲击后,效应开始逐渐反弹。也就是比较时间冲击后每年都效果是逐年增强还是减弱。
- 模型假设:DID 中的平行趋势检验也是事件研究法。证明政策满足模型假设——外生冲击。因此,在政策开始前,处理效应应该不显著且系数接近 0,政策开始后,系数显著异于 0。
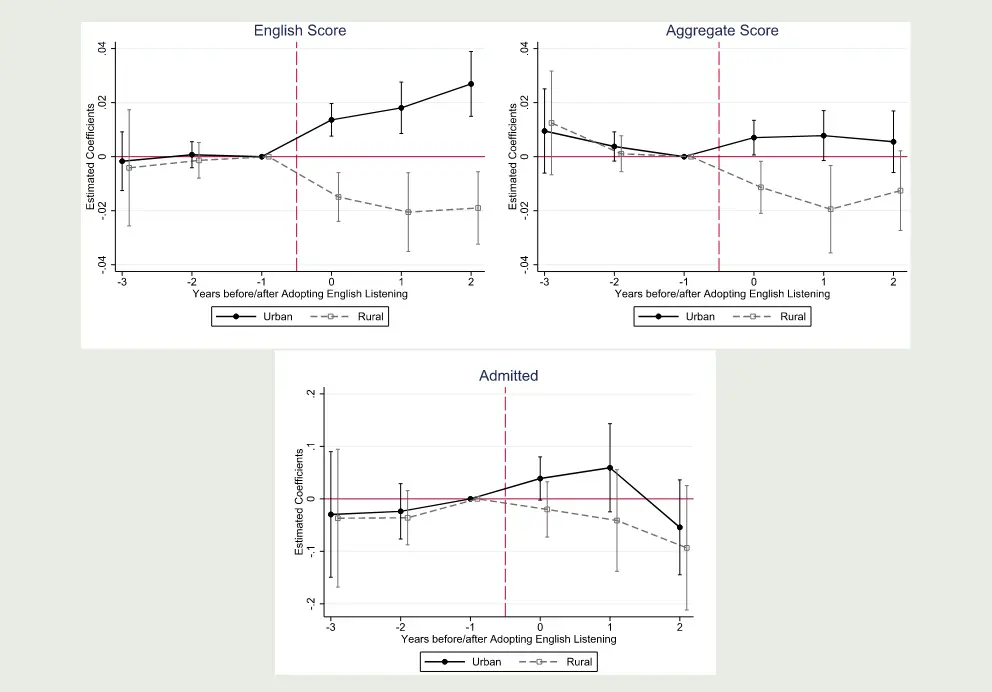
以英语听力考试与教育不平等3的一个论文为例子。
论文设置的时间虚拟变量是英语听力何时加入高考。
被解释变量:英语成绩、数学语文成绩、录取率。 异质性分组:城市和农村样本。
通过图也可以看出,在引入英语听力前,城乡差距不大,引入后城乡水平差距不断扩大。

英语听力考试与教育不平等
事件研究法的“亿”点细节
回归估计式
在计量经济学中,事件研究法就是估计动态处理效应——对回归进行时间切片。
以面板数据为例,特点是加入了事件时间虚拟变量 $D_{i, t-j}$ 。
$$ y_{ii}=\underbrace{\left(\sum_{j\in{-m,\ldots,0,\ldots,n}}\gamma_{j}\cdot D_{i,t-j}\right)}_{\text{事件时间虚拟变量}}+\underbrace{\alpha_{i}+\delta_{i}}_{\text{面板固定效应}}+\underbrace{\beta\cdot X_{ii}}_{\text{ 控制变量}}+\epsilon_{ii}. $$
数据结构分类
《An introductory guide to event study models》4给出了两种分类依据:
- 是否有“从未经历处理”的样本组?
- 不同样本组的受到处理的事件日期是否存在较大差异?
| 分组 | 没有“从未经历处理”的样本 | 有“从未经历处理”的样本 |
|---|---|---|
| 事件日期相同 | N/A | DID-type |
| 事件日期不同 | Timing-based | Hybrid |
省流总结一下——
-
N/A:没有对照组,处理效应根本不能估计。
-
DiD-type:完美的对照实验,传统 DID。
-
Timing-based:虽然都是实验组,但是实验组的事件冲击有差异,也可以做对照实验。
以易地搬迁的一个面板数据研究为例子5。人大这个易地搬迁数据库长期在易地搬迁安置点做问卷调查,所以他们的研究其实是 ITT ——所有样本都是经历了易地搬迁政策的实验组。
但是!易地搬迁是分批执行的,也就是有人先搬出去,有人后搬出去,于是同样的年份,也存在搬了的实验组和没有搬走的对照组,因此还是可以做。
顺便一提,本文的结论是居住环境变好了,打工人就不想离开家了。所以文章题目叫《甜蜜陷阱(Home sweet home)》
- Hybrid: 既有实验组和对照组的对比,又有同样年份实验组内部的对比。
事件时间的选择
实验研究法的整体逻辑为:
选择 事件和发生时间,选择 事件基期,选择 窗口期(动态处理效应范围),选择 实验组和对照组,计算和分解 平均处理效应。
事件发生时间的选择 :
即便一个政策在全国某个具体时间统一普及,可能市场会提前做出反应;更何况,大部分事后,事件的冲击是不均匀的,分群体、分载体、分时间、分空间地慢慢波及出去。不过经济学统计也就只是有啥,就选个最好的就行。
以研究 Facebook 对大学生心理健康的一个研究为例子6每个人何时开始使用 Facebook 显然难以获取数据,这个研究就使用大学生个体心理问卷,和 Facebook 展开校园合作的校园时间匹配到一起回归。
顺便一提研究结果:社交媒体的使用加剧了大学生的心理不健康。渠道测试显示是攀比焦虑导致的。
事件基期的相关处理
补充计量中虚拟变量(dummy)的知识点:
为了避免共线性——使用 n-1 个虚拟变量估计 n 个变量间的相对差距。 例如比较空气污染的春夏秋冬周期水平。 这种处理效应的估计需要一个基期作为对照。 我们可以默认春天为基期, 那么夏、秋、冬的系数估计其实都是和春天数据比较出的结果。
时间研究法的的时间虚拟变量也需要设置一个基期,于是有了以下选择或处理:
- 绝对基期:一般选择事件发生的前一期 (对比效果更好些,能突出跳跃性):能反映长期差距,事前期数较多时用。
- 相对基期:相对前一期位置作为基期:关注预期效应,或者事前期数较少时用。
- 期数合并:目的是处理共线性问题。例如把 t-6 及其以前的合并为一期,把 t+5 及其以后的合并为一期。或者删除某一期。
- 基期处理:归一化,设为 0……
- 时间趋势:是否添加时间趋势、个体固定效应、时间固定效应。
- 事件端点:端点可能偏移而不好看,也可能反映了事件趋势。
《An introductory guide to event study models》中提到考虑到事件虚拟变量的设置可能会影响分析结果,这里应该加强虚拟变量的设置和限制描述。
但就我最近读的 top5 论文而言,似乎事件研究法主要用于直观地展现异质性差异、模型外生冲击假设。所以这方面的描述基本都是一带而过,只说了怎么设置,而不强调为何要这么设置。
窗口期选择
窗口期的选择,本质就是结果美观和统计偏差的平衡。
- 太短统计有偏差,太长反事实估计不够有效。
- 从实用主义的角度来说🤪——让回归结果体现一种趋势是最好的。
- 事前和事后窗口期对称是最好的。
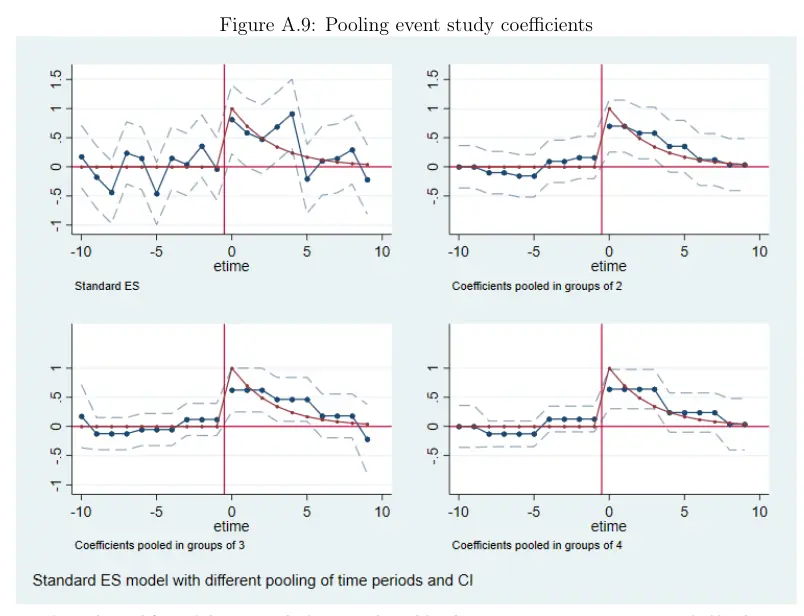
- 可以进一步拟合,例如先按月份估计动态变化,再按季节进行加权,从而反映一种趋势变化。多事件的加权拟合也是一样的方法。
二次加权拟合,更能反映一种趋势变化
实验组和对对照组的选择
- 排除特殊样本。例如中国城市数据,我们往往会排除直辖市,因为他们太特殊了!而在异质性部分,一般会看下省会城市和非省会城市的区别。
- 注重平行趋势检验。也就是事件冲击前,实验组和对照组越像越好。
- 加入控制变量。
- 加权匹配。例如合成控制法和倾向匹配法。
- 如果一个事件研究具有 Hybrid 数据结构,可以选择剔除未被处理组的数据。
- 论文作者也推荐把系数标准化。
一个有趣的问题:控制变量和倾向匹配有什么区别?在我个人看来,一个是后门控制,通过因果路径估计;一个是前门控制,通过样本匹配加强对照。
趋势的干扰问题
趋势分解这部分太复杂,不能完全看懂,就大致说说了
需要考虑以下两个方面的趋势问题:
- 个体趋势和时间趋势如果不控制,处理效应的估计就会有偏差。
- 处理效应本身也会随时间变化而变化,需要加以分解。
论文有关讲解中举例的一些趋势变化
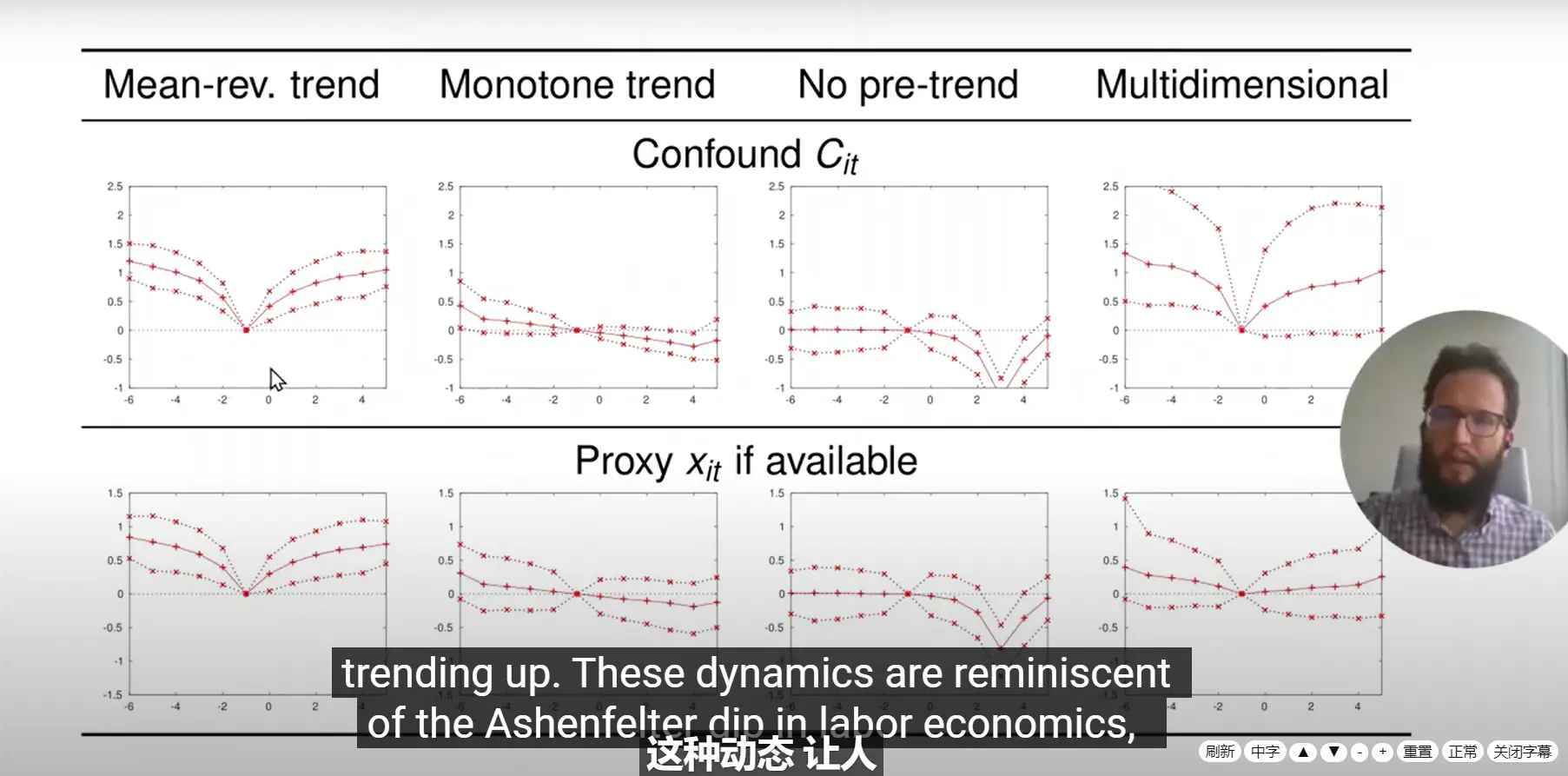
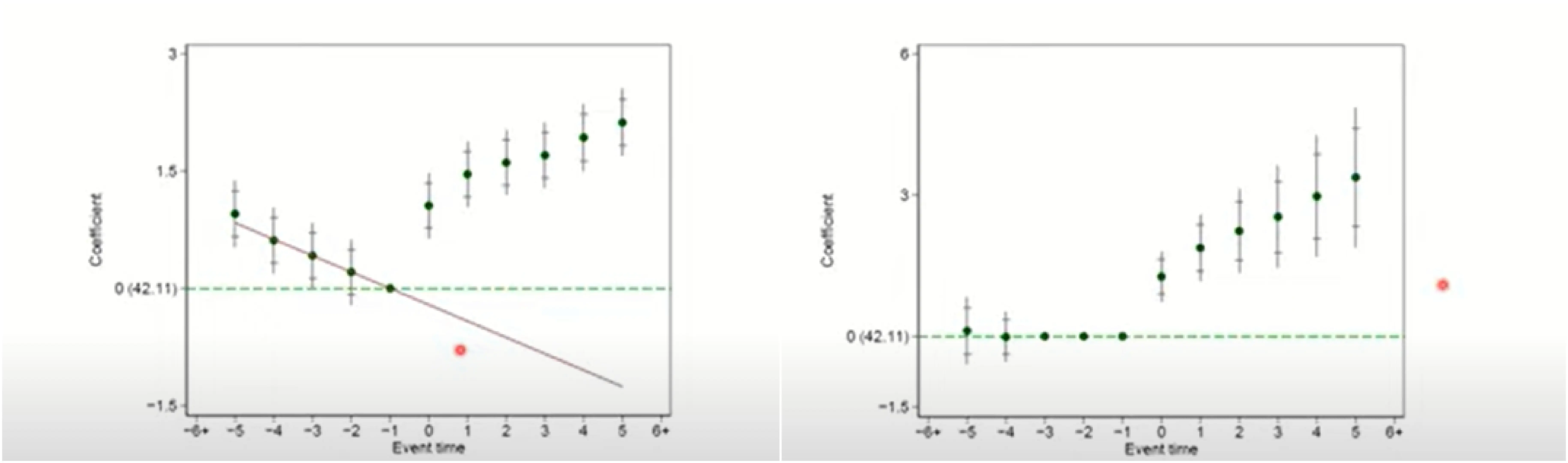
1、一些情况下,由于事件时间、日历时间和个体固定效应存在多重共线性,因此不可能在处理线性趋势。除非估计成非线性估计。
对于趋势的估计,个人确实感触颇深,其实有一些很巧妙的思路来分解,例如《生命周期与工资分解 》。这里面的经济分析非常巧妙。即便是个体、时间、事件时间共线了,依旧能通过理论分解出来。当然,这种处理只能针对特定对象,非统计学数理通用方法。
2、可以设置一期为 0,进而讨论非线性趋势
3、一些具体的内生性。例如一些政策是分时间进行的。此时可能得到后处理的效应比先处理的效应大。但可能是因为个体随时间发育从而影响。因此,做社会调查数据库时,很多人也会设置问卷入库批次的固定效应。
4、加入时间趋势和个体虚拟变量的交互项。
5、Timing-based 的数据结构建议引入二次趋势变量,避免共线性。
6、加入时间趋势。时间固定效应分解的是截距,时间趋势估计分解的是斜率。
事件研究的推断统计
聚类检验的是自相关问题。哪个层级存在自相关就在哪个层级进行聚类。
可以参考计量数据的分组与测度(STATA 版)。
未来展望
1、测度强度可变的事件效应
时间虚拟变量和事件规模大小交互项。
个人感觉这种思路和差额移动法工具变量(shift-IV)比较类似。利用排除个体的组内趋势乘以个体规模作为工具变量。
2、每个单位有多个事件
进行加权,或者限定唯一——只计入最大的事件或者第一次出现的时间。
3、异质性处理
交互项,或者根据时间分组,例如较早受到影响的组和较晚受到影响的组。
通过反事实进一步估计。事件研究法由于固定效应和趋势没有估计到会产生偏差,文章使用了一种估计手段让其估计更准确(这里我没看懂)。
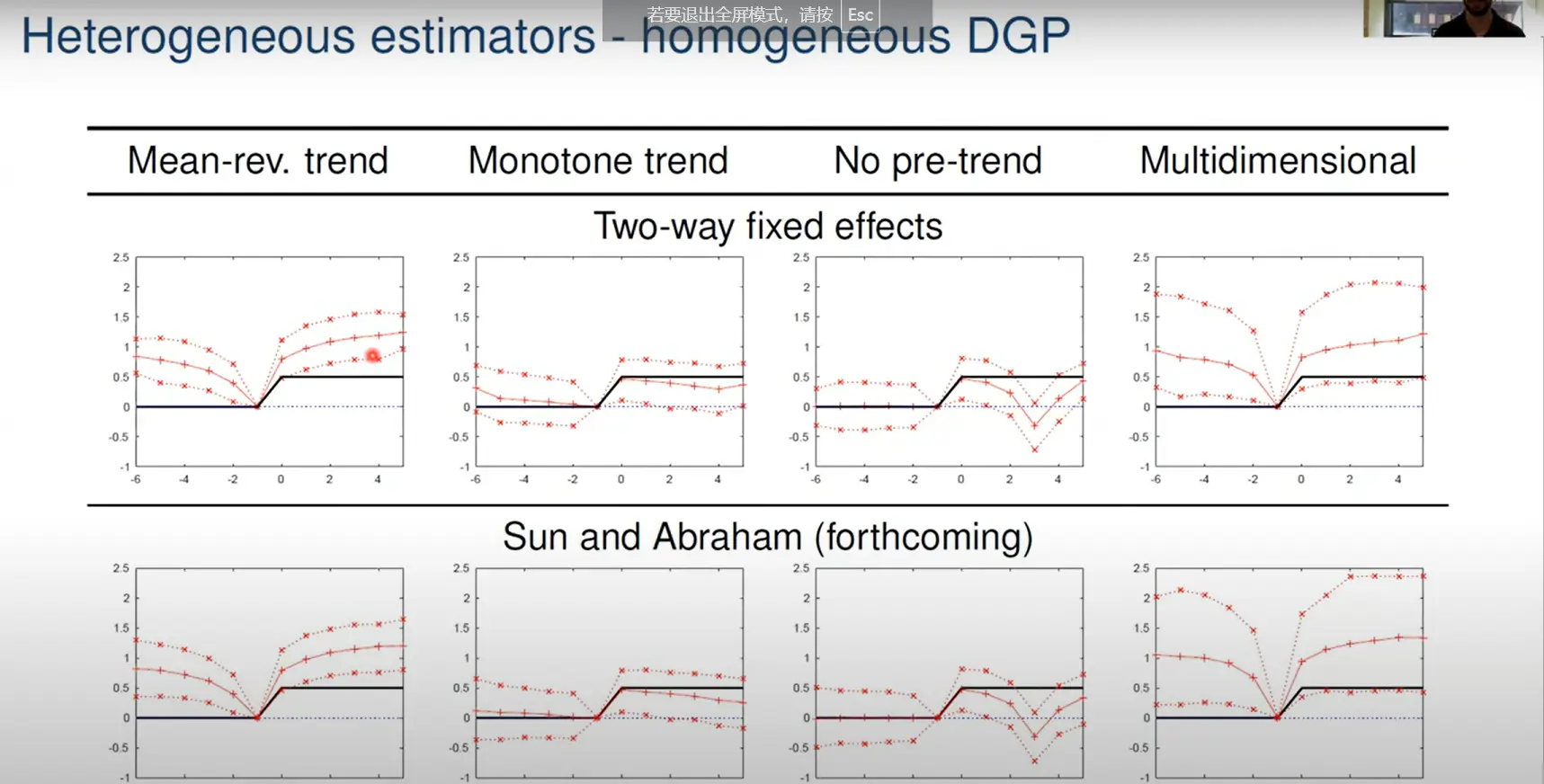
4、考虑非年份事件时间
例如队列效应。其实就是自定义时间虚拟变量分组。
5、状态转变
《An Introductory Guide to Event Study Models》虽然没有提到这点,个人觉得还有个可以展望的地方——广延边际和集约边际的分解。
请参考《Log (y+1) 的转化是否可靠》
省流总结
事件研究法本质估计的是动态处理效应。
为了估计准确,有以下建议:
- 系数标准化
- 选择合适的基期和事件窗
- 考虑个体效应、时间效应、时间趋势
- 考虑样本特性带来的混杂因子(采用论文提供的估计器)。
本文主要参考文献
- Stata:事件研究法的编程实现
- 从DID到事件研究(一):三幕剧构成一台戏
- Stata:一文读懂事件研究法Event Study
- An Introductory Guide to Event Study Models
- 许文立计量经济学讲义
- ES,启动!——事件研究法入门指南
- 【文献学习】事件研究法入门指南
-
很符合我对金融研究信息因子无情挖掘的刻板印象。 ↩︎
-
Jacobson L S, LaLonde R J, Sullivan D G. Earnings losses of displaced workers[J]. The American economic review, 1993: 685-709. ↩︎
-
Li H, Meng L, Mu K, et al. English language requirement and educational inequality: Evidence from 16 million college applicants in China[J]. Journal of Development Economics, 2024: 103271. ↩︎
-
Miller D L. An introductory guide to event study models[J]. Journal of Economic Perspectives, 2023, 37(2): 203-230. ↩︎
-
Qiu H, Hong J, Wang X, et al. Home sweet home: Impacts of living conditions on worker migration with evidence from randomized resettlement in China[J]. Journal of Economic Behavior & Organization, 2024, 220: 558-583. ↩︎
-
Braghieri L, Levy R, Makarin A. Social media and mental health[J]. American Economic Review, 2022, 112(11): 3660-3693. ↩︎